各位题友大家好! 我是 @负雪明烛 。
解题思路
今天题目重点只有一个:二叉搜索树(BST)。
遇到二叉搜索树,立刻想到这句话:
「二叉搜索树(BST)的中序遍历是有序的」。
这是解决所有二叉搜索树问题的关键。
题目要求 BST 中第 k 小的元素,等价于求 BST 中序遍历的第 k 个元素。
分享二叉树遍历的模板:先序、中序、后序遍历方式的区别在于把「执行操作」放在两个递归函数的位置。
伪代码在下面。
- 先序遍历:
def dfs(root):if not root:return执行操作dfs(root.left)dfs(root.right)
- 中序遍历:
def dfs(root):if not root:returndfs(root.left)执行操作dfs(root.right)
- 后序遍历:
def dfs(root):if not root:returndfs(root.left)dfs(root.right)执行操作
本题是使用了中序遍历,所以把「执行操作」这一步改成自己想要的代码。
于是有了下面两种写法。
方法一:数组保存中序遍历结果
这个方法是最直观的,也最不容易出错的。
- 先中序遍历,把结果放在数组中;
- 最后返回数组的第 k 个元素。
对应的代码如下,二叉树的各种遍历方式是基本功,务必要掌握。
Java / C++ / Python 三种语言的代码如下:
public class Solution {List<Integer> list;public int kthSmallest(TreeNode root, int k) {list = new ArrayList<Integer>();dfs(root);return list.get(k - 1);}public void dfs(TreeNode root){if(root == null){return;}dfs(root.left);list.add(root.val);dfs(root.right);}}
class Solution {public:int kthSmallest(TreeNode* root, int k) {vector<int> res;dfs(root, res);return res[k - 1];}void dfs(TreeNode* root, vector<int>& res) {if (!root) return;dfs(root->left, res);res.push_back(root->val);dfs(root->right, res);}};
class Solution(object):def kthSmallest(self, root, k):res = []self.dfs(root, res)return res[k - 1]def dfs(self, root, res):if not root: returnself.dfs(root.left, res)res.append(root.val)self.dfs(root.right, res)
复杂度分析:
- 时间复杂度:$O(N)$,因为每个节点只访问了一次;
- 空间复杂度:$O(N)$,因为需要数组保存二叉树的每个节点值。
方法二:只保存第 k 个节点
在方法一中,我们保存了整个中序遍历数组,比较浪费空间。
其实我们只需要知道,在中序遍历的时候,第 k 个被访问的节点即可。访问到第 k 个节点后,递归终止,后面的节点就不用访问了。
