各位题友大家好! 今天是 @负雪明烛 坚持日更的第 48 天。今天力扣上的每日一题是「705. 设计哈希集合」。
解题思路
本题是让我们设计哈希集合(HashSet)。HashSet 是指能 $O(1)$ 时间内进行插入和删除,可以保存不重复元素的一种数据结构。
HashSet 是在 时间和空间 上做平衡的经典例子:如果不考虑空间,我们可以直接设计一个超大的数组,使每个key 都有单独的位置,则不存在冲突;如果不考虑时间,我们可以直接用一个无序的数组保存输入,每次查找的时候遍历一次数组。
为了时间和空间上的平衡,HashSet 基于数组实现,并通过 hash 方法求键 key 在数组中的位置,当 hash 后的位置存在冲突的时候,再解决冲突。
设计 hash 函数需要考虑两个问题:
1. 通过 hash 方法把键 key 转成数组的索引:设计合适的 hash 函数,一般都是对分桶数取模 % 。
2. 处理碰撞冲突问题:拉链法 和 线性探测法。
下面我用了两个方法:
- 超大数组:简便。
- 拉链法:大多数编程语言选择的方法。
超大数组
能使用超大数组来解决本题是因为输入数据的范围在 $0 <= key <= 10^6$ 。因此我们只需要 $10^6 + 1$大小的数组,就能让每个数据都有一个单独的索引,不会有 key 的碰撞问题。
因为对于 HashSet 来说,我们只需要关注一个 key 是否存在,而不是 key:value 形式的 HashMap,因此,我们把数组的元素设计成 bool 型的,当某个 key 的对应的数组中的位置取值为 true 说明该 key 存在,取值为 false,说明该 key 不存在。
优点:查找和删除的性能非常快,只用访问 1 次数组;
- 缺点:使用了非常大的空间,当元素范围很大时,无法使用该方法;当存储的元素个数较少时,性价比极低;需要预知数据的取值范围。class MyHashSet:def __init__(self):self.set = [False] * 1000001def add(self, key):self.set[key] = Truedef remove(self, key):self.set[key] = Falsedef contains(self, key):return self.set[key]
时间复杂度:$O(1)$
- 空间复杂度:$O(数据范围)$
拉链法
如果在面试中,面试官一定不会满意上面的解法,刷力扣是为了面试,不是为了 AC,所以我们应该写出让面试官满意的代码。那么基于「拉链法」的 HashSet 也务必要掌握。
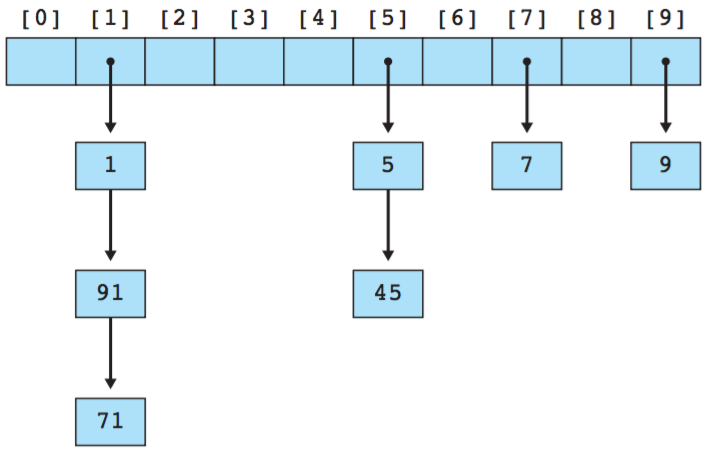
拉链法是说,我们定义了一个比较小的数组,然后使用 hash 方法来把求出 key 应该出现在数组中的位置;但是由于不同的 key 在求完 hash 之后,可能会存在碰撞冲突,所以数组并不直接保存元素,而是每个位置都指向了一条链表(或数组)用于存储元素。
我们可以看出在查找一个 key 的时候需要两个步骤:① 求hash到数组中的位置;② 在链表中遍历找key。
- 优点:我们可以把数组大小设计比较合理,从而节省空间;不用预知 key 的范围;方便扩容。
- 缺点:所以需要多次访问内存,性能上比超大数组的 HashSet 差;需要设计合理的 hash 方法从而避免冲突;如果链表比较长,则退化成 $O(N)$ 的查找;实现比较复杂;
在下面的具体实现中,我把拉链设计成了基于「数组」的实现。此时「拉链数组」有两种设计方法:①定长拉链数组;②不定长拉链数组。
定长拉链数组
这个方法本质上就是一个 M * N 的二维数组。第一个维度用于计算 hash 分桶,第二个维度寻找 key 存放具体的位置。但是做了一个优化,就是第二个维度的数组只有当需要构建第二个维度的数组时,才会产生,可以节省内存。
- 优点:两个维度都可以直接计算出来,查找和删除只用两次访问内存。
