视频:https://www.bilibili.com/video/BV1Y7411d7Ys?p=8
博客:
https://blog.csdn.net/bit452/article/details/109686474
https://blog.csdn.net/weixin_44841652/article/details/105129235
这期教程讲的是如何使用dataset(构造数据集,支持索引)和dataloader(拿出一个mini-bath),咱们直接看代码,边看边说。
说明:1、DataSet 是抽象类,不能实例化对象,主要是用于构造我们的数据集
2、DataLoader 需要获取DataSet提供的索引[i]和len;用来帮助我们加载数据,比如说做shuffle(提高数据集的随机性),batch_size,能拿出Mini-Batch进行训练。它帮我们自动完成这些工作。DataLoader可实例化对象。
代码说明:
1、需要mini_batch 就需要import DataSet和DataLoader
2、继承DataSet的类需要重写init,getitem,len魔法函数。分别是为了加载数据集,获取数据索引,获取数据总量。
3、DataLoader对数据集先打乱(shuffle),然后划分成mini_batch。
4、len函数的返回值 除以 batch_size 的结果就是每一轮epoch中需要迭代的次数。
5、inputs, labels = data中的inputs的shape是[32,8],labels 的shape是[32,1]。也就是说mini_batch在这个地方体现的
6、diabetes.csv数据集老师给了下载地址,该数据集需和源代码放在同一个文件夹内。
DataLoader对数据集先打乱(shuffle),然后划分成mini_batch。
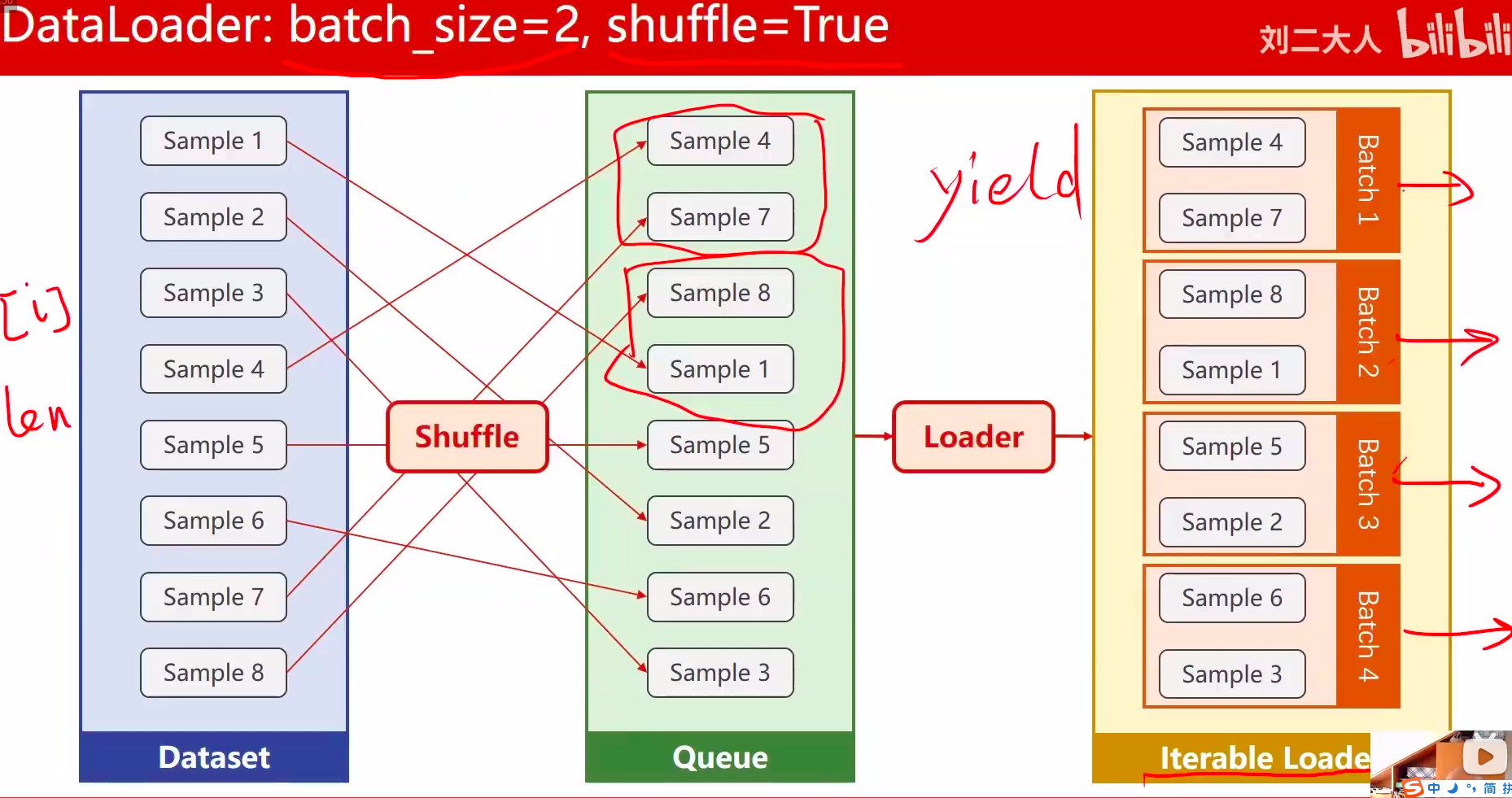
