- 1 nn.Conv2d 3d(卷积层)
- 2 pooling(池化层)
">- 3 非线性激活函数(非线性特征)
- 4 线性 nn.Linear(in_features, out_features)全连接层(1维)
- 5 Loss和反向传播
- torch.optim">6 优化器 torch.optim
- nn.LayerNorm 归一化
- nn.Softmax(dim=-1)(scores) 总和为1
- nn.ReLU 激活函数
- nn.Dropout(p=dropout) 随机失活
- 词嵌入">nn.Embedding 词嵌入
- Plus:nn.Sequential
- ModuleList">Plus: nn.ModuleList
- Last: GPU并行
https://github.com/HuangCongQing/pytorch/tree/master/torch.nn
PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】video
我是土堆· 2019-11-2
API: https://pytorch.org/docs/stable/nn.html
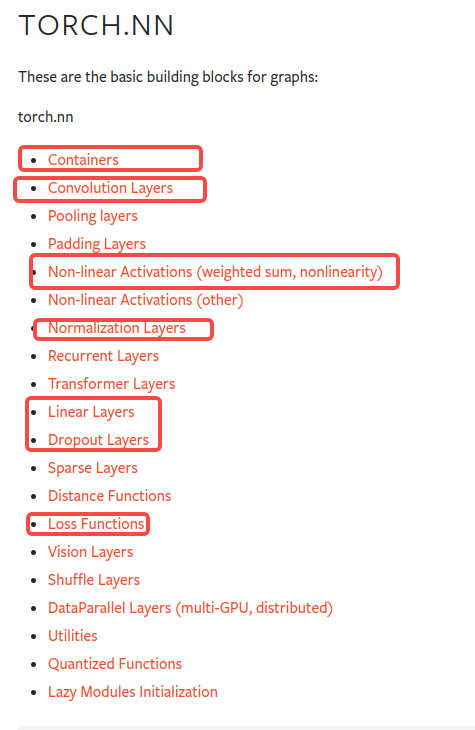
torch.nn
- Containers
- Convolution Layers
- Pooling layers
- Padding Layers
- Non-linear Activations (weighted sum, nonlinearity)
- Non-linear Activations (other)
- Normalization Layers
