https://blog.csdn.net/bit452/article/details/109643481
https://www.bilibili.com/video/BV1Y7411d7Ys?p=4
重点
0 传送门 Tensor和tensor的区别
torch.Tensor是torch.FloatTensor的别名,是python类,只能创建FloatTensor。从首字母大写也可以看出一些端倪。torch.tensor是一个函数,可以将其它数据结构转化成tensor,可以创建FloatTensor,IntTensor等等。
例子:
>>> torch.Tensor([1, 2]).dtype>>> torch.float32>>> torch.tensor([1, 2]).dtype>>> torch.int64>>> torch.tensor([1, 2], dtype=torch.float32).dtype>>> torch.float32
https://blog.csdn.net/ECNU_LZJ/article/details/104203655
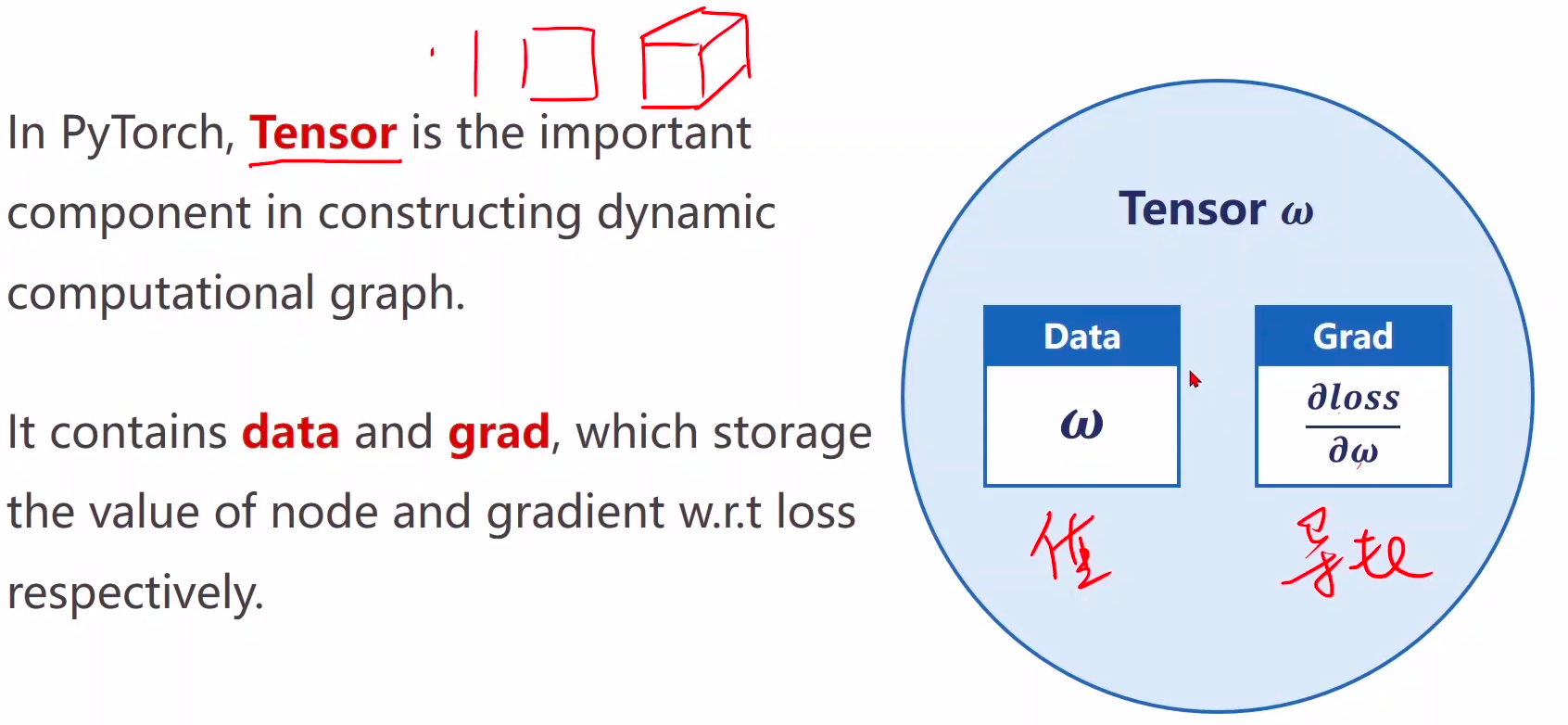
1 w是Tensor(张量类型),Tensor中包含data(权重w的值)和grad(权重w导数的值)
注意你要处理的是计算图还是简单的数据加减
1、w是Tensor(张量类型),Tensor中包含data(权重w的值)和grad(权重w导数的值),data和grad也是Tensor。grad初始为None,调用l.backward()方法后w.grad为张量类型,故更新w.data时需使用w.grad.data。如果w需要计算梯度,那构建的计算图中,跟w相关的tensor都默认需要计算梯度。
data和item的区别
w.grad.item()
w.grad.data
.item()返回的是一个具体的数值。
注意:对于元素不止一个的tensor列表,使用item()会报错
import torcha = torch.Tensor([1.0])a.requires_grad = Trueprint(a) # a的类型是tensorprint(a.data) # a.data的类型是tensorprint(a.data.item()) # a.data.item()是标量,float类型print(type(a.data.item()))print(a.grad)

