机器学习-各个指标含义
一些基本概念:
准确率(Accuracy)
精确率(Precision):又称查准率
召回率(Recall):又称为查全率
AP
mAP@.5
mAP@.5:95
Speed:inference/NMS/total 推理耗时/非极大值抑制耗时/总耗时
F值(F-Measure)
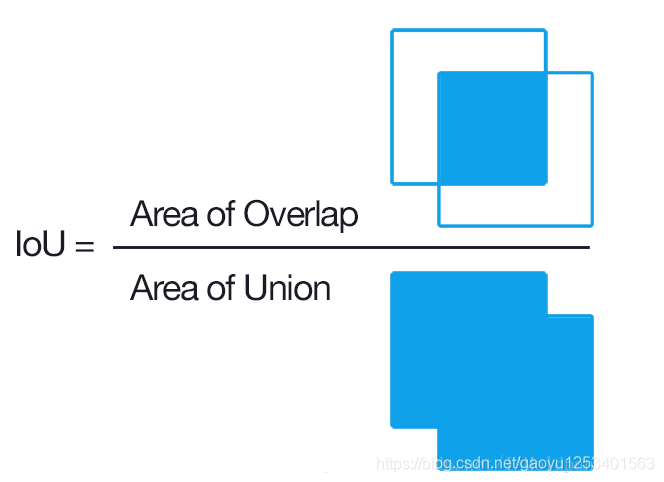
IoU
ROC曲线(ROC Curve)
PR曲线(PR Curve)
AUC
MAE、MSE
首先了解准确率,精确率,召回率
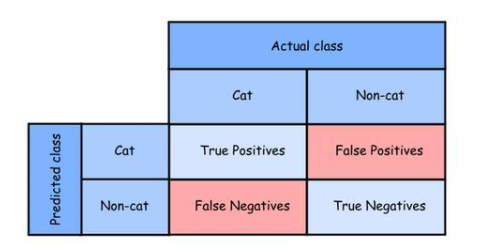

根据一张图片中是否包含猫,将分类器以Cat的和Non-cat形式表示
Tp(True Positive)表示预测的是Cat,并且实际类别就是Cat(真正,预测成功)
Tn(True Negative)表示预测不是Cat,并且实际类别也不是Cat(真负,预测成功)
Fp(False Positive)表示预测的是Cat,但实际类别不是Cat(假正,预测失败)
Fn(False Negative)表示预测不是Cat,但实际类别是Cat(假负,预测失败)
准确率(Accuracy):是预测对的结果占所有数据的比例,理想值越接近1越好。即(Tp + Tn)占所有的比例。(不管是不是猫,都被你猜对了的总数),要分清楚猫和狗

精确率(Precision):又称查准率,针对预测的结果而言,即预测为正的样本(Tp + Fp)中,有多少是真的正样本Tp,而那些Fp越少越好最好是0,显然这个值越接近1越好。(猜的这堆样本里,有多少真的是猫),不要让狗混进来

召回率(Recall):又称为查全率,针对原来的所有样本而言,即有多少正样本被预测正确了。那么分母为原来样本中所有正样本个数(Tp + Fn),那些预测为负的正样本Fn越少越好,即召回率R越接近1越好。(有多少只猫被你找回来了),不要让可怜的小猫在外流浪


