https://mp.weixin.qq.com/s/yyyCKd9W86H5MtpkdEmXPw
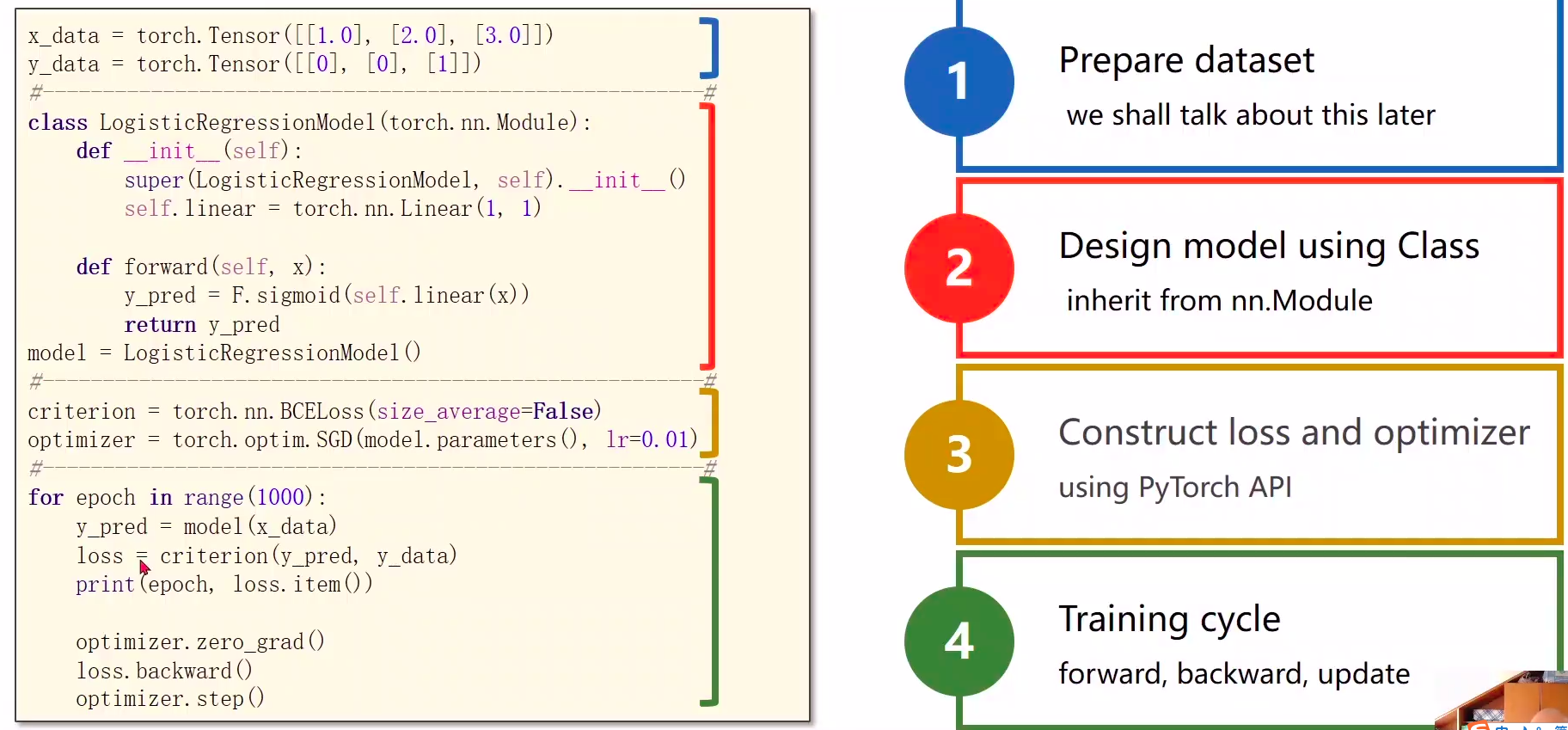
1 Prepare dataset
2 Design model using Class
- inherit from nn.Module 计算y^hat
3 Construct loss and optimizer
- using PyTorch API 计算loss和optimizer
4 Training cycle
- forward, backward, update 前馈,反馈,更新
1 Prepare dataset
图像数据
点云数据
2 Design model using Class
inherit from nn.Module 计算y^hat
model
class xxxModel(torch.nn.Module): class类里面至少实现两个函数(backword内部实现,不用写)
def init(self,传递参数) # 初始化对象的时候默认调用的函数(构造函数)
- def forward(slf, x) # 前馈的时候所要执行的计算(backword反向自动根据计算图实现,不用写)
"""our model class should be inherit from nn.Module, which is base class for all neural network modules.member methods __init__() and forward() have to be implementedclass nn.linear contain two member Tensors: weight and biasclass nn.Linear has implemented the magic method __call__(),which enable the instance of the class canbe called just like a function.Normally the forward() will be called"""class LinearModel(torch.nn.Module): # 继承torch.nn.Module, torch.nn.Module是父类def __init__(self): # 构造函数(初始化)super(LinearModel, self).__init__() # 调用父类的init super(LinearModel, self) == torch.nn.Module# (1,1)是指输入x和输出y的特征维度,这里数据集中的x和y的特征都是1维的# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.biasself.linear = torch.nn.Linear(1, 1) # 构造对象,执行wx+b的操作,Linear也是继承自Model,并说明输入输出的维数,第三个参数默认为true,表示用到bdef forward(self, x):y_pred = self.linear(x) #可调用对象(对象括号里面加参数x),计算y=wx+breturn y_predmodel = LinearModel() # 自动构建计算图,实现反向(自带的,不用写)

3 Construct loss and optimizer 损失&优化器
- using PyTorch API 计算loss和optimizer
4 Training cycle 训练epoch
- forward, backward, update 前馈,反馈,更新

for epoch in range(epochs): # 100============================================acc_loss = 0.0num_samples = 0start_tic = time.time()for x, y in train_loader: # Iteration=样本数/batch_size 遍历数据(每次train_loader不一样?)=optimizer.zero_grad() # 0 set grad to zeroout = model(x) # 1 模型输入,求解yloss = softXEnt(out, y) # 2 计算损失loss.backward() # 3 loss backwardoptimizer.step() # 4 update network's param
5 Test 测试

若有收获,就点个赞吧
0 人点赞