下图展示了中序遍历过程中的节点访问顺序。
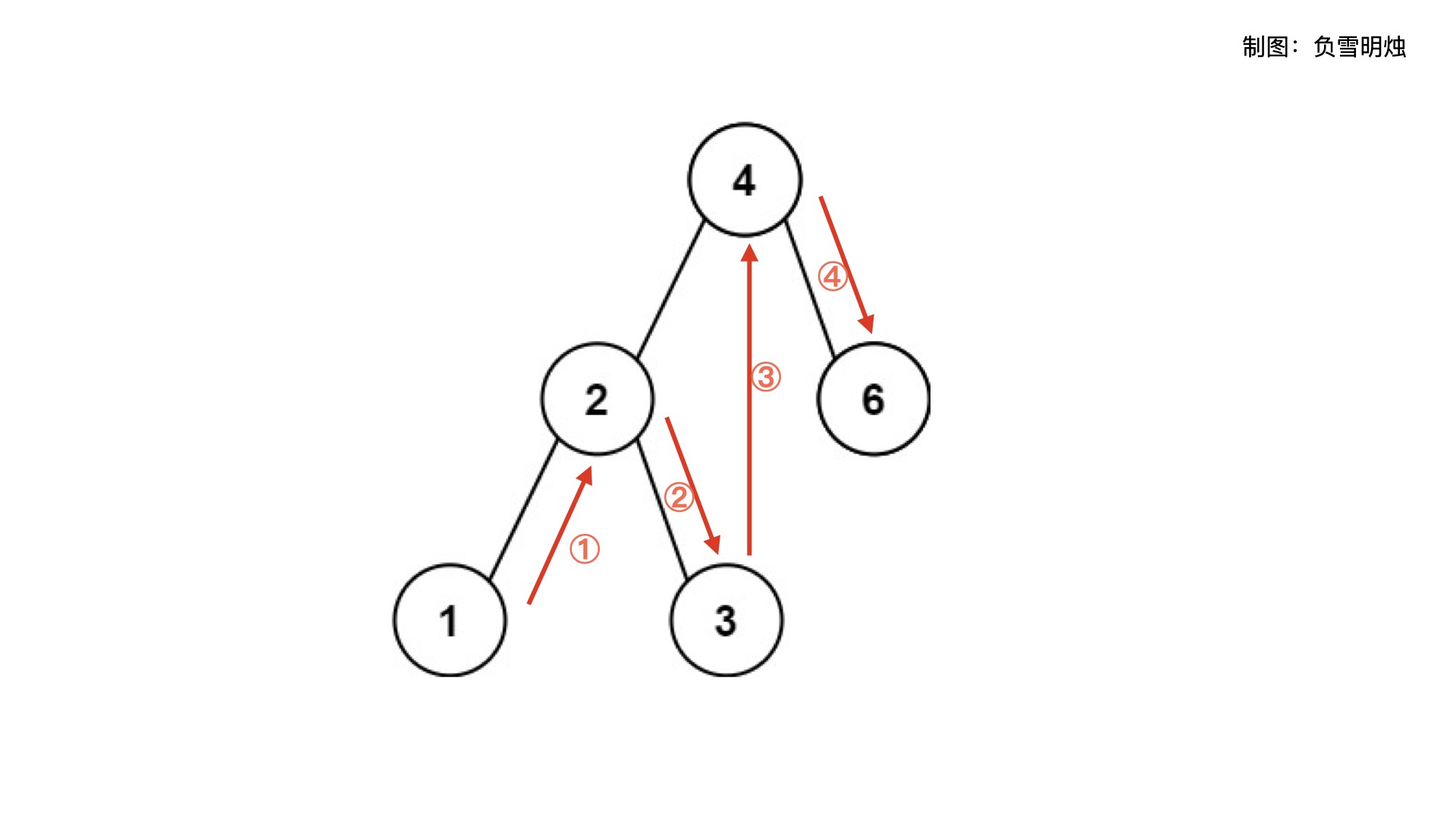
具体的做法中,我们需要需要两个变量:
- 用一个全局变量保存最终的结果;
- 用一个全局变量保存当前访问到第几个节点。
如果不使用全局变量,而是使用函数传参,需要注意「值传递」和「引用传递」的区别:每个递归的内部都需要对同一个变量修改,如果用普通函数的传参,对于 int 型的参数,使用的是值传递,即拷贝了一份传到了函数里面。那么函数里面对 int 型的修改不会影响外边的变量。
使用全局变量,可以保证递归函数的每次修改都是反映到全局的,从而保证遍历到第 k 个的时候,所有的递归立刻停止。
Java / C++ / Python 三种语言的代码如下:
public class Solution {int res;int count;public int kthSmallest(TreeNode root, int k) {res = 0;count = k;dfs(root);return res;}public void dfs(TreeNode root){if(root == null){return;}dfs(root.left);count--;if(count == 0){res = root.val;return;}dfs(root.right);}}
class Solution {public:int kthSmallest(TreeNode* root, int k) {count = k;dfs(root);return res;}void dfs(TreeNode* root) {if (!root) return;dfs(root->left);count -= 1;if (count == 0) {res = root->val;return;}dfs(root->right);}private:int res;int count;};
class Solution(object):def kthSmallest(self, root, k):self.res = 0self.count = kself.dfs(root)return self.resdef dfs(self, root):if not root: returnself.dfs(root.left)self.count -= 1if self.count == 0:self.res = root.valreturnself.dfs(root.right)
- 时间复杂度:$O(k)$,因为只访问了前 k 个节点;
- 空间复杂度:$O(h)$,其中 $h$ 为树的高度,因为递归用了系统栈,而栈的深度最多只有树的高度。
总结
- 二叉树的多种遍历方式必须要掌握。
- 一定切记:二叉搜索树的中序遍历是有序的。
- 另外建议刚开始刷题的朋友,不妨从二叉树上手。
类似题目:
我是 @负雪明烛 ,刷算法题 1000 多道,写了 1000 多篇算法题解,收获阅读量 300 万。
关注我,你将不会错过我的精彩动画题解、面试题分享、组队刷题活动,进入主页 @负雪明烛 右侧有刷题组织,从此刷题不再孤单。
- 在刷题的时候,如果你不知道该怎么刷题,可以看 LeetCode 应该怎么刷?
- 如果你觉得题目太多,想在短时间内快速提高,可以看 LeetCode 最经典的 100 道题。

若有收获,就点个赞吧
0 人点赞