- Recurrent LayersRNN
- Transformer LayersTransformer
- Linear Layers
- Dropout Layers
- Sparse LayersNLP
- Distance Functions
- Loss Functions
- Vision Layers
- Shuffle Layers
- DataParallel Layers (multi-GPU, distributed)
- Utilities
- Quantized Functions
- Lazy Modules Initialization
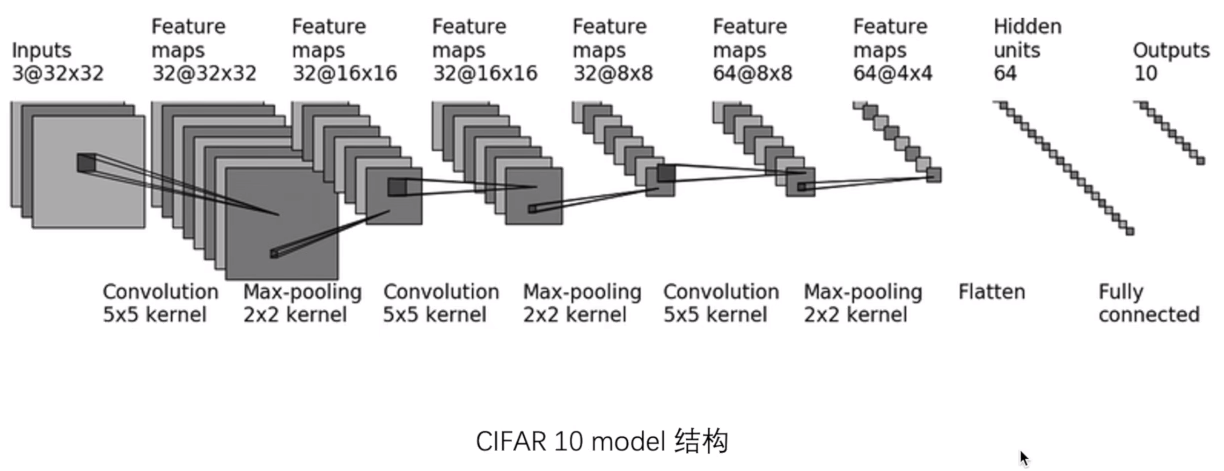
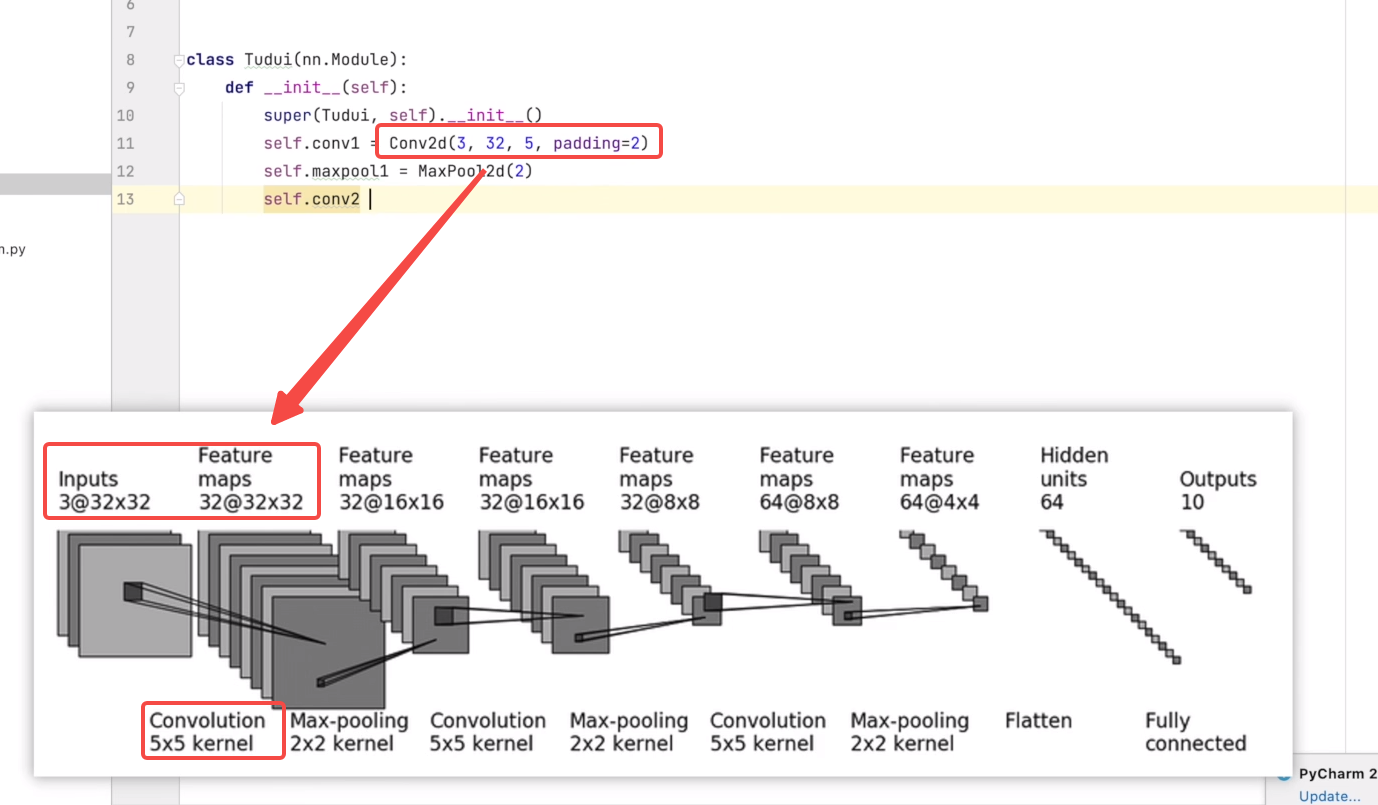
1 nn.Conv2d 3d(卷积层)
https://pytorch.org/docs/stable/nn.html#convolution-layers
(BCHW): Channel是在第二维度上
nn.Conv2d
https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
orch.nn.Conv2d(i**n_channels**, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=’zeros’, device=None, dtype=None**)

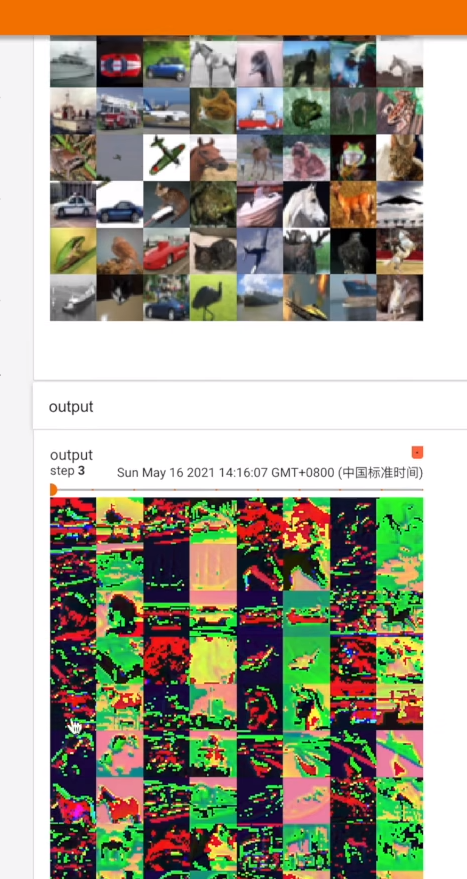
2 pooling(池化层)
MaxPool2d()