数据集加载
- 数据少,一次加载
- 数据多,将文件路径加载到一个列表,每次读取一个文件列表进行后续处理


训练循环

内置数据集介绍
- MNIST
- Fashion-MNIST
- EMNIST
- COCO
- LSUN
- ImageFolder
- DatasetFolder
- Imagenet-12
- CIFAR•STL10
- PhotoTour
Example: MINST Dataset

全部代码
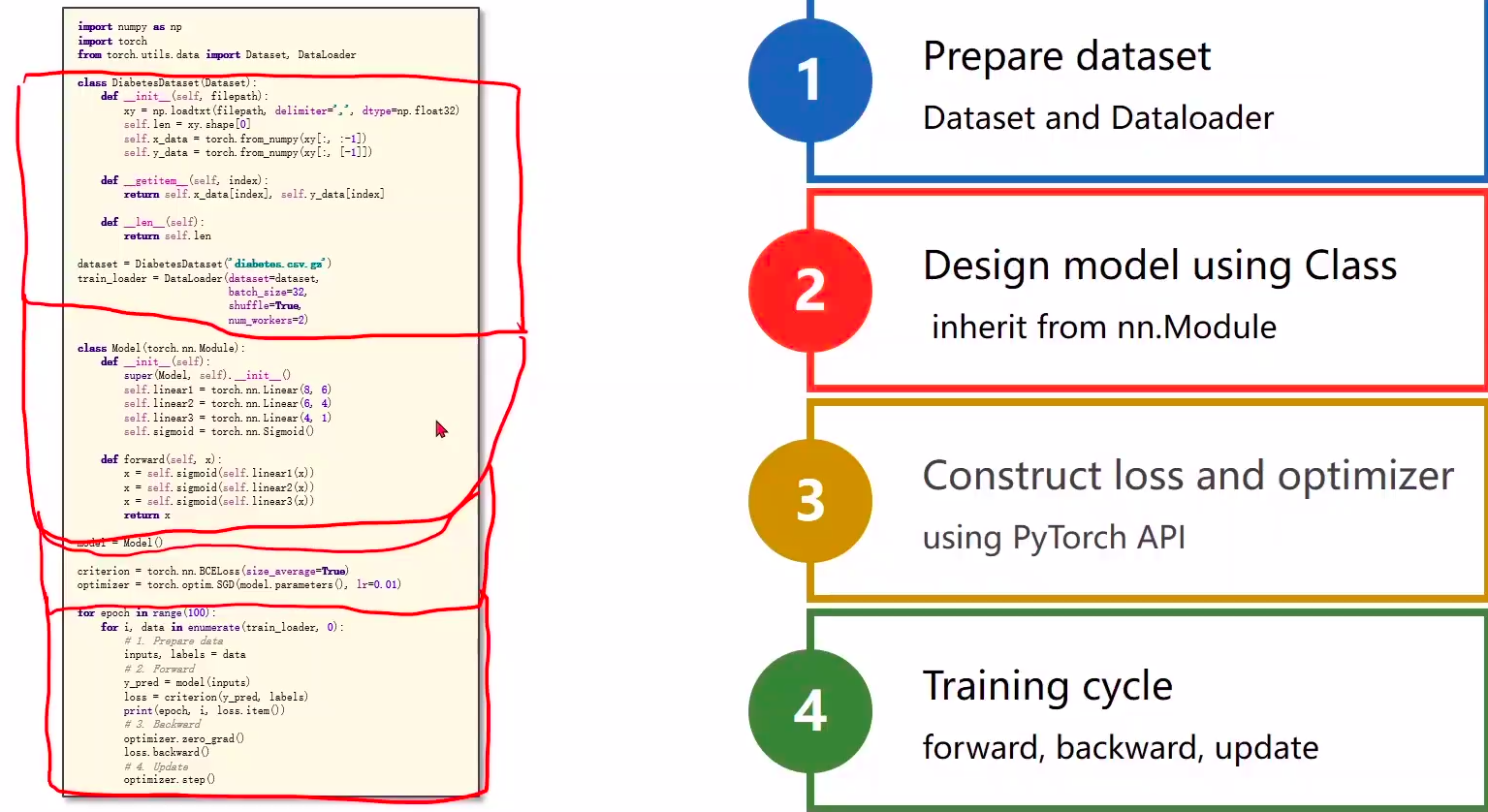
'''Description: 处理多维特征的输入视频:https://www.bilibili.com/video/BV1Y7411d7Ys?p=7博客:https://blog.csdn.net/bit452/article/details/109682078https://blog.csdn.net/weixin_44841652/article/details/105125826Author: HCQCompany(School): UCASEmail: 1756260160@qq.comDate: 2020-12-06 12:37:48LastEditTime: 2020-12-06 17:16:16FilePath: /pytorch/PyTorch深度学习实践/07处理多维特征的输入.py'''import torch# import torch.nn.functional as F # 没用到import numpy as npimport matplotlib.pyplot as plt # 画图# from sklearn import datasets # 没用到# prepare datasetxy=np.loadtxt('./data/Diabetes_class.csv.gz',delimiter=',',dtype=np.float32)#加载训练集合x_data = torch.from_numpy(xy[:,:-1])#取前八列 第二个‘:-1’是指从第一列开始,最后一列不要y_data = torch.from_numpy(xy[:,[-1]]) # [-1] 最后得到的是个矩阵# 没有这个测试集# test =np.loadtxt('./data/test_class.csv.gz',delimiter=',',dtype=np.float32)#加载测试集合,这里我用数据集的最后一个样本做测试,训练集中没有最后一个样本# test_x = torch.from_numpy(test)# 2 design model using classclass Model(torch.nn.Module):def __init__(self):#构造函数super(Model,self).__init__()self.linear1 = torch.nn.Linear(8,6)#8维到6维self.linear2 = torch.nn.Linear(6, 4)#6维到4维self.linear3 = torch.nn.Linear(4, 1)#4维到1维self.sigmoid = torch.nn.Sigmoid()# 将其看作是网络的一层,而不是简单的函数使用 # 因为他里边也没有权重需要更新,所以要一个就行了,单纯的算个数# 尝试不同的激活函数 torch.nn.ReLU()def forward(self, x):#构建一个计算图,就像上面图片画的那样x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))#将上面一行的输出作为输入x = self.sigmoid(self.linear3(x)) # # y hat ==================================return x# 3 construct loss and optimizermodel = Model()#实例化模型criterion = torch.nn.BCELoss(size_average=False)#model.parameters()会扫描module中的所有成员,如果成员中有相应权重,那么都会将结果加到要训练的参数集合上optimizer = torch.optim.SGD(model.parameters(),lr=0.1)#lr为学习率,因为0.01太小了,我改成了0.1epoch_list = [] # 用来画图loss_list = [] # 用来画图# 4 training cycle forward, backward, updatefor epoch in range(1000):#Forwardy_pred = model(x_data) # 没有用Mini_batchloss = criterion(y_pred,y_data)print(epoch,loss.item())epoch_list.append(epoch) # 用来画图loss_list.append(loss.item()) # 用来画图#Backwardoptimizer.zero_grad()loss.backward()#updateoptimizer.step()y_pred = model(x_data)print(y_pred.detach().numpy())# y_pred2 = model(test_x)# print(y_pred2.data.item())# 绘图plt.plot(epoch_list, loss_list)plt.ylabel('loss')plt.xlabel('epoch')plt.show()
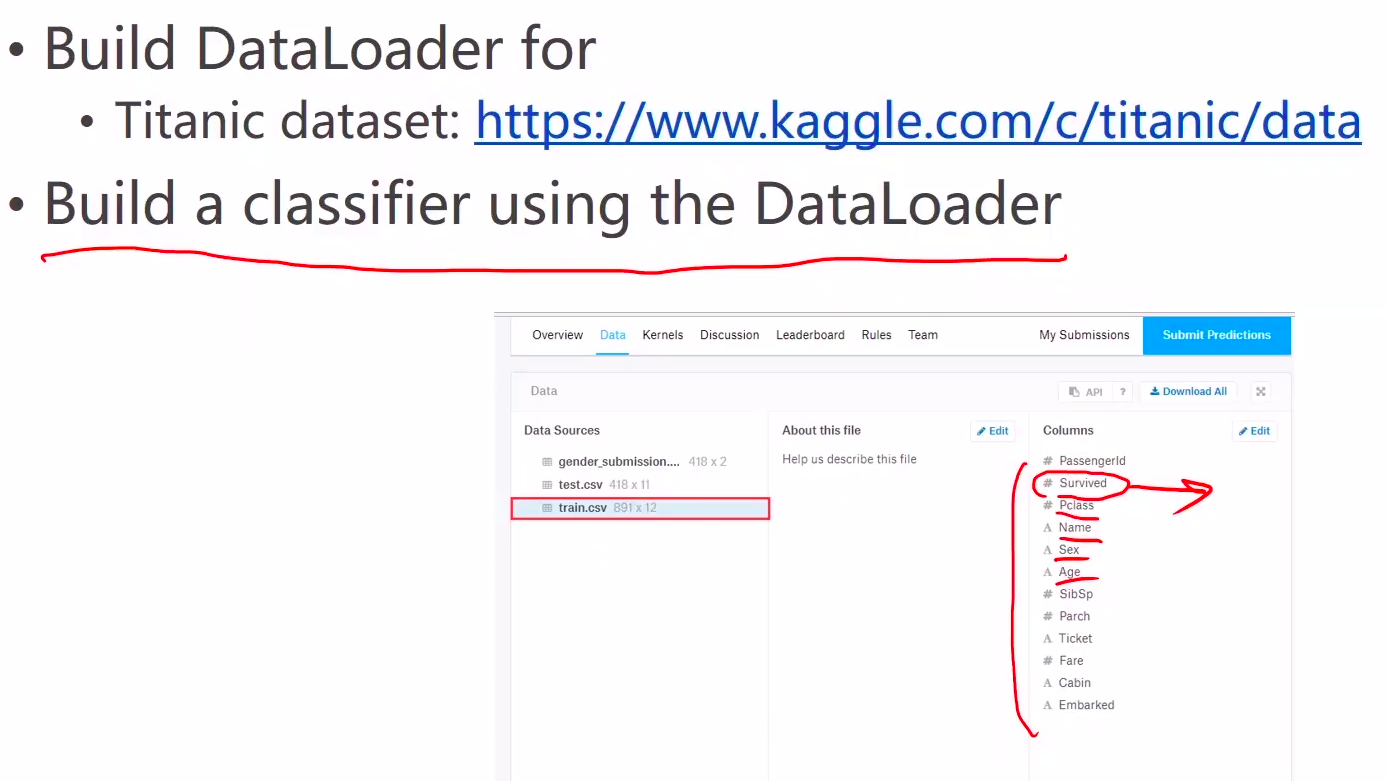
Exercise8.1 Titanic dataset

若有收获,就点个赞吧
0 人点赞
