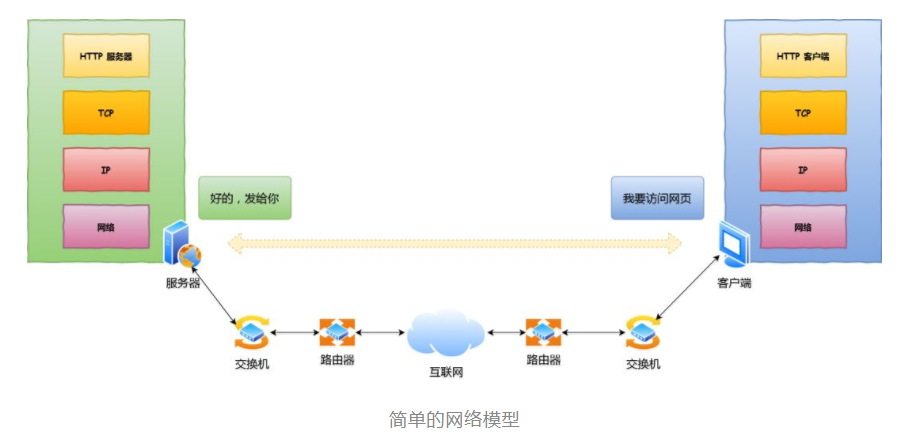
- 域名解析,发起 TCP 的三次握手,建立 TCP 连接后发起 HTTP 请求,向服务端请求页面
- 把请求回来的 HTML 代码经过解析,构建成 DOM Tree ,同时将 CSS 解析成 CSSOM Tree
- 将 DOM Tree 和 CSSOM Tree 合并成 Render Tree
- 生成布局 Layout,计算 Render Tree 中元素的尺寸、位置
- 将Render Tree 绘制成像素点,最后显示再屏幕上
浏览器内有多个进程,其中渲染进程被称为浏览器内核,负责页面渲染和执行 JS 脚本等。渲染进程负责浏览器的解析和渲染,内部有 JS引擎线程、GUI渲染线程、事件循环管理线程、定时器线程、HTTP线程。
