什么是 DOM
从网络传给渲染引擎的 HTML 文件字节流是无法直接被渲染引擎理解的,所以要将其转化为渲染引擎能够理解的内部结构,这个结构就是 DOM 。DOM 提供了对 HTML 文档结构化的表述。在渲染引擎中, DOM 有三个层面的作用:
- 从页面的视角来看,DOM 是生成页面的基础数据结构。
- 从 JavaScript 脚本视角来看, DOM 提供给 JavaScript 脚本操作的接口,通过这套接口, JavaScript 可以对 DOM 结构进行访问,从而改变文档的结构、样式和内容。
- 从安全视角来看, DOM 是一道安全防护线,一些不安全的内容在 DOM 解析阶段就被拒之门外了。
简言之,DOM 是表述 HTML 的内部数据结构,它会将 Web 页面和 JavaScript 脚本连接起来,并过滤一些不安全的内容。
HTML 解析器并不是等整个文档加载完成之后再解析的,而是网络进程加载了多少数据, HTML 解析器便解析多少数据。
DOM树的生成
字节流转换为 DOM 需要三个阶段。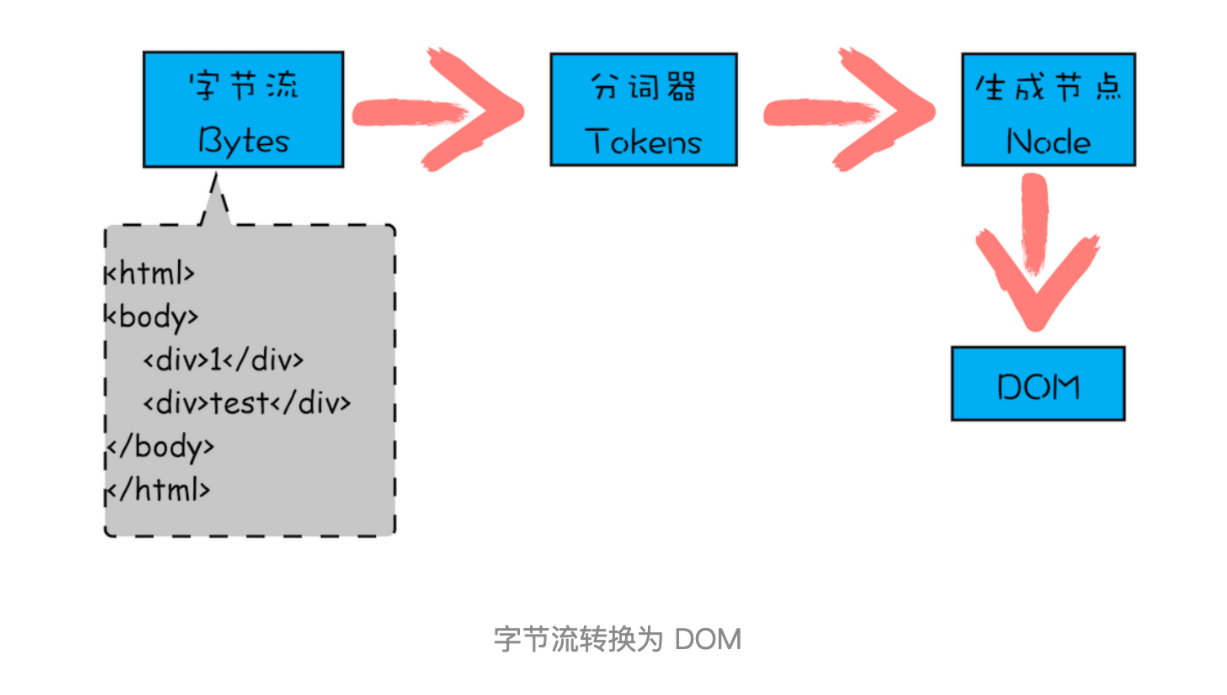
第一个阶段,通过分词器将字节流转换为 Token
解析 HTML 需要通过分词器先将字节流转换为一个个 Token ,分为 Tag Token 和文本 Token 。上述 HTML 代码通过词法分析生成的 Token 如下所示: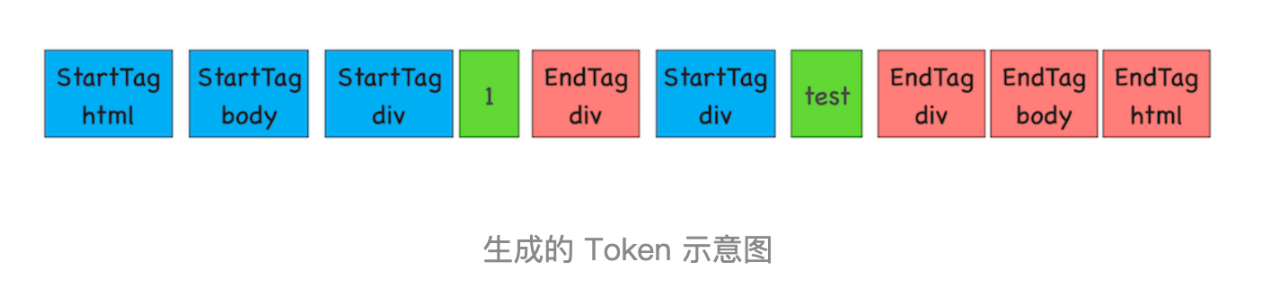
至于后续的第二个和第三个阶段是同步进行的,需要将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中。
HTML 解析器维护了一个 Token 栈结构,该 Token 栈主要用来计算节点之间的父子关系,在第一个阶段中生成的 Token 会被按照顺序压到这个栈中。具体的处理规则如下所示:
- 如果压入到栈中的是 StartTag Token ,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中,它的父节点就是栈中相邻的那个元素生成的节点。
- 如果分词器解析出来是文本 Token ,那么会生成一个文本节点,然后将该节点加入到 DOM 树中,文本 Token 是不需要压入到栈中,它的父节点就是当前栈顶 Token 所对应的 DOM 节点。
- 如果分词器解析出来的是 EndTag 标签,比如是 EndTag div , HTML 解析器会查看 Token 栈顶的元素是否是 StartTag div ,如果是,就将 StartTag div 从栈中弹出,表示该 div 元素解析完成。
如何理解DOM0,DOM2,DOM3
W3C 协会早在 1988 年就开始了 DOM 标准的制定, W3C DOM 标准可以分为 DOM1,DOM2, DOM3 三个版本.
DOM1级主要定义的是 HTML 和 XML 文档的底层结构。
DOM2 和 DOM3 级则在这个结构的基础上引入了更多的交互能力,也支持了更高级的 XML 特性。为此 DOM2级 和 DOM3级 分为许多模块(模块之间具有某种关联),分别描述了 DOM 的某个非常具体的子集。这些模块如下:
- DOM2级核心(DOM Level 2 Core):在1级核心的基础上构建,为节点添加了更多方法和属性;
- DOM2级视图(DOM Level 2 Views):为文档定义了基于样式信息的不同视图;
- DOM2级事件(DOM Level 2 Style):定义了如何以编程方式来访问和改变CSS样式信息;
- DOM2级遍历和范围(DOM Level 2 Traversal and Range):引入了遍历DOM文档和选择其特定部分的新接口;