https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d
**torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
3 非线性激活函数(非线性特征)
https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
nn.ReLU
inplace: 就地操作

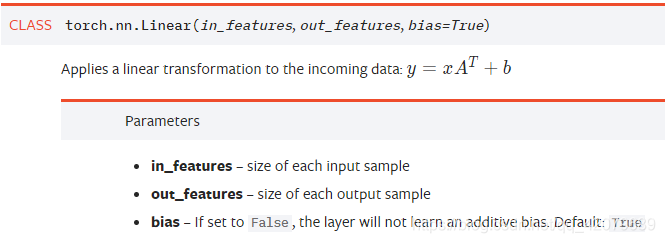
4 线性 nn.Linear(in_features, out_features)全连接层(1维)
nn.Linear
输入的nn.Linear(in_features, out_features) 的in和out实际上是w和b的维度
https://blog.csdn.net/qq_42079689/article/details/102873766
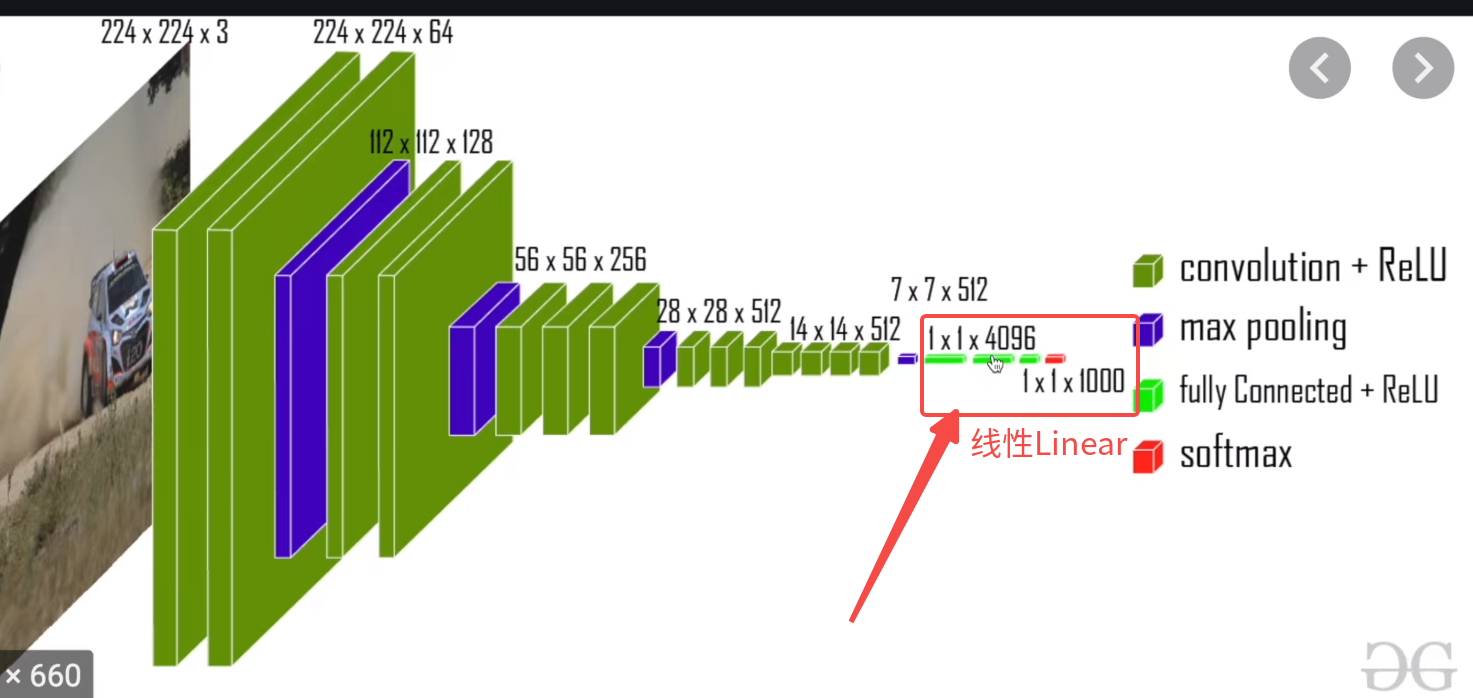
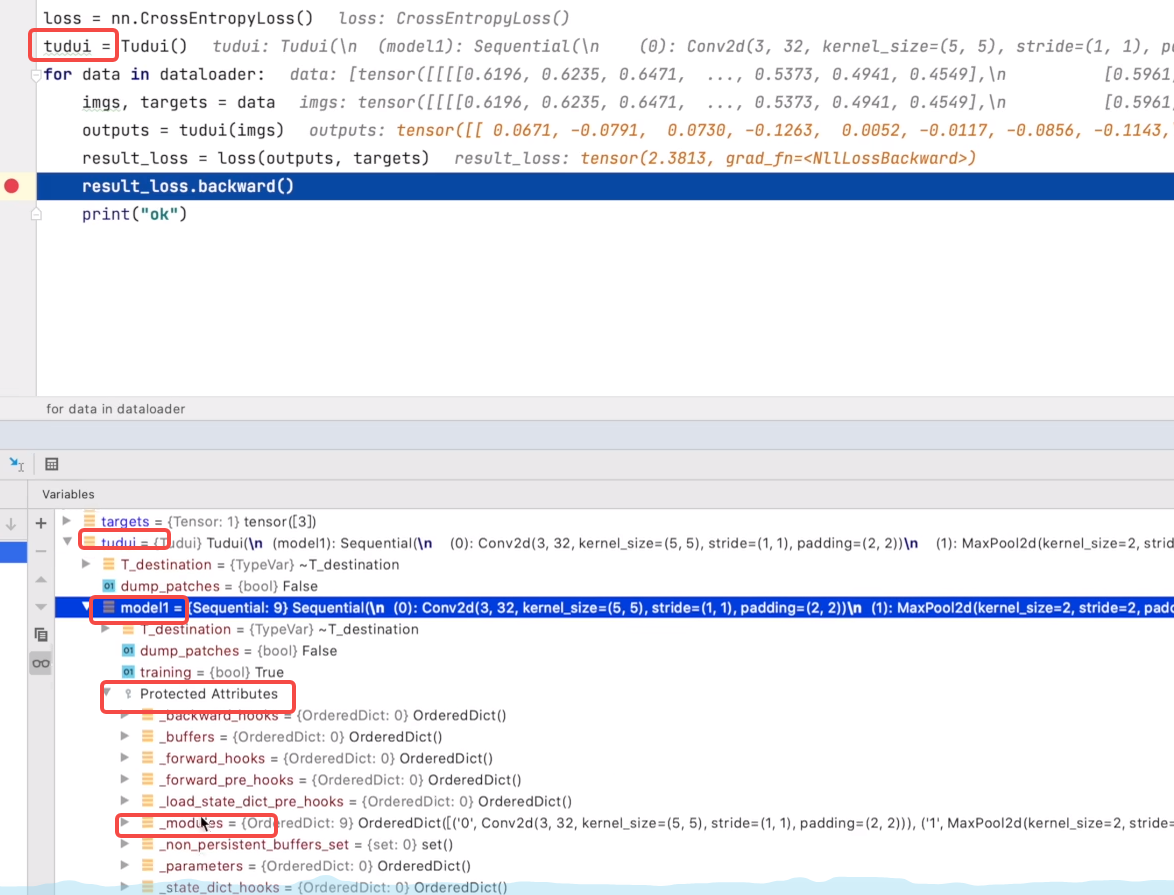
5 Loss和反向传播
P23损失函数与反向传播
https://pytorch.org/docs/stable/nn.html#loss-functions
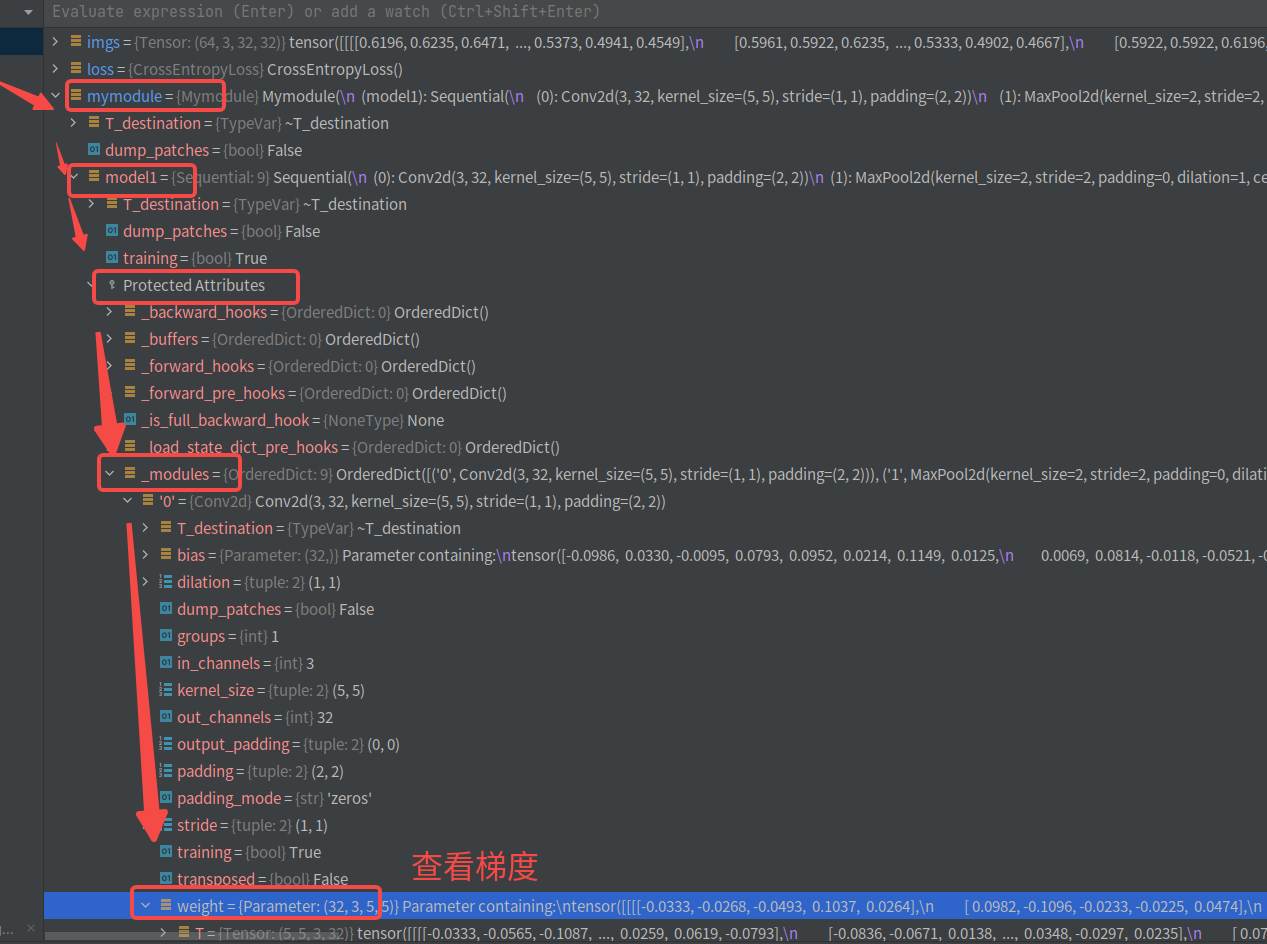
mymodule = Mymodule()# print(mymodule) # 输出网络结构loss = nn.CrossEntropyLoss()optim = torch.optim.SGD(mymodule.parameters(), lr=0.01)for