JS引擎线程负责执行JS脚本,GUI渲染线程负责页面的解析和渲染,两者是互斥的,也就是执行JS的时候页面是停止解析和渲染的。这是因为如果页面渲染的同时JS引擎修改了页面元素,比如清空页面,会造成后续页面渲染的不必要错误。而由于JS经常要操作DOM,就要涉及JS引擎线程和GUI渲染线程的通信,而线程间通信代价是非常昂贵的,这也是造成JS操作DOM效率不高的原因。
浏览器的HTML/CSS的解析和渲染都属于 GUI渲染线程,所以和 JS引擎线程是互斥、阻塞的。
解析URL
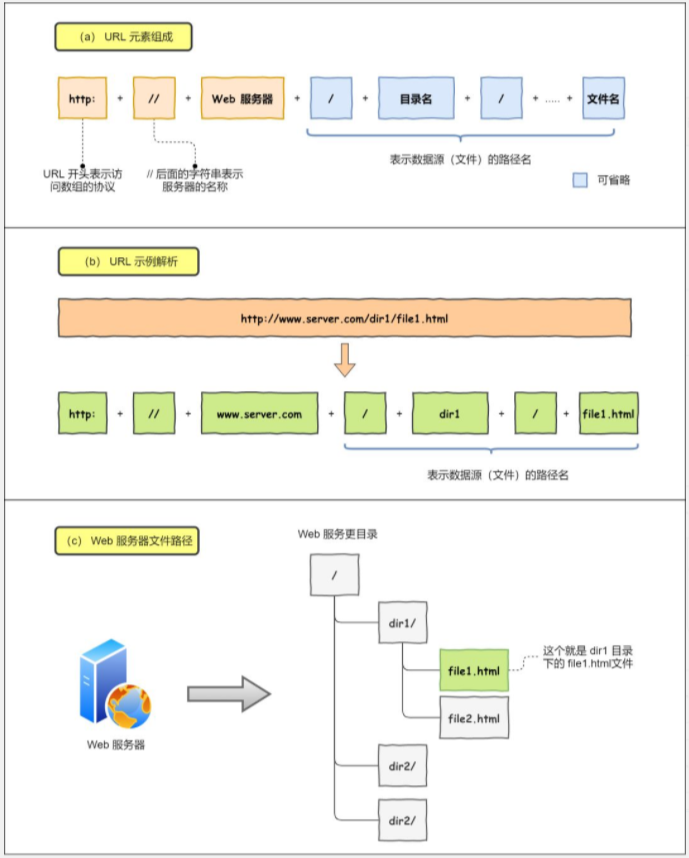
要是上图的蓝色部分省略掉,就代表访问根目录下事先设置的默认文件,也就是 /index.html 或者 /default.html 这些文件。
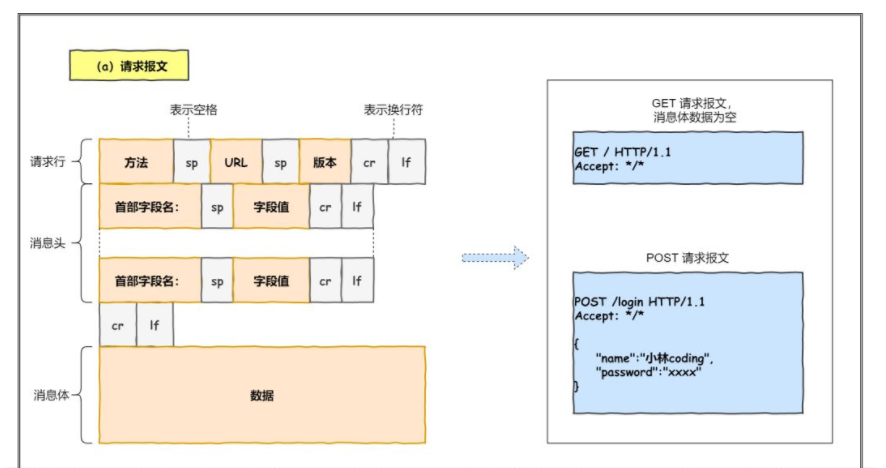
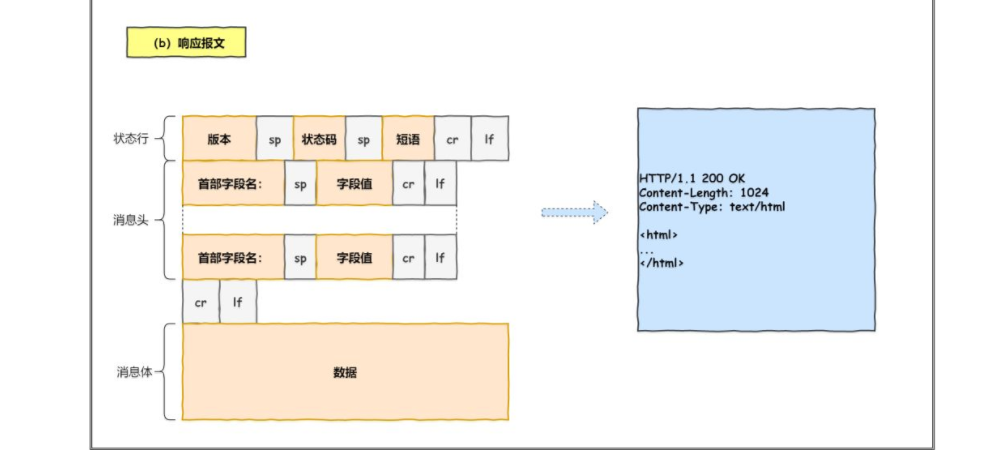
生成 HTTP 请求信息
DNS
