视频:https://www.bilibili.com/video/BV1Y7411d7Ys?p=9
博客:https://blog.csdn.net/bit452/article/details/109686936
说明:
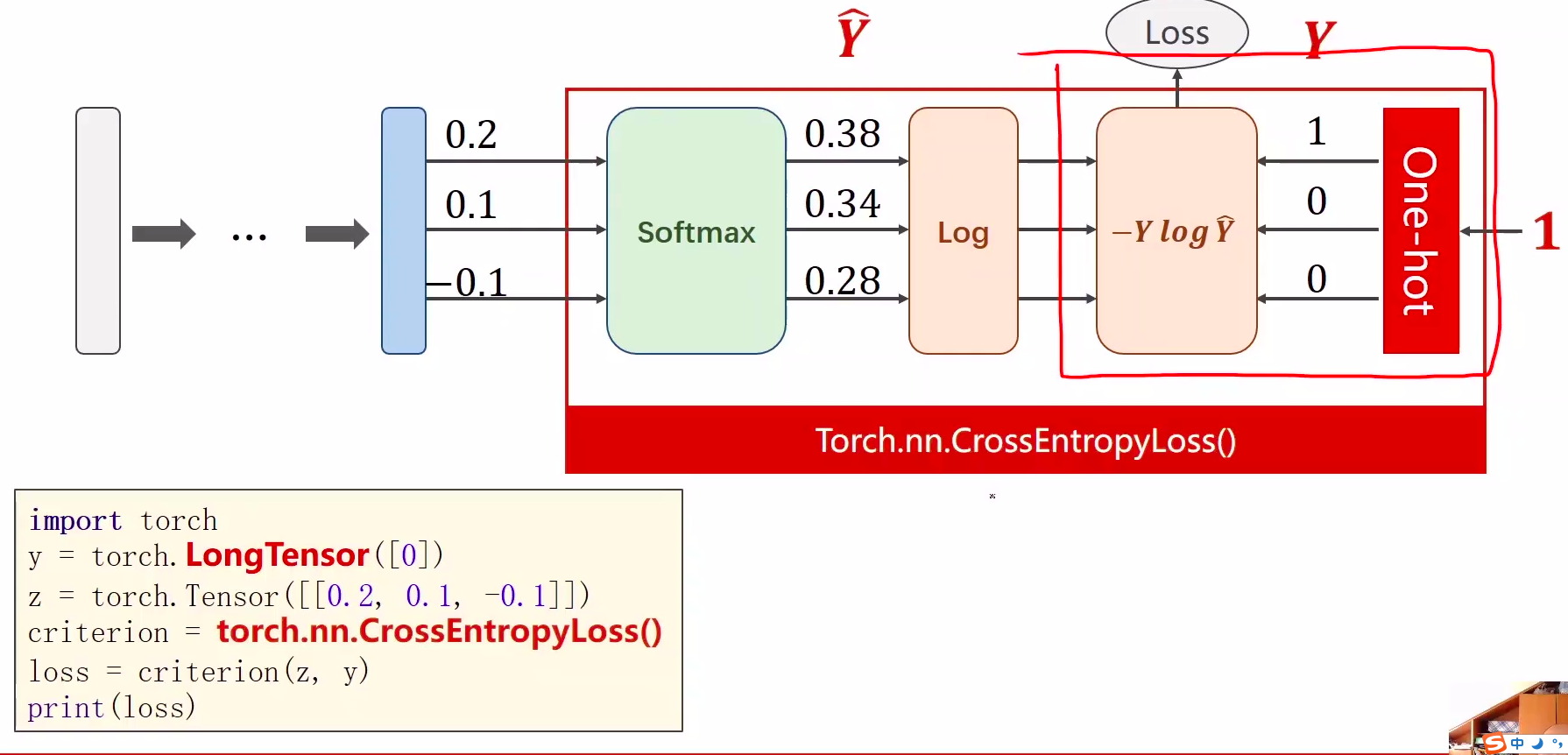
1、softmax的输入不需要再做非线性变换,也就是说softmax之前不再需要激活函数(relu),交叉熵损失已经囊括了
softmax两个作用
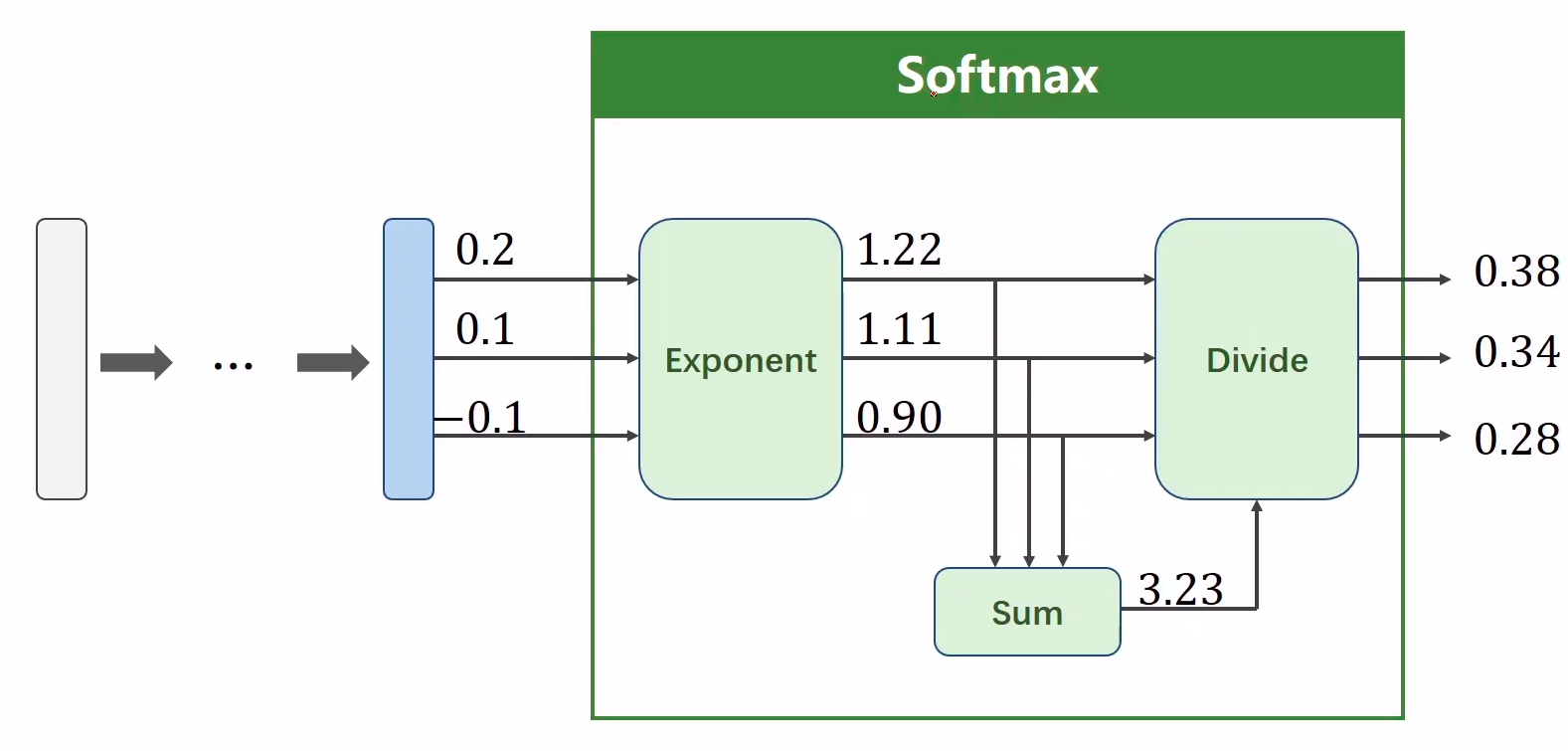
- 如果在进行softmax前的input有负数,通过指数变换,得到正数。
- 所有类的概率求和为1。
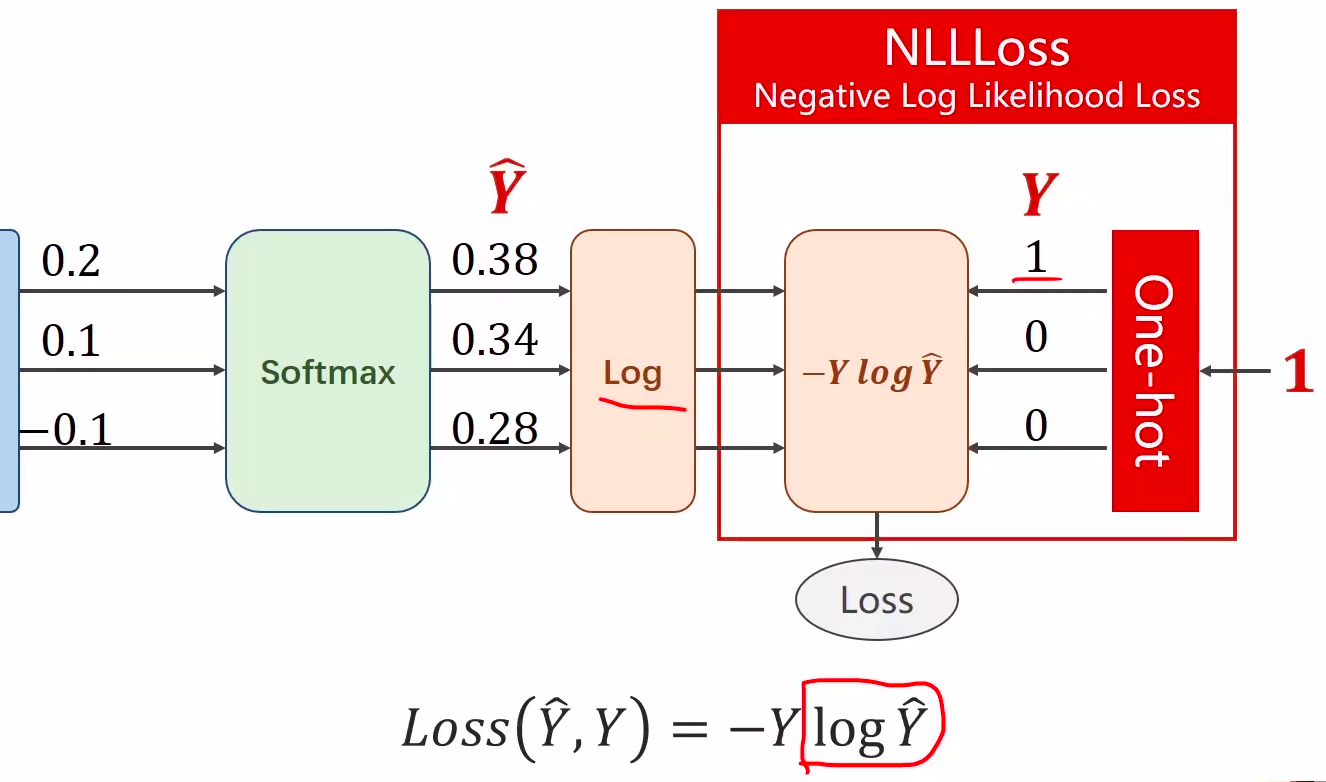
2、y的标签编码方式是one-hot。我对one-hot的理解是只有一位是1,其他位为0
3、多分类问题,标签y的类型是LongTensor。比如说0-9分类问题,如果y = torch.LongTensor([3]),对应的one-hot是[0,0,0,1,0,0,0,0,0,0].