data in dataloader:imgs, targets = dataoutput = mymodule(imgs)result_loss = loss(output, targets) # 损失函数=======================================================print(result_loss)#optim.zero_grad()result_loss.backward() # 反向传播得到梯度=====================================================optim.step() # 更新权重weight.data 对每个参数进行调优
nn.CrossEntropyLoss

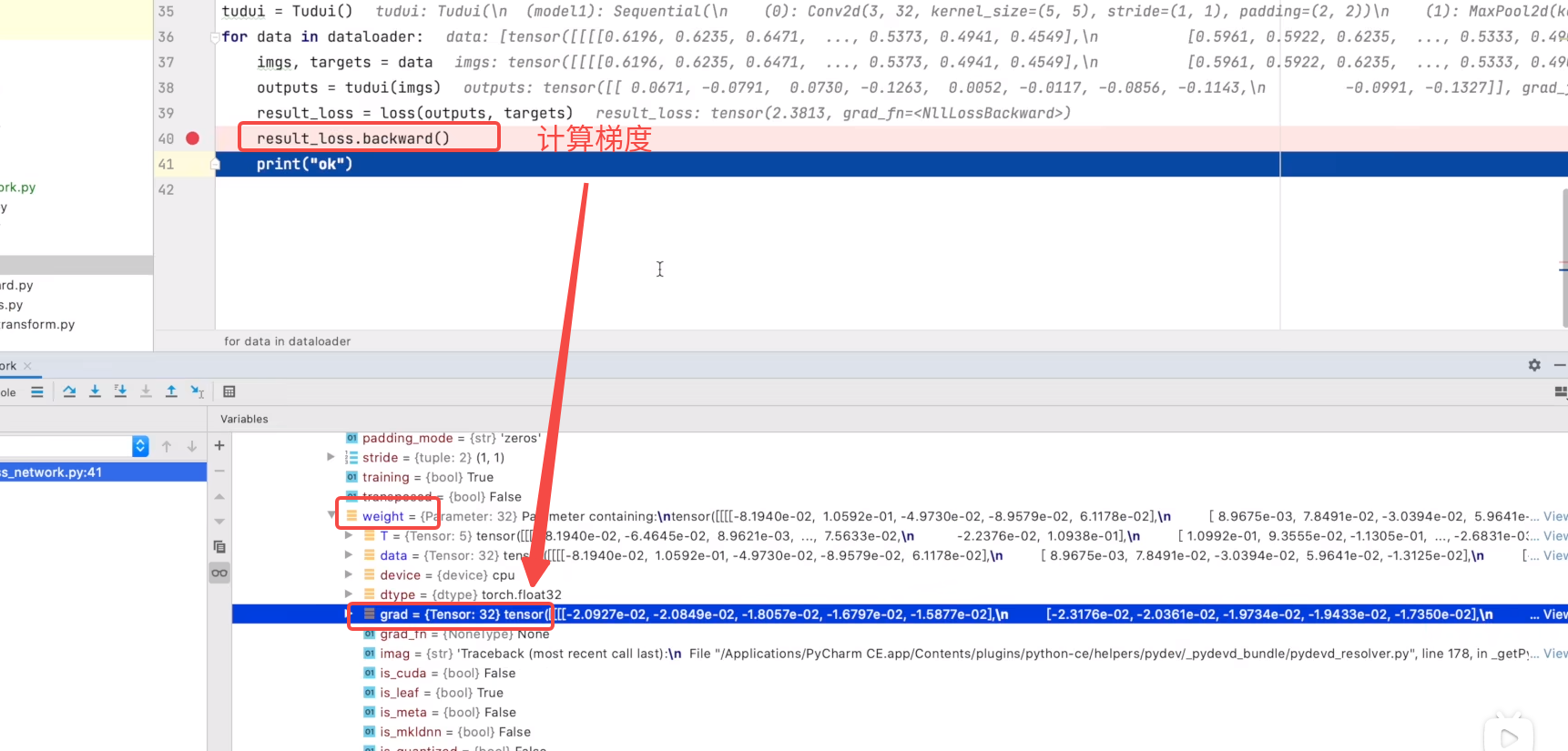
查看梯度(backward 得到梯度)
 |
 |
|---|---|
6 优化器 torch.optim
https://pytorch.org/docs/stable/optim.html
不是nn里的模块,而是torch.optim.SGD(mymodule.parameters(), lr=0.01)
torch.optim.SGD(mymodule.parameters(), lr=0.01)
https://pytorch.org/docs/stable/generated/torch.optim.SGD.html#torch.optim.SGD
mymodule = Mymodule()
# print(mymodule) # 输出网络结构
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(mymodule.parameters(), lr=0.01) # 优化器=================