通过浏览器解析 URL 并生成 HTTP 消息后,需要委托操作系统将消息发给 Web 服务器。
但在发送之前,还有一项工作需要完成,那就是查询服务器域名对应的 IP 地址。
DNS 就是通过域名查找 IP 地址,或逆向从 IP 地址反查域名的服务。
域名解析的工作流程: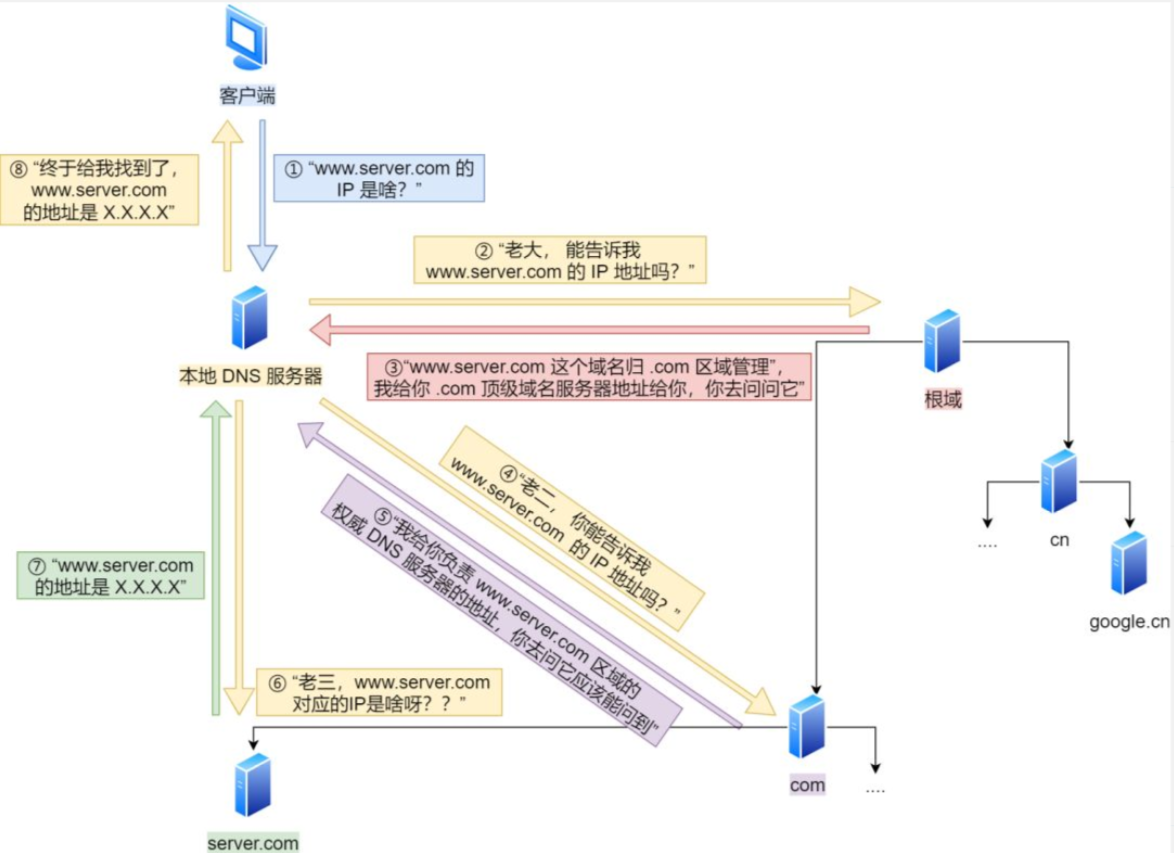
DNS 应用
- CDN :就是利用 DNS 的重定向技术, DNS 服务器会返回一个跟用户最接近的点的 IP 地址给用户, CDN 节点的服务器负责响应用户的请求,提供所需的内容。
- dns-prefetch :是一种 DNS 预解析技术。当你浏览网页时,浏览器会在加载网页时对网页中的域名进行解析缓存,这样在你单击当前网页中的连接时就无需进行 DNS 的解析,减少用户等待时间,提高用户体验。
协议栈