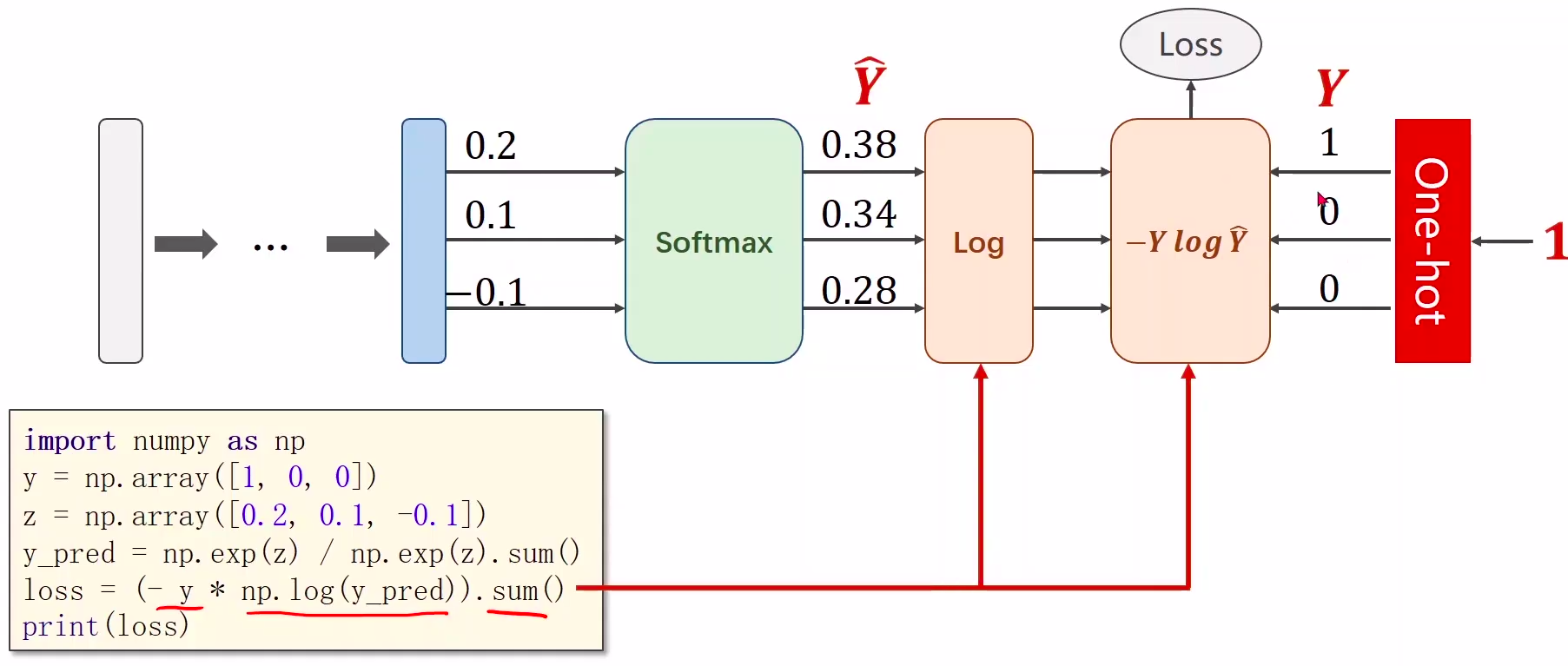
4、交叉熵损失CrossEntropyLoss <==> LogSoftmax + NLLLoss
两个区别
https://pytorch.org/docs/stable/nn.html#crossentropyloss
https://pytorch.org/docs/stable/nn.html#nllloss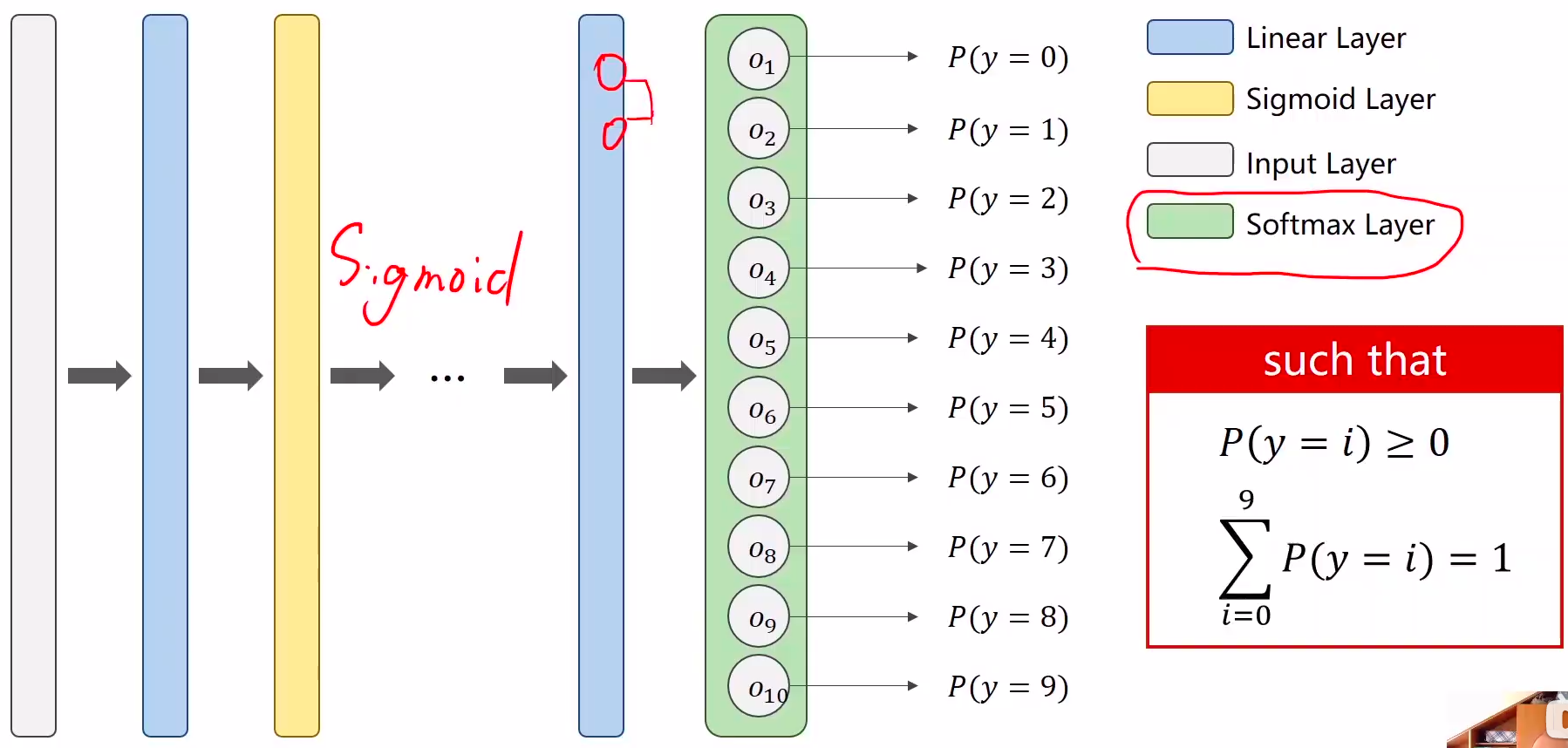
 |
 |
|---|---|
代码说明:
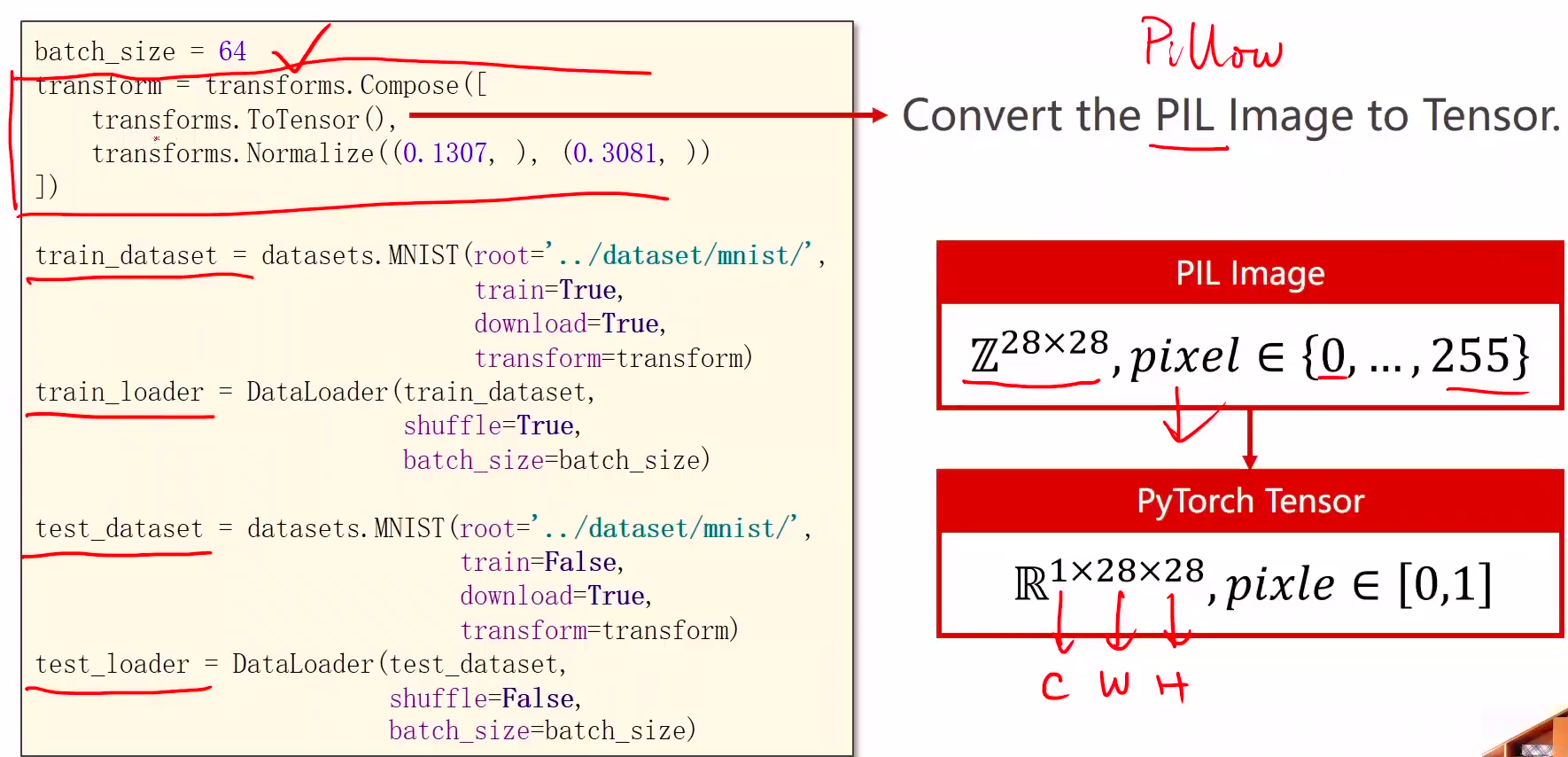
1、第8讲 from torch.utils.data import Dataset,第9讲 from torchvision import datasets。该datasets里面init,getitem,len魔法函数已实现。
2、torch.max的返回值有两个,第一个是每一行的最大值是多少,第二个是每一行最大值的下标(索引)是多少。
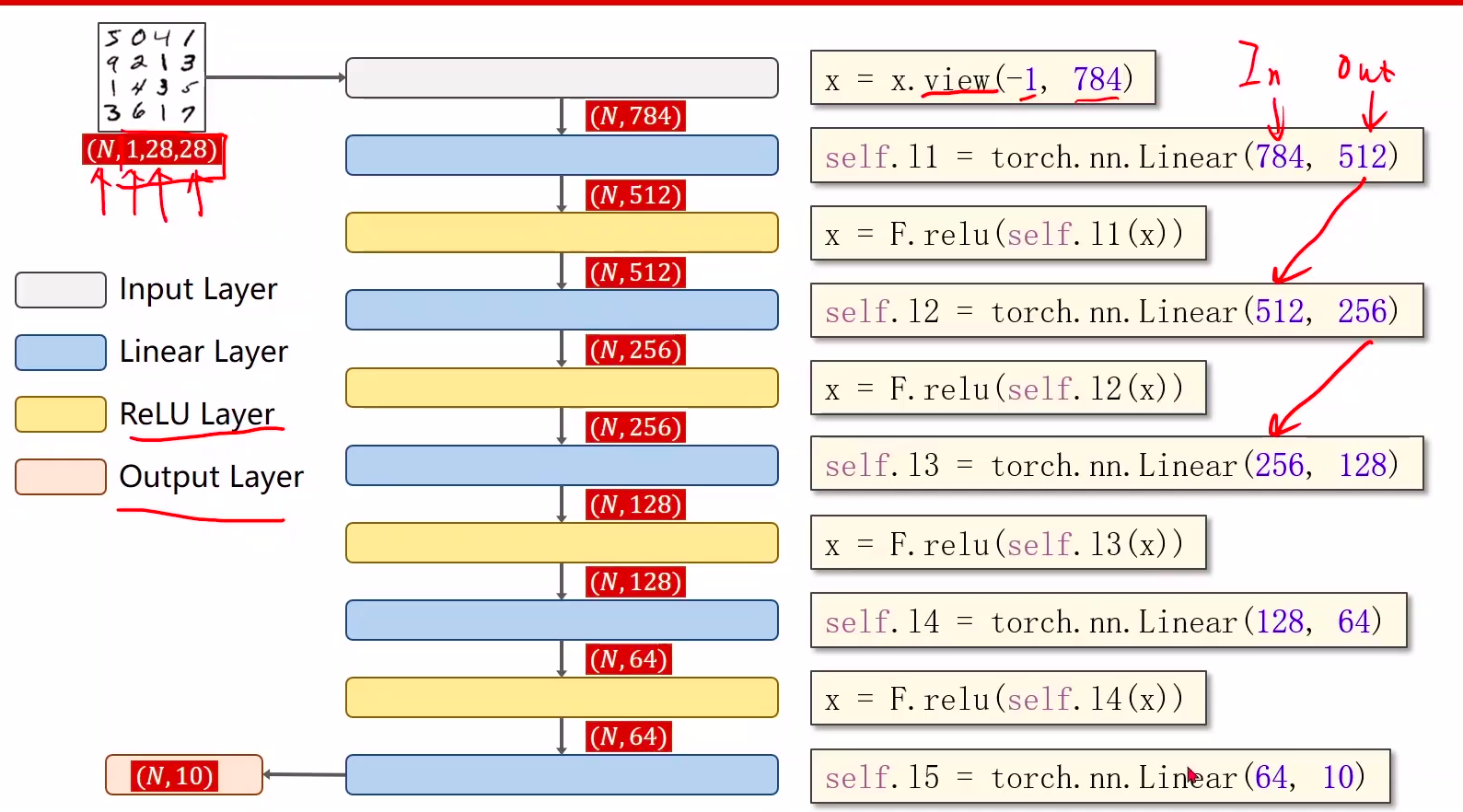
