各位题友大家好,今天是 @负雪明烛 坚持日更的第 18 天。今天力扣上的每日一题是「703. 数据流中的第 K 大元素」。
解题思路
面试题警告:
- 本题「数据流中的 TopK」是我参加亚马逊面试遇到过的真题。
- 另外,实现堆算法是我参加微软面试遇到的真题。
- 多说一句,TopK 算法在面试中常问,推荐阅读「拜托,面试别再问我TopK了!!!」
本题是我们求在一个数据流中的第  大元素。所谓数据流,即是说我们写的算法需要支持
大元素。所谓数据流,即是说我们写的算法需要支持 add() 函数,每次调用这个函数,都会向我们写的算法中添加一个元素。而题目要求的就是在每次 add() 之后,整个数据流(包括初始化的元素和所有 add 进来的元素)中的第 K 大元素。
先说一个最暴力的解法:我们底层数据结构使用数组实现,当每次调用 add() 函数时,向数组中添加一个元素,然后调用 sort() 函数进行排序,返回排序后数组的第 个数字。该做法在每次调用 add() 函数时的时间复杂度为  ,该时间复杂度太高,当 很大/
,该时间复杂度太高,当 很大/ add()调用次数太多的时候,一定会超时。
从上面的分析中,我们已经看出来了,使用数组的核心问题是:数组自身不带排序功能,只能用 sort() 函数,导致时间复杂度过高。
因此我们考虑使用自带排序功能的数据结构——堆。
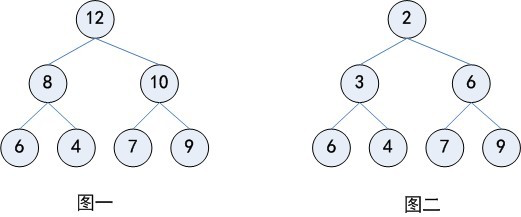
在大根堆(图一)中,父节点的值比每一个子节点的值都要大。在小根堆(图二)中,父节点的值比每一个子节点的值都要小。
本题的操作步骤如下:
- 使用大小为 的小根堆,在初始化的时候,保证堆中的元素个数不超过 。
- 在每次
add()的时候,将新元素push()到堆中,如果此时堆中的元素超过了,那么需要把堆中的最小元素(堆顶)pop()出来。 - 此时堆中的最小元素(堆顶)就是整个数据流中的第 大元素。
问答:
1. 为什么使用小根堆?
- 因为我们需要在堆中保留数据流中的前 大元素,使用小根堆能保证每次调用堆的
pop()函数时,从堆中删除的是最小的元素(堆顶)。
- 为什么能保证堆顶元素是第 大元素?
- 因为小根堆中保留的一直是堆中的前 大的元素,堆的大小是 ,所以堆顶元素是第 大元素。
- 每次
add()的时间复杂度是多少?
- 每次
add()时,调用了堆的push()和pop()方法,两个操作的时间复杂度都是 .
.
代码
使用 Python2 写的代码如下。
class KthLargest(object):def __init__(self, k, nums):""":type k: int:type nums: List[int]"""self.k = kself.que = numsheapq.heapify(self.que)def add(self, val):""":type val: int:rtype: int"""heapq.heappush(self.que, val)while len(self.que) > self.k:heapq.heappop(self.que)return self.que[0]# Your KthLargest object will be instantiated and called as such:# obj = KthLargest(k, nums)# param_1 = obj.add(val)
刷题心得
- 本题是堆的经典运用,在面试中可能会遇到,请认真对待本题,包括「TopK问题」;
2. 数据流的题目还是很有意思的,力扣上有其他数据流题目,建议也做一下。
参考资料:
1. 图源
2. 拜托,面试别再问我TopK了!!!
3. 负雪明烛博客:703. Kth Largest Element in a Stream
4. 【LeetCode】代码模板,刷题必会
OK,以上就是 @负雪明烛 写的今天题解的全部内容了,如果你觉得有帮助的话,求赞、求关注、求收藏。如果有疑问的话,请在下面评论,我会及时解答。
祝大家过年好!我们明天再见!

若有收获,就点个赞吧
0 人点赞