通过 DNS 获取到 IP 后,就可以把 HTTP 的传输工作交给操作系统中的协议栈。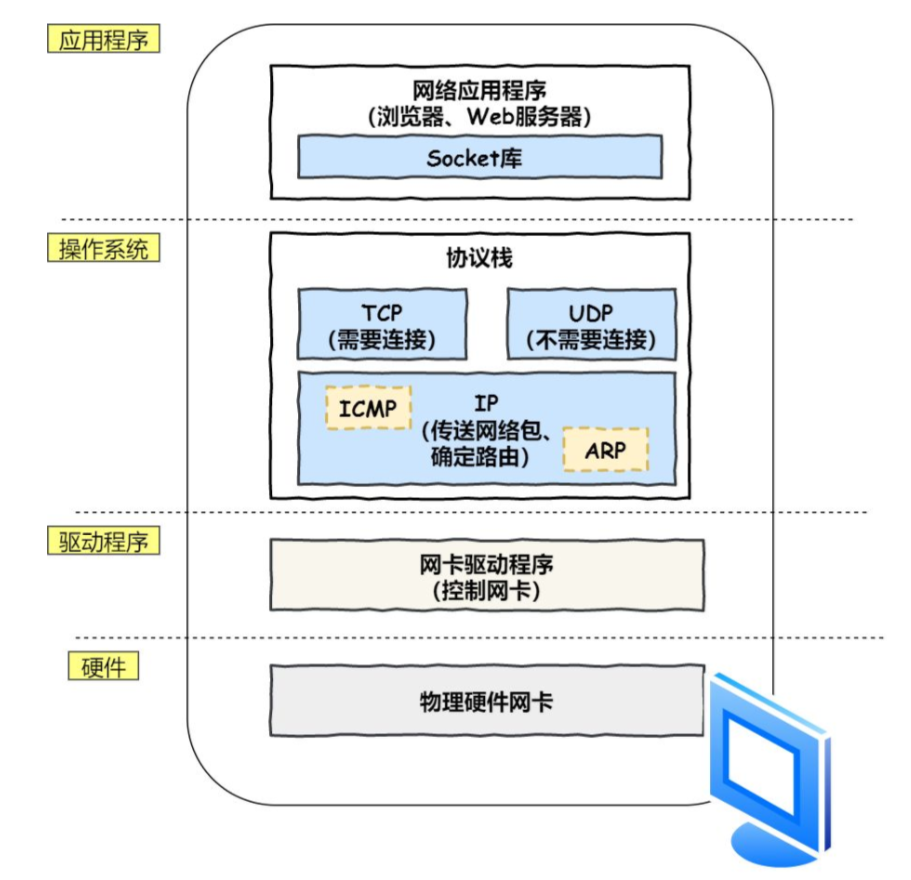
TCP
HTTP 是基于 TCP 协议传输的,所以在这我们先了解下 TCP 协议。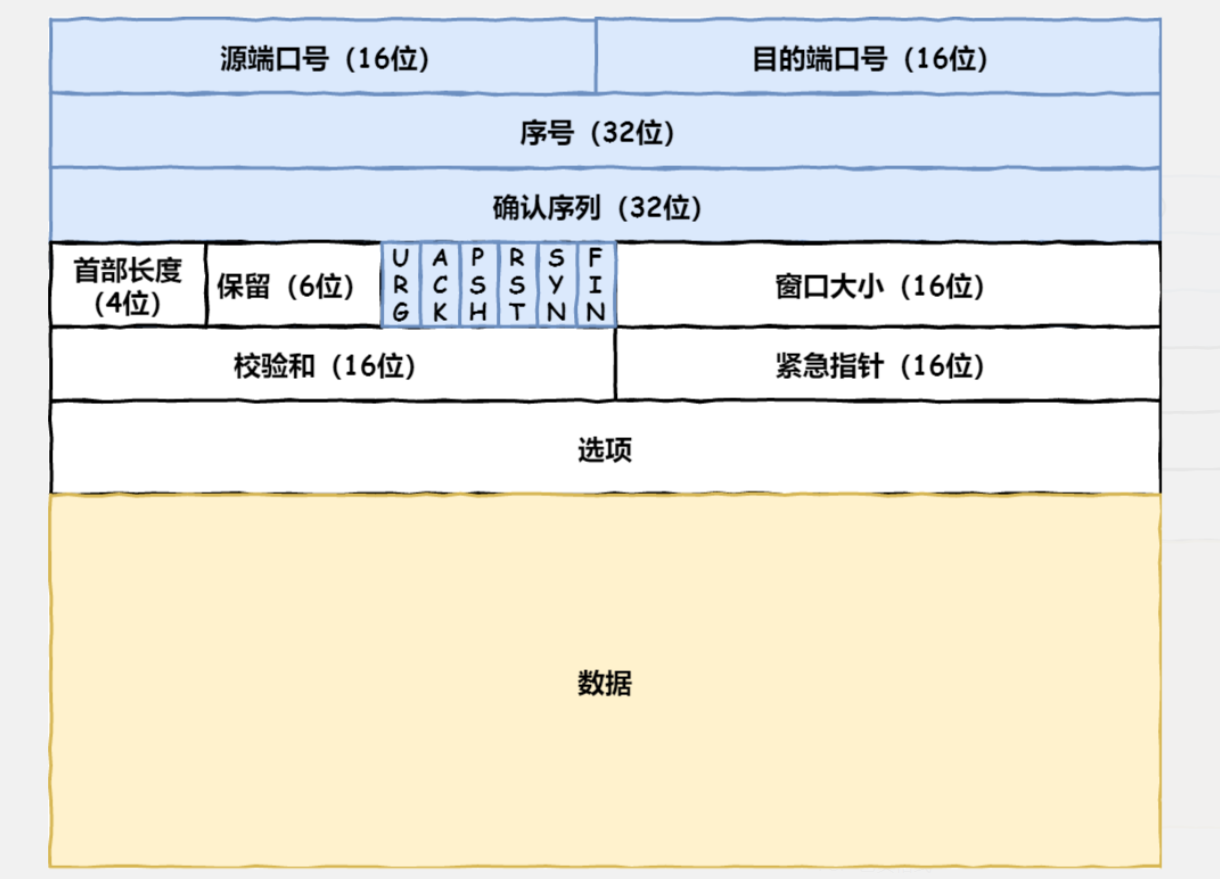 TCP报头格式
TCP报头格式
TCP 传输数据之前,要先三次握手建立连接。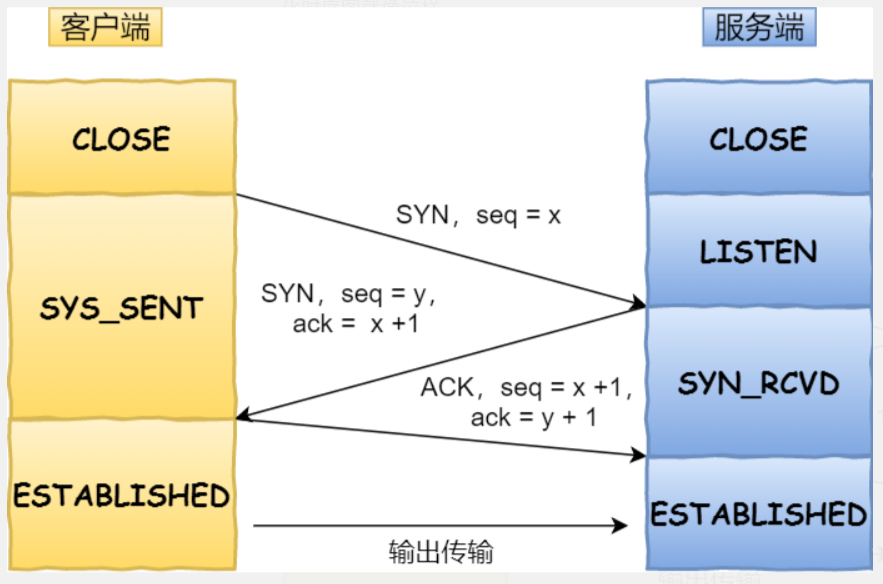 TCP 三次握手
TCP 三次握手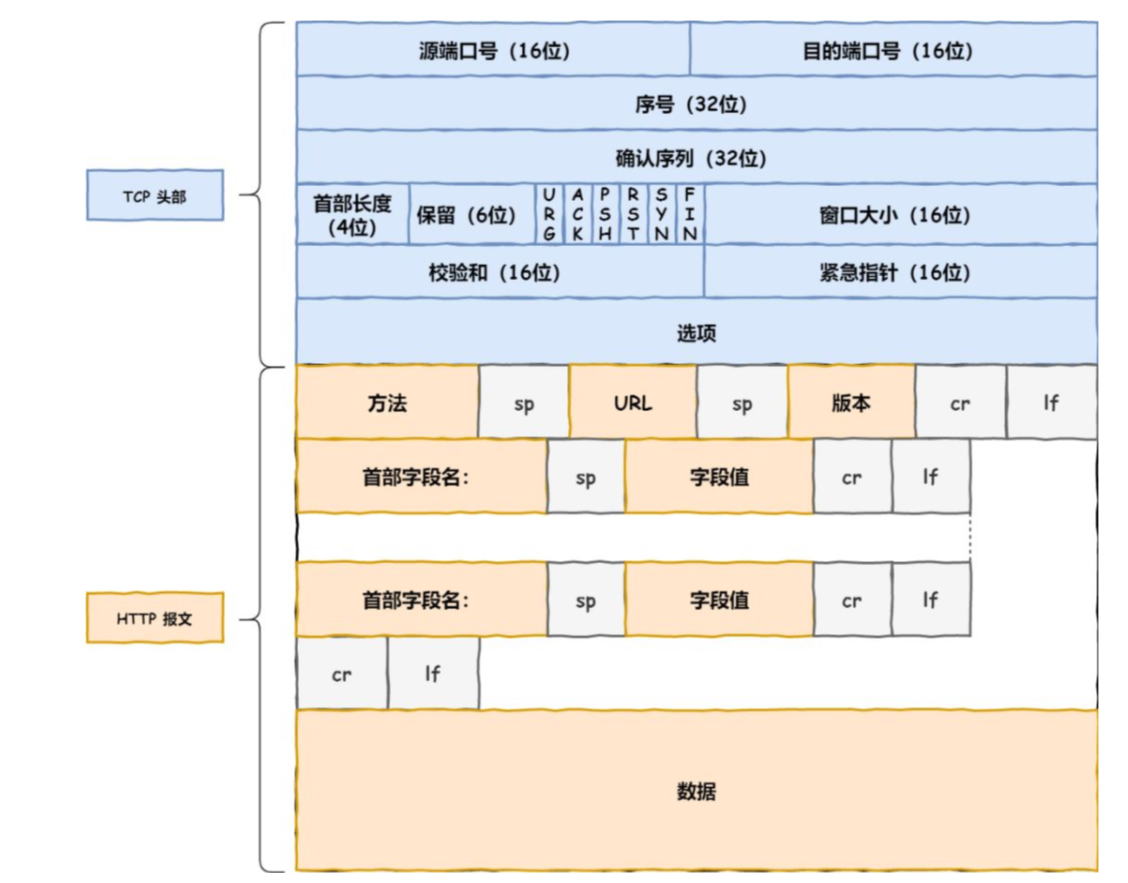 TCP 层报文
TCP 层报文
IP
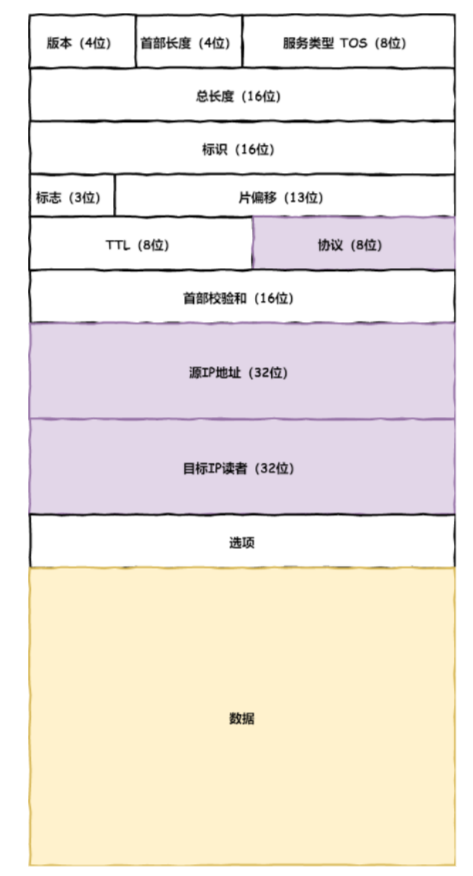 IP 报头格式
IP 报头格式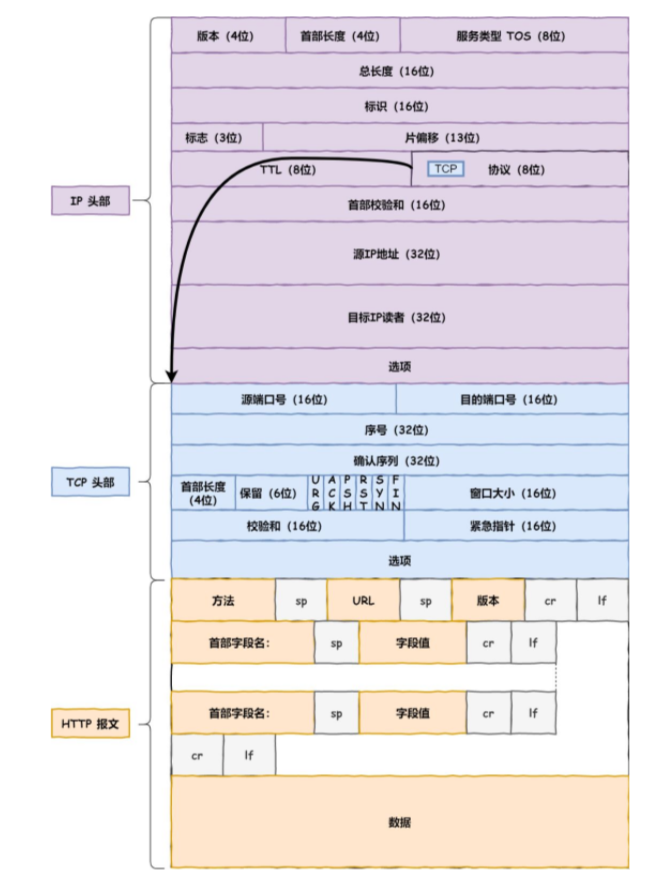 IP层报文
IP层报文
MAC