for data in dataloader:
imgs, targets = data
output = mymodule(imgs)
result_loss = loss(output, targets)
print(result_loss)
#
optim.zero_grad()
result_loss.backward() # 反向传播得到梯度~~~~~~~~~~~~~~
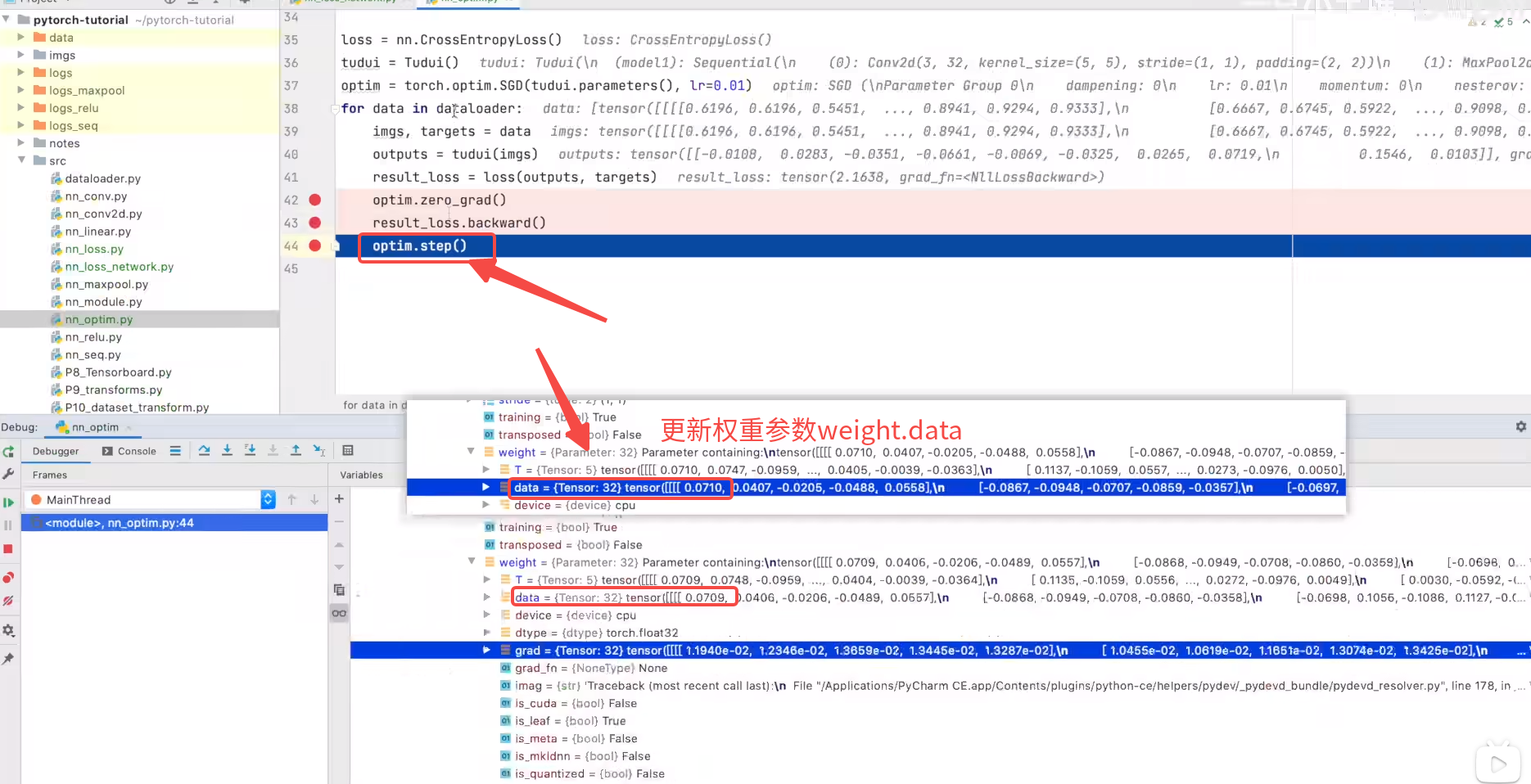
optim.step() # 更新权重weight.data 对每个参数进行调优
| 更新权重weight.data 对每个参数进行调优 | |
|---|---|
 |
 |
nn.LayerNorm 归一化
nn.Softmax(dim=-1)(scores) 总和为1
https://blog.csdn.net/weixin_41391619/article/details/104823086
nn.ReLU 激活函数
relu1 = nn.ReLU(inplace=True)
out = relu1(out)
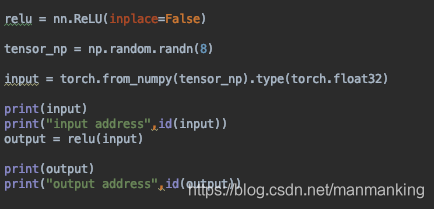
https://blog.csdn.net/manmanking/article/details/104830822
nn.Dropout(p=dropout) 随机失活
详解部分:
1.Dropout是为了防止过拟合而设置的
2.Dropout顾名思义有丢掉的意思