3、全连接神经网络
1 Prepare dataset
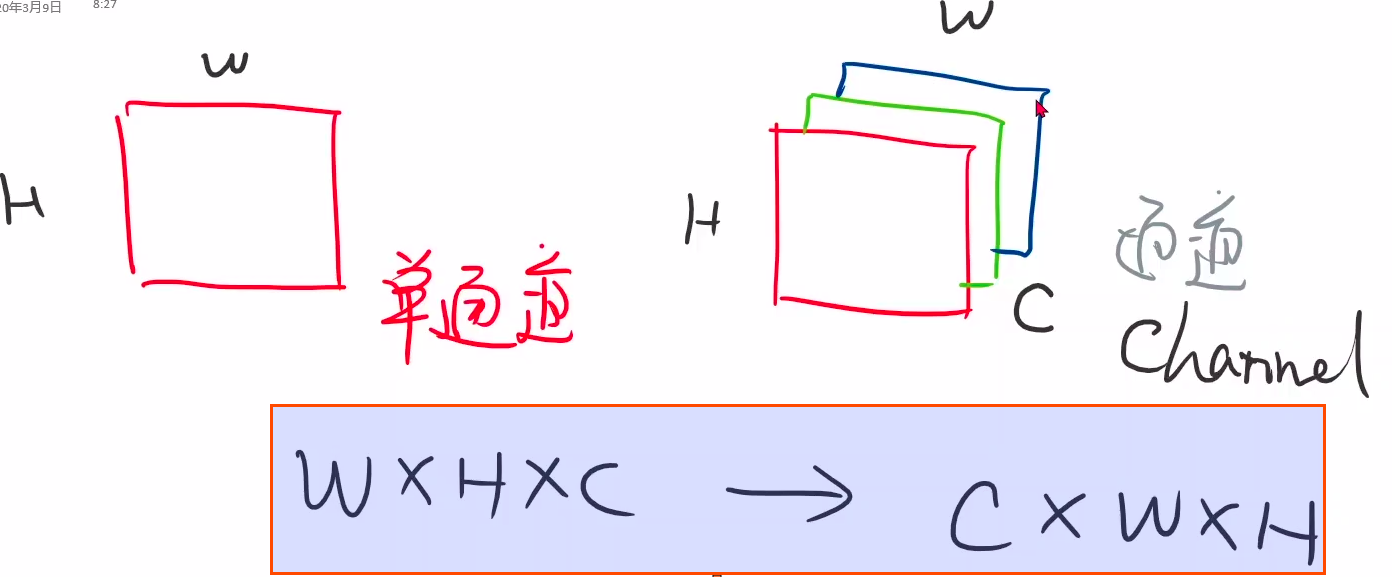
transform将PIL Image转化为Tensor
- 通道转换: wxhxc → cxwxh
- 单通道变成多通道
2 Design model using Class
- inherit from nn.Module 计算y^hat
- 注意:最后一层,不做激活
 **
**
3 Construct loss and optimizer
- using PyTorch API 计算loss和optimizer
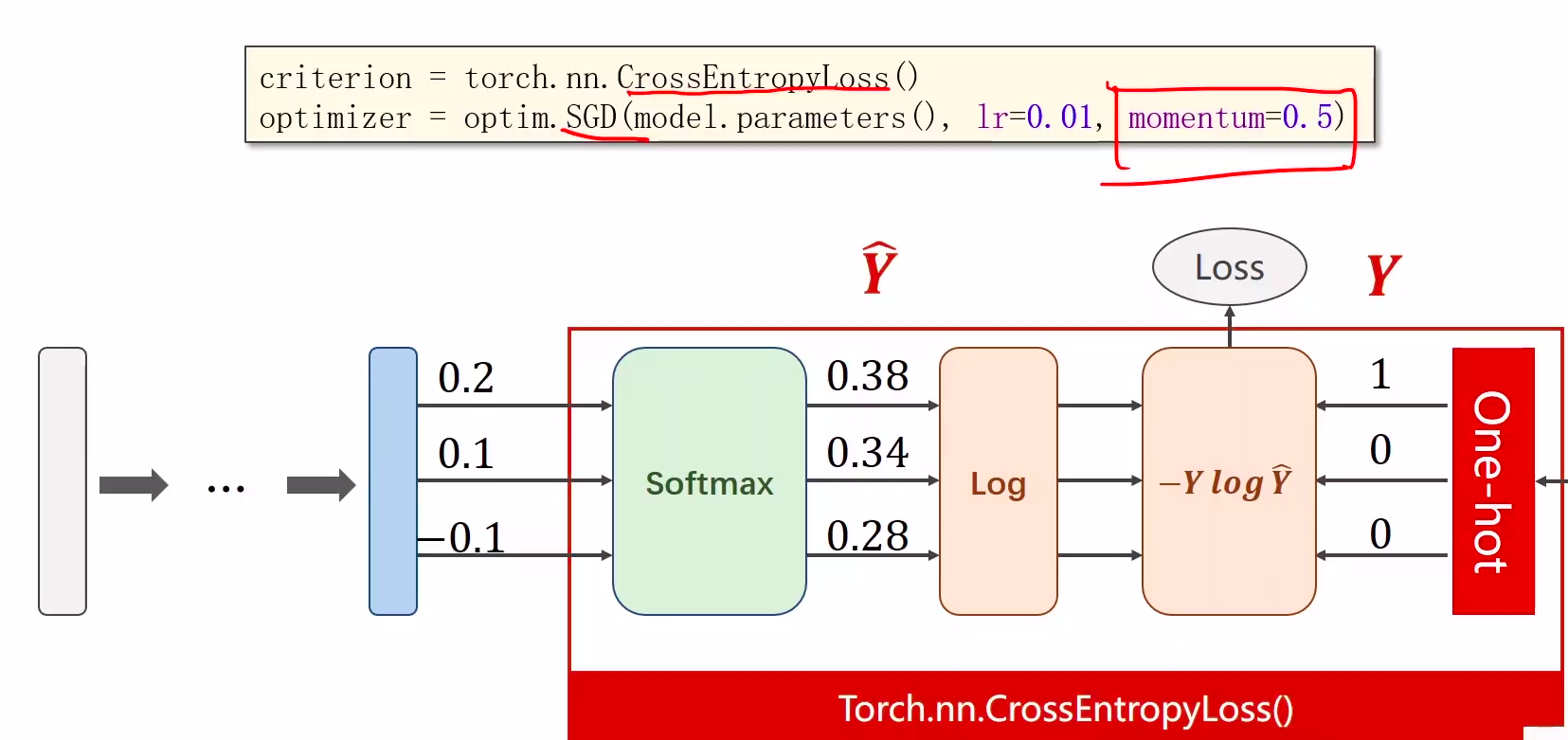
4 Training cycle
loss.items
test测试 测试(不需要反向传播,主需要算正向的)
全部代码
'''Description: 多分类问题(softmax)视频:https://www.bilibili.com/video/BV1Y7411d7Ys?p=9博客:https://blog.csdn.net/bit452/article/details/109686936Author: HCQCompany(School): UCASEmail: 1756260160@qq.comDate: 2020-12-06 20:05:38LastEditTime: 2020-12-06 21:34:51FilePath: /pytorch/PyTorch深度学习实践/09多分类问题softmax.py'''import torchfrom torchvision import transforms # 针对图像处理from torchvision import datasetsfrom torch.utils.data import DataLoaderimport torch.nn.functional as F # 为了使用激活函数relu()import torch.optim as optim # optim.SGD# 1 prepare datasetbatch_size = 64# 归一化,均值和标准差 将PIL Image转化为Tensor # 0.1307,), (0.3081,) 分别对应均值和标准差transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='./data/mnist/', train=True, download=True, transform=transform)train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)test_dataset = datasets.MNIST(root='./data/mnist/', train=False, download=True, transform=transform)test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# 2 design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.l1 = torch.nn.Linear(784, 512)self.l2 = torch.nn.Linear(512, 256)self.l3 = torch.nn.Linear(256, 128)self.l4 = torch.nn.Linear(128, 64)self.l5 = torch.nn.Linear(64, 10)def forward(self, x):x = x.view(-1, 784) # -1其实就是自动获取mini_batch,即N,mini样本数x = F.relu(self.l1(x)) # 激活函数relux = F.relu(self.l2(x))x = F.relu(self.l3(x))x = F.relu(self.l4(x))return self.l5(x) # 最后一层不做激活,不进行非线性变换model = Net()# 3 construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# 4 training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad() # 优化器清零outputs = model(inputs) # 计算y hatloss = criterion(outputs, target) # 计算lossloss.backward()optimizer.step()running_loss += loss.item() # items()if batch_idx % 300 == 299: # 训练300次输出一次print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))running_loss = 0.0# 测试(不需要反向传播,主需要算正向的)def test():correct = 0total = 0with torch.no_grad(): # 来阻止autograd跟踪设置了 .requires_grad=True 的张量的历史记录。for data in test_loader: # test_loader 测试集images, labels = dataoutputs = model(images) # torch.Size([64, 10])_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度 求每一行最大下标 (64,1) || _,对应最大值,predicted对应最大值索引total += labels.size(0) # labels.size(0) = N , (N, 1)correct += (predicted == labels).sum().item() # 张量之间的比较运算 预测值和label值print('accuracy on test set: %d %% ' % (100*correct/total))if __name__ == '__main__':for epoch in range(10):train(epoch)# if epoch % 10 == 9: # 可以设置10轮测试一次test()
结果
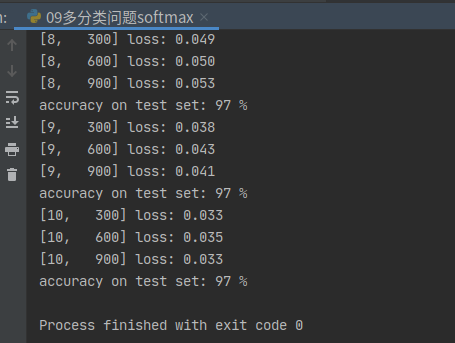
97% ,没有考虑局部特征,为了更好优化
人为特征:FFT,小波
auto: CNN,RNN
Exercise 9-2: Classifier Implementation
https://www.kaggle.com/c/otto-group-product-classification-challenge/data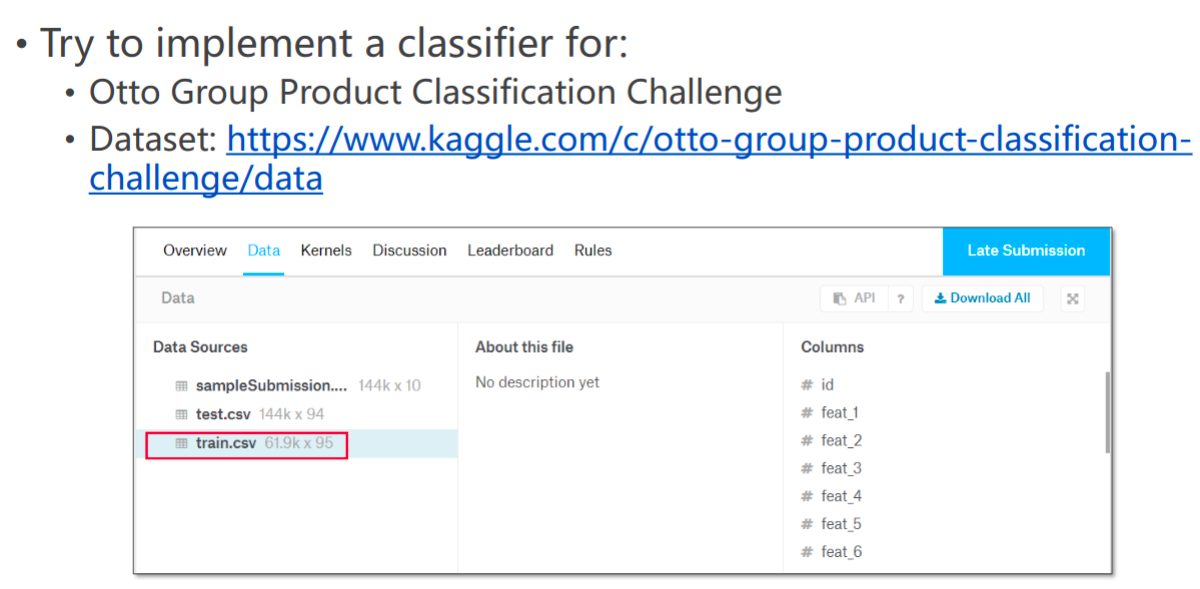

若有收获,就点个赞吧
0 人点赞