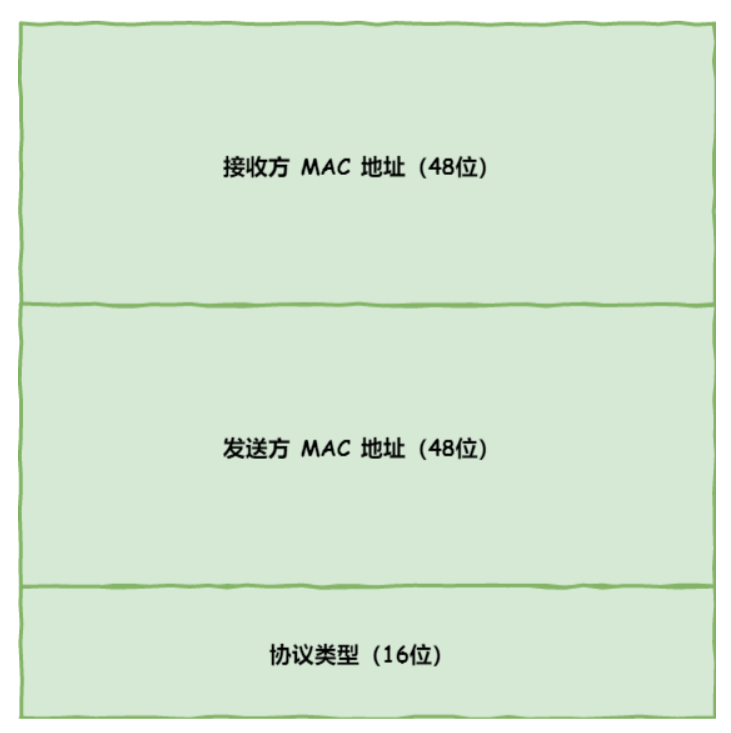 MAC 包头格式
MAC 包头格式
在MAC 包头里需要发送方 MAC 地址和接收方目标 MAC 地址,用于两点之间的传输。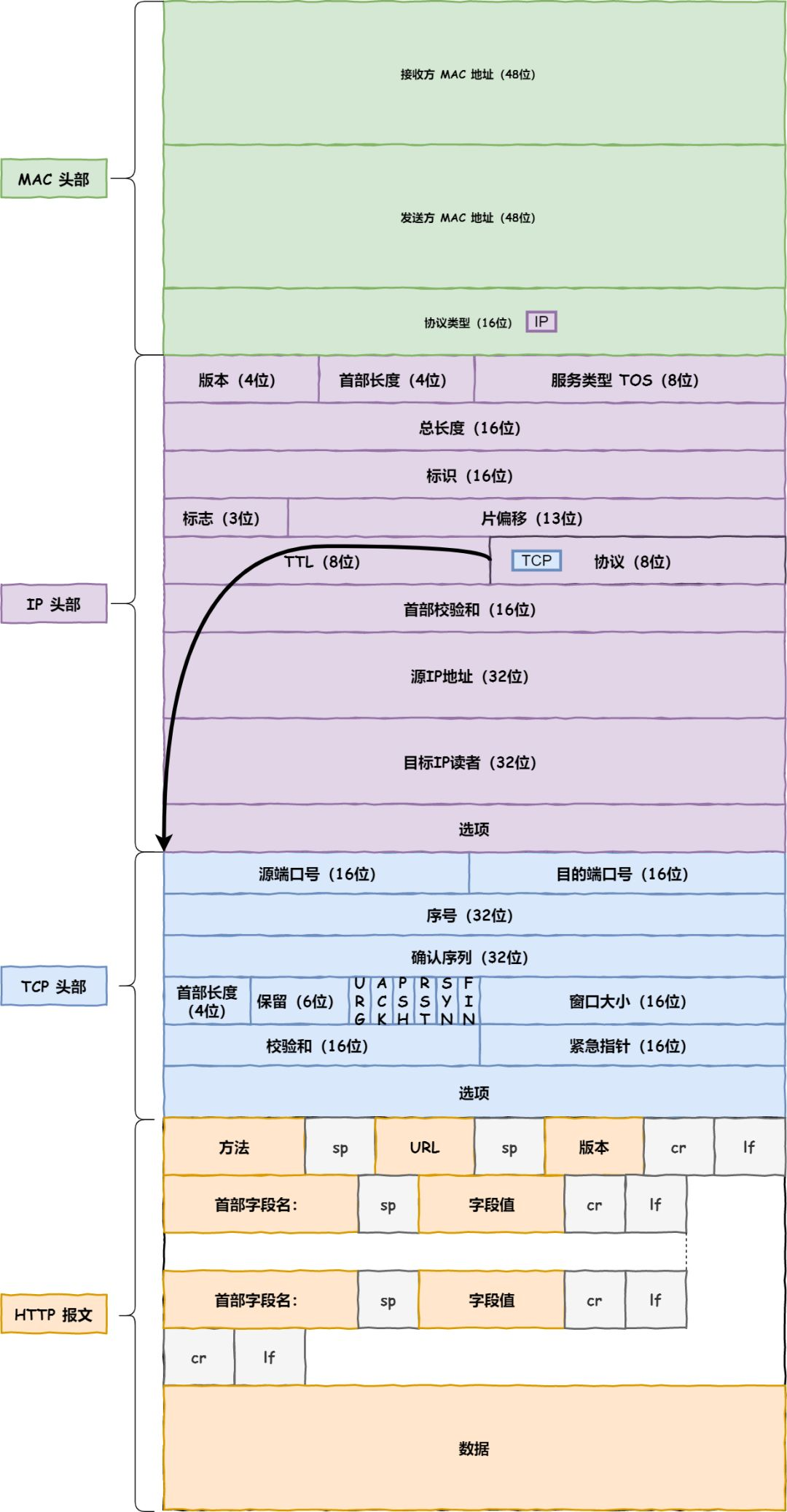 MAC 层报文
MAC 层报文
网卡
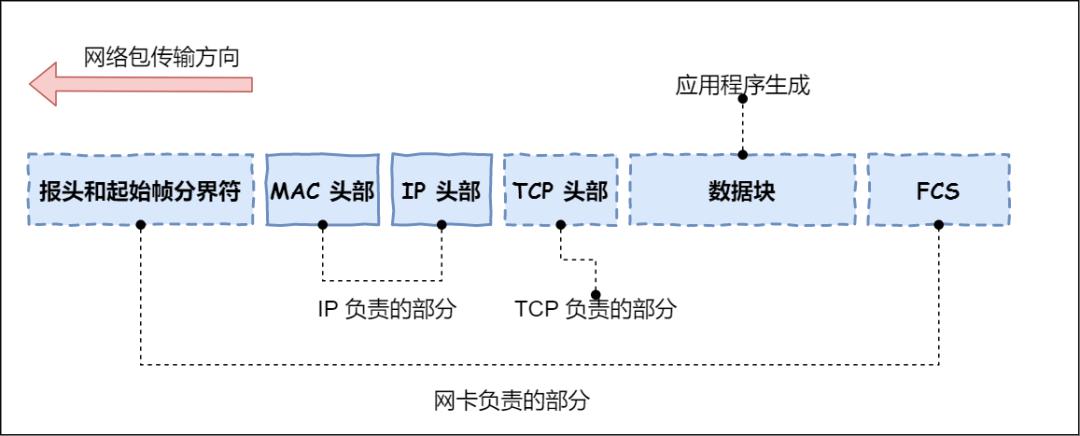 物理层数据包
物理层数据包
交换机
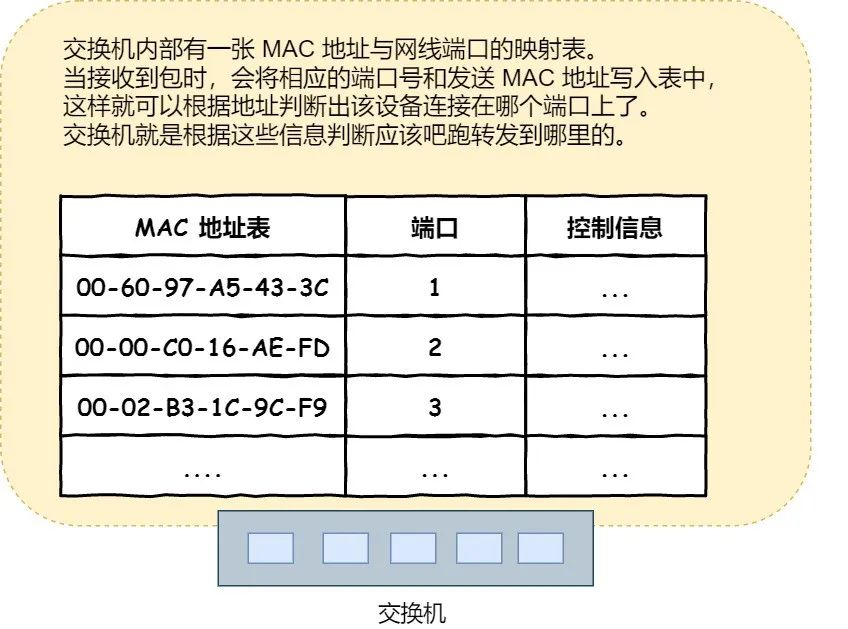 交换机的 MAC 地址表
交换机的 MAC 地址表
路由器
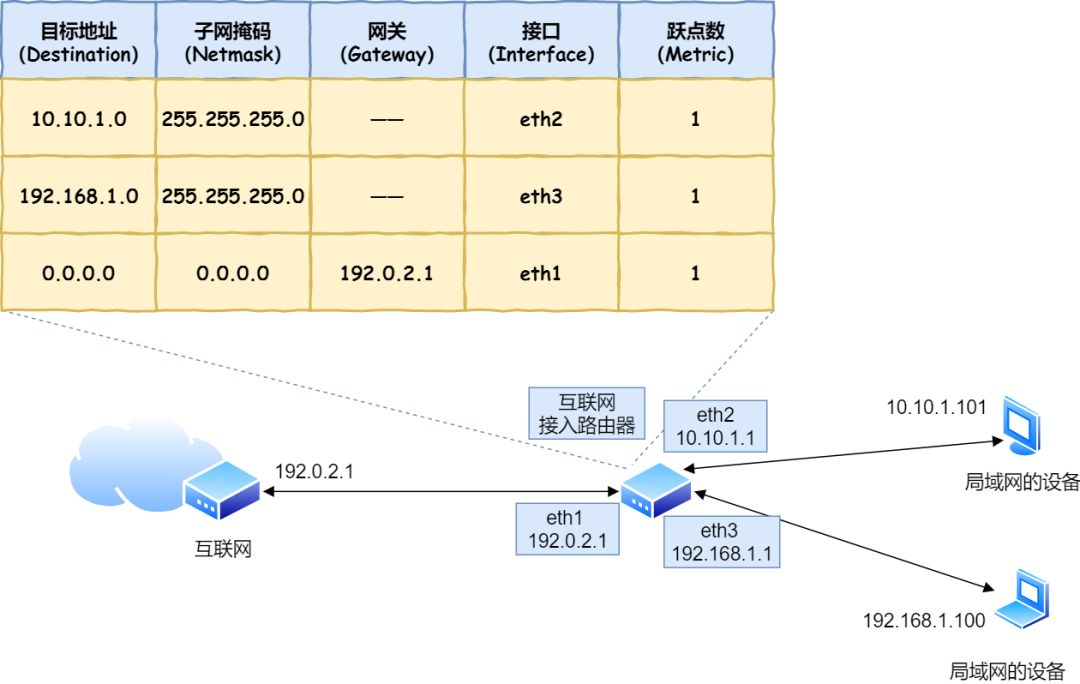 路由器转发
路由器转发
构建DOM树
- 栈顶元素就是当前节点;
- 遇到属性,就添加到当前节点
- 遇到文本节点,如果当前节点是文本节点,则跟文本节点合并,否则入栈称为当前节点的子节点