- 缺点:需要预知数据范围,用于设计第二个维度的数组大小。
class MyHashSet:def __init__(self):self.buckets = 1000self.itemsPerBucket = 1001self.table = [[] for _ in range(self.buckets)]def hash(self, key):return key % self.bucketsdef pos(self, key):return key // self.bucketsdef add(self, key):hashkey = self.hash(key)if not self.table[hashkey]:self.table[hashkey] = [0] * self.itemsPerBucketself.table[hashkey][self.pos(key)] = 1def remove(self, key):hashkey = self.hash(key)if self.table[hashkey]:self.table[hashkey][self.pos(key)] = 0def contains(self, key):hashkey = self.hash(key)return (self.table[hashkey] != []) and (self.table[hashkey][self.pos(key)] == 1)
- 时间复杂度:$O(1)$
- 空间复杂度:$O(数据范围)$
不定长拉链数组
不定长的拉链数组是说拉链会根据分桶中的 key 动态增长,更类似于真正的链表。
分桶数一般取质数,这是因为经验上来说,质数个的分桶能让数据更加分散到各个桶中。
- 优点:节省内存,不用预知数据范围;
- 缺点:在链表中查找元素需要遍历。
class MyHashSet:def __init__(self):self.buckets = 1009self.table = [[] for _ in range(self.buckets)]def hash(self, key):return key % self.bucketsdef add(self, key):hashkey = self.hash(key)if key in self.table[hashkey]:returnself.table[hashkey].append(key)def remove(self, key):hashkey = self.hash(key)if key not in self.table[hashkey]:returnself.table[hashkey].remove(key)def contains(self, key):hashkey = self.hash(key)return key in self.table[hashkey]
- 时间复杂度:$O(1)$
- 空间复杂度:$O(数据个数)$
在实际测试中,发现「不定长拉链数组」法速度最快,我的理解是,大块的内存分配也是需要时间的。因此避免大块的内存分配,也是在节省时间。
刷题心得
从上面的设计上来看,我们发现,设计一个 HashSet 是在时间和空间上寻求平衡的过程。在写本题解前,我复习了《算法 第4版》的散列表章节(293页),非常经典,收获很大。我的题解的内容范围和质量不及《算法 第4版》的十之一二,强烈建议大家通过阅读经典书籍来系统地学习算法。
参考资料:
1. 《算法 第4版》
2. 图源
OK,以上就是 @负雪明烛 写的今天题解的全部内容了,如果你觉得有帮助的话,求赞、求关注、求收藏。如果有疑问的话,请在下面评论,我会及时解答。
关注我,你将不会错过我的精彩动画题解、面试题分享、组队刷题活动,进入主页 @负雪明烛 右侧有刷题组织,从此刷题不再孤单。
祝大家牛年大吉!AC 多多,Offer 多多!我们明天再见!

若有收获,就点个赞吧
0 人点赞