- 普遍状态
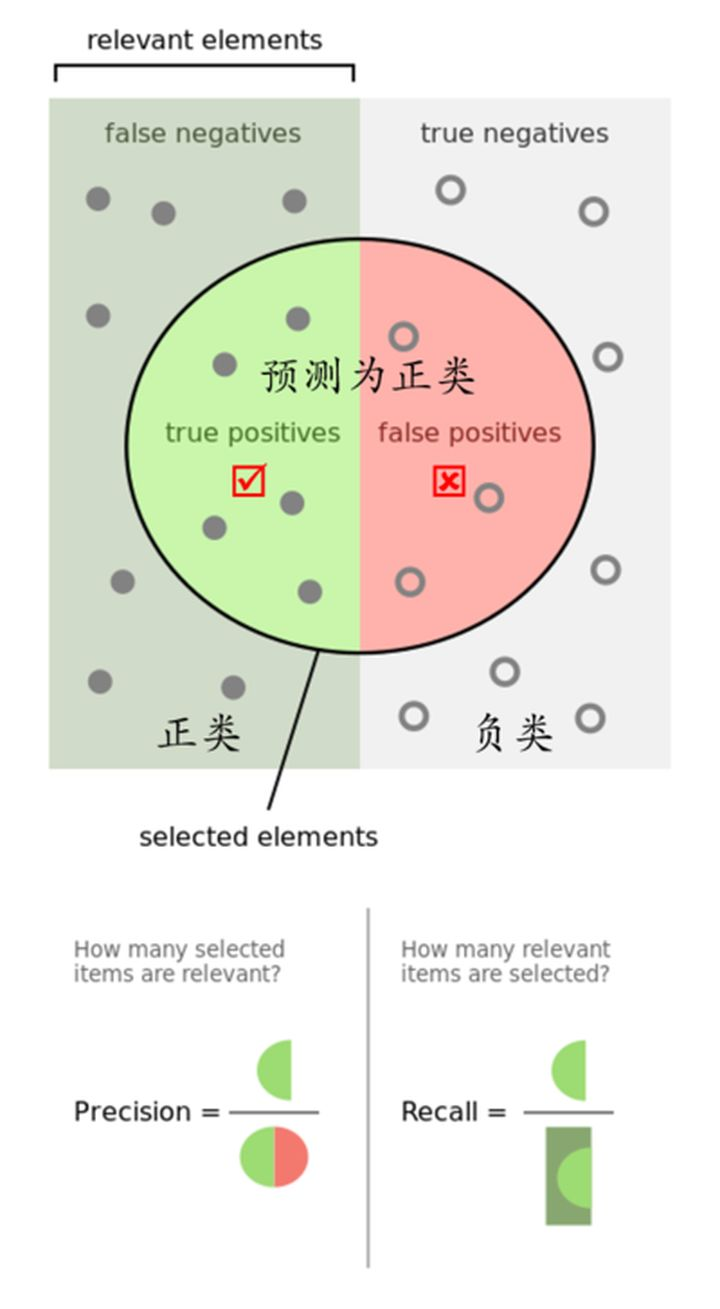

- 理想状态
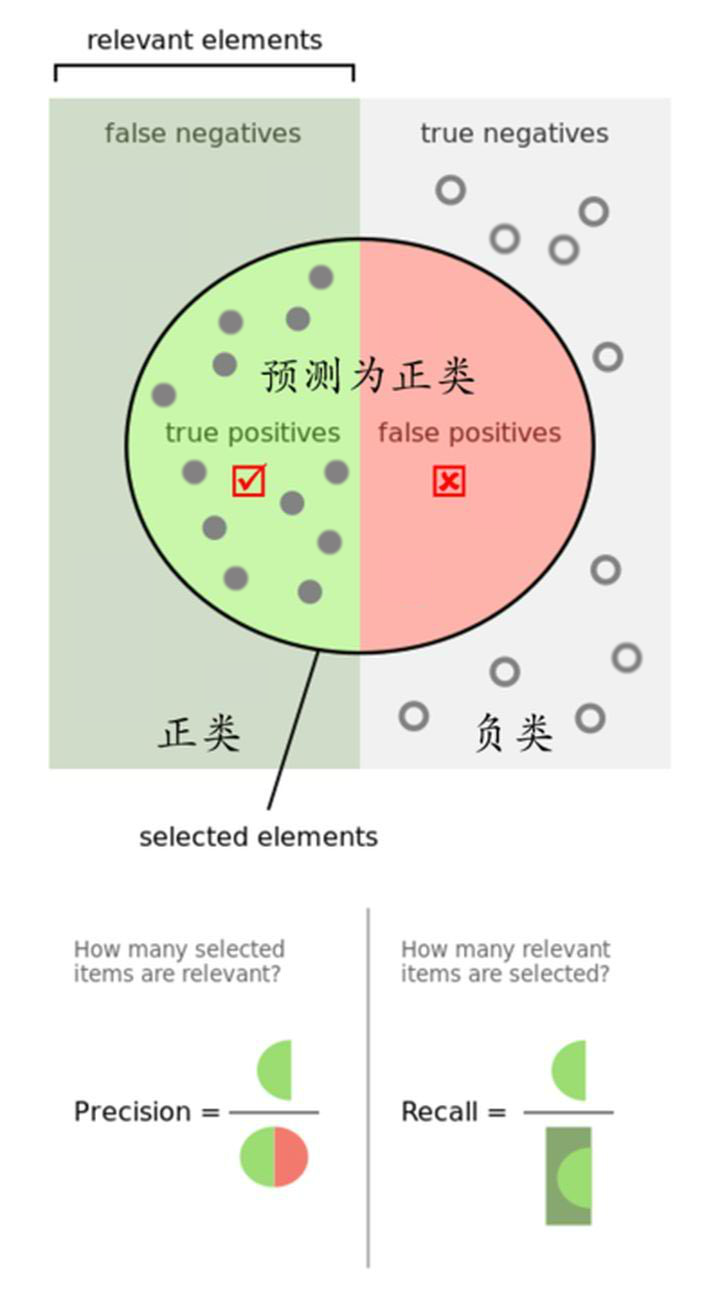
如上图1:
- 普遍状态,即Precision和Recall皆为0-1之间的值
- 精确率Precision为绿色半圆占整个圆的比例
- 召回率Recall为绿色半圆占左侧长方形的比例
如上图2:
- 理想状态,即Precision和Recall皆为1
- 如果圆形的右侧红色部分为0,则精确率Precision就会是1。
- 如果左侧半圆中的点能把正类长方形的所有点包含进去,那么Recall召回率就会是1。
F值
为了统一精确率(Precision)和召回率(Recall),我们用一个F值统一描述:

可以理解为即希望找到目标里不要包含狗,又希望尽可能多的把猫找出来。理想结果仍然是1
举个栗子
假设我们手上有60个正样本(Cat),40个负样本(Dog),我们要找出所有的正样本(Cat),系统查找出50个(包含Cat和Dog),其中只有40个是真正的正样本(Cat),计算上述各指标。
- TP: 将正类预测为正类数 40
- FN: 将正类预测为负类数 20
- FP: 将负类预测为正类数 10
- TN: 将负类预测为负类数 30
准确率A
(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率P
(precision) = TP/(TP+FP) = 80%
召回率R
(recall) = TP/(TP+FN) = 2/3 ≈ 0.66
F值
F = P x R x 2 / (P + R) = 8/11 ≈ 0.727
AP
AP(average precision 平均精度):AP是计算单类别的模型平均准确度。对于目标检测任务,每一个类都可以计算出其Precision和Recall,每个类都可以得到一条P-R曲线,曲线下的面积就是AP的值。如果一个算法的AP值较大,也就是P-R曲线(Precision-Recall Curve)下的面积比较大,可以认为此算法查准率和查全率整体上相对较好。
较好的意思对应猫狗的例子,就是所有数据里大部分猫都在你查找的结果里,并且你的结果里狗(非猫)很少(找错的情况少)。
AP是Precision-Recall Curve(PRC)下面的面积!!!
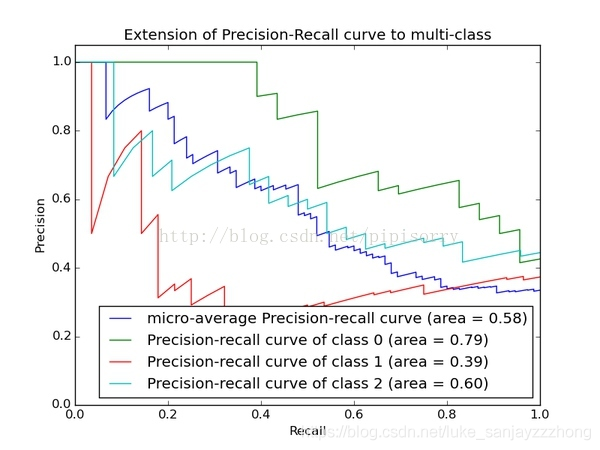
PRC怎么看:先看平滑不平滑(蓝线明显好些),在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。
mAP@0.5 :
mean Average Precision 给每一类分别计算AP,然后做mean平均
Pascal VOC(VOC2007 & VOC2012)是评测目标检测算法的常用数据集,VOC数据集使用一个固定的IoU阈值0.5来计算AP值。 所以VOC数据集中mAP通常标记为
mAP@IoU=0.5 或mAP@0.5 或mAP_50
mAP@[0.5:0.95]:
但是在2014年之后,MS-COCO(Microsoft Common Objects)数据集逐渐兴起。在COCO数据集中,更关注预测框位置的准确性,AP值是针对多个IoU阈值的AP平均值,具体的就是在0.5 和0.95之间取10个IoU阈值(0.5、0.55、0.6 ….. 0.9、0.95)。在COCO 数据集中册标记为
mAP@IoU=0.5:0.05:0.95 或mAP IoU=0.5:0.95 或mAP@[0.5:0.95] 或mAP@.5:.95
IoU
(Intersection over Union)是两个区域重叠的部分除以两个区域的集合部分得出的结果,通过设定的阈值,与这个IoU计算结果比较。
下图红色框为预测包容盒,绿色框为真实包容盒

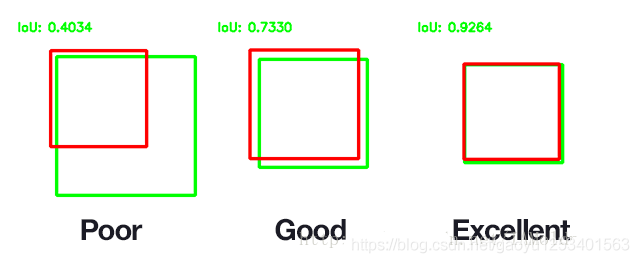
举例如下:绿色框是准确值,红色框是预测值。

若有收获,就点个赞吧
0 人点赞