3.nn.Dropout(p = 0.3) # 表示每个神经元有0.3的可能性不被激活(将部分tensor中的值置为0)
4.Dropout只能用在训练部分而不能用在测试部分
5.Dropout一般用在全连接神经网络映射层之后,如代码的nn.Linear(20, 30)之后
————————————————
版权声明:本文为CSDN博主「深度之刃」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_47050107/article/details/122722516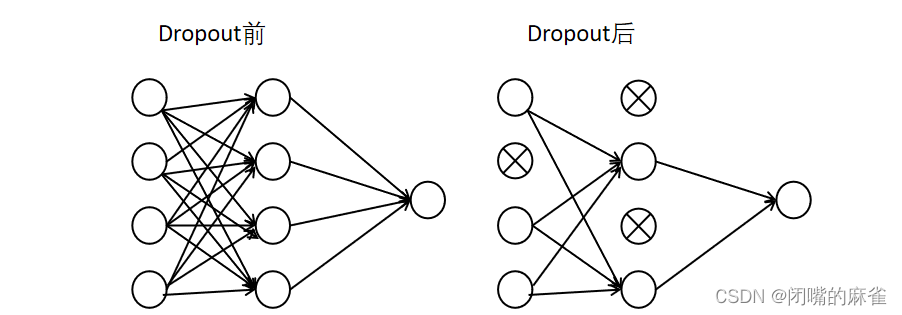
import torch
import torch.nn as nn
a = torch.randn(4, 4)
print(a)
"""
tensor([[ 1.2615, -0.6423, -0.4142, 1.2982],
[ 0.2615, 1.3260, -1.1333, -1.6835],
[ 0.0370, -1.0904, 0.5964, -0.1530],
[ 1.1799, -0.3718, 1.7287, -1.5651]])
"""
dropout = nn.Dropout()
b = dropout(a)
print(b)
"""
tensor([[ 2.5230, -0.0000, -0.0000, 2.5964],
[ 0.0000, 0.0000, -0.0000, -0.0000],
[ 0.0000, -0.0000, 1.1928, -0.3060],
[ 0.0000, -0.7436, 0.0000, -3.1303]])
"""
nn.Embedding 词嵌入