- DOM2级HTML(DOM Level 2 HTML):在1级HTML基础上构建、添加了更多属性、方法和新接口;
- DOM3级又增加了XPath模块和加载与保存(Load and Save)模块。
DOM2级和3级的目的在于扩展DOM API,以满足操作XML的所有需求,同时提供更好的错误处理及特性检测能力。
操作DOM对性能的影响
访问 DOM 元素是有代价的。修改元素的代价则更大,因为会导致浏览器重新计算页面的几何变化。
所以应该尽量避免访问或修改元素。
优化的方法:
- 减少访问 DOM 的次数,把运算留给 JS,比如: ```javascript // 优化前 function innerHTMLLoop() { for (var count = 0; count < 15000; count++) { document.getElementById(‘here’).innerHTML += ‘a’; } }
// 优化后 function innerHTMLLoop2() { var content = ‘’; for(var count = 0; count < 15000; count++) { content += ‘a’; } document.getElementById(‘here’).innerHTML += content; }
- 用 element.cloneNode 替代 document.createElement() ,这个在旧版浏览器表现得比较明显- 当遍历一个集合时,把集合存储在局部变量中,并把 length 缓存在循环外部,然后使用局部变量替代这些需要多次读取的元素,看下面的优化三部曲:```javascript// 较慢function collectionGlobal() {var coll = document.getElementsByTagName('div'),len = coll.length,name = '';for(var count = 0; count < len; count++) {name = document.getElementsByTagName('div')[count].nodeName;name = document.getElementsByTagName('div')[count].nodeType;name = document.getElementsByTagName('div')[count].tagName;}return name;};// 较快function collectionLocal() {var coll = document.getElementsByTagName('div'),len = coll.length,name = '';for(var count = 0; count < len; count++) {name = coll[count].nodeName;name = coll[count].nodeType;name = coll[count].tagName;}return name;};// 最快function collectionNOdesLocal() {var coll = document.getElementsByTagName('div'),len = coll.length,name = '',el = null;for(var count = 0; count < len; count++) {el = coll[count];name = el.nodeName;name = el.nodeType;name = el.tagName;}return name;};

若有收获,就点个赞吧
0 人点赞