2、w是Tensor, forward函数的返回值也是Tensor,loss函数的返回值也是Tensor
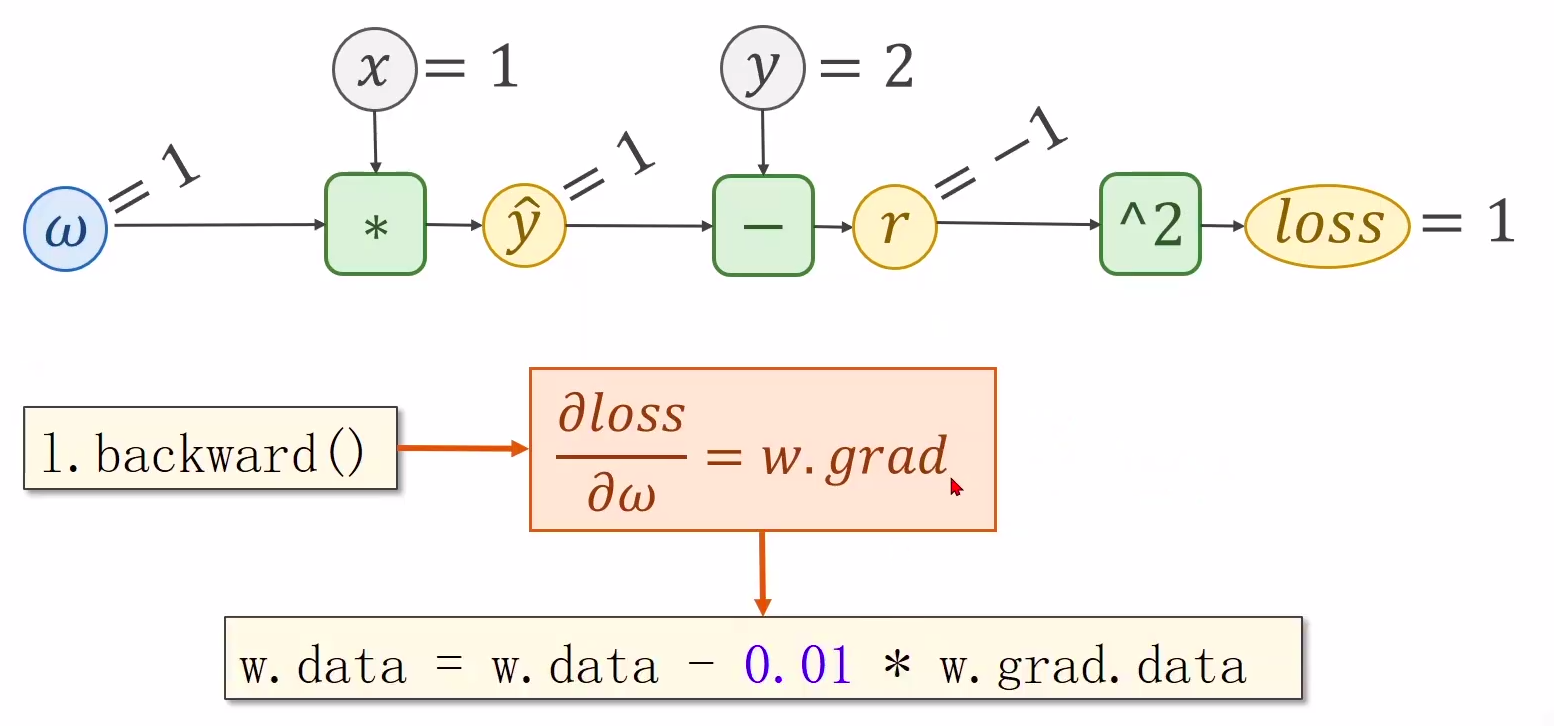
3、本算法中反向传播主要体现在,l.backward()。调用该方法后w.grad.data的值可用于后续w.data的更新。
过程
1 数据初始化

2 模型x*w 和loss
脑中有构建计算图的过程

3 训练过程(先损失,然后反向传播,根据梯度权值w更新)

调用l.backward()方法后
- 自动计算所有梯度,然后把梯度存在各自有梯度的地方,本案例存放在w里面
- 只要backward,这个**计算图就被释放**了,下次再计算loss,会创建一个新的计算图
- w.grad为张量类型,故更新w.data时需使用w.grad.data。如果w需要计算梯度,那构建的计算图中,跟w相关的tensor都默认需要计算梯度。
- 使用data计算是不会有计算图的

w.grad.data : tensor([-5.7220e-06]) 是个张量tensor!!!
w.grad.data.zero_()
在使用pytorch实现多项线性回归中,在grad更新时,每一次运算后都需要将上一次的梯度记录清空,运用如下方法:
w.grad.data.zero()
b.grad.data.zero()
求平均损失值,要加items()
不能直接sum+ = l,这是变成计算图了,加items()
4 更新过程
代码
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0]) # w的初值为1.0
w.requires_grad = True # 需要计算梯度
def forward(x):
return x*w # w是一个Tensor
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)**2
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l =loss(x,y) # l是一个张量,tensor主要是在建立计算图 forward, compute the loss
l.backward() # backward,compute grad for Tensor whose requires_grad set to True
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # 权重更新时,需要用到标量,注意grad也是一个tensor
w.grad.data.zero_() # after update, remember set the grad to zero
print('progress:', epoch, l.item()) # 取出loss使用l.item,不要直接使用l(l是tensor会构建计算图)
print("predict (after training)", 4, forward(4).item())
传送门 本讲作业参考

若有收获,就点个赞吧
0 人点赞