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) # 把字转换字向量(9, 512) # d_model = 512 # 字 Embedding 的维度
self.pos_emb = PositionalEncoding(d_model) # 加入位置信息!位置编码
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
翻译过来的意思就是词嵌入,通俗来讲就是将文字转换为一串数字。
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None,
max_norm=None, norm_type=2.0, scale_grad_by_freq=False,
sparse=False, _weight=None)
其为一个简单的存储固定大小的词典的嵌入向量的查找表,意思就是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。
输入为一个编号列表,输出为对应的符号嵌入向量列表
- num_embeddings (python:int) – 词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
embedding_dim (python:int) – 嵌入向量的维度,即用多少维来表示一个符号。 - padding_idx (python:int, optional) – 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
- max_norm (python:float, optional) – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
- norm_type (python:float, optional) – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
- scale_grad_by_freq (boolean, optional) – 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
- sparse (bool, optional) – 若为True,则与权重矩阵相关的梯度转变为稀疏张量。
作者:top_小酱油
链接:https://www.jianshu.com/p/63e7acc5e890
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Plus:nn.Sequential

Plus: nn.ModuleList
Last: GPU并行
| nn.DataParallel | Implements data parallelism at the module level. |
|---|---|
| nn.parallel.DistributedDataParallel | Implements distributed data parallelism that is based on torch.distributed package at the module level. |
nn.DataParallel
nn.parallel.DistributedDataParallel

若有收获,就点个赞吧
0 人点赞