- 遇到注释节点,作为当前节点的子节点
- 遇到 tag start 就入栈一个节点,当前节点就是这个节点的父节点
- 遇到 tag end 就出栈一个节点(还可以检查是否匹配)
浏览器是如何把CSS规则应用到节点上
选择器的出现顺序,必定跟构建 DOM 树的顺序一致。这是一个 CSS 设计的原则,即保证选择器在 DOM 树构建到当前节点时,已经可以准确判断是否匹配,不需要后续节点信息。
CSS阻塞
CSS 文件的下载和解析不会影响 DOM 的解析,但是会阻塞 DOM 的渲染。因为 CSSOM Tree 要和 DOM Tree 合成 Render Tree 才能绘制页面。下面的 test1 在 CSS 下载并解析完成前是默认样式, test2 在 CSS 下载并解析完成之前不会显示。
<button class="btn btn-primary">test1</button><link rel="stylesheet" href="./style.css"><div>test2</div>
CSS 文件没下载并解析完成之前,后续的 JS 脚本不能执行。下面的
alert("ok")在 CSS 下载并解析完成之前不会弹出来。<link rel="stylesheet" href="./style.css"><script>alert("ok");</script>
CSS 文件的下载不会阻塞前面的 JS 脚本执行。下面的
alert("ok")会在 CSS 下载完不会弹出来。<script>alert("ok");</script><link rel="stylesheet" href="./style.css">
所以在需要提前执行不操作 DOM 元素的 JS 时,不妨把 JS 放到 CSS 文件之前。
注意:
GUI 渲染线程会尽可能早的将内容呈现到屏幕上,并不会等到所有的 HTML 都解析完成之后再去构建和布局 Render Tree ,而是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。下面 test1 会在 JS 文件下载完成前渲染完成,而 test2 则会在 JS 文件下载并执行完之后渲染:
<div>test1</div><link rel="stylesheet" href="./style.css"><div>test2</div>
排版
排版的意思时确定每一个字的位置。
浏览器最基本的排版方案时正常流排版,它包含了顺次排布和折行等规则,跟我们平时书写文字的方式一致,所以我们把它叫做正常流。
浏览器又可以支持元素和文字的混排,元素被定义为占据长方形的区域,还允许边框、边距和留白,这个就是所谓的盒模型。
在正常流的基础上,浏览器还支持两类元素:绝对定位元素和浮动元素。
- 绝对定位元素把自身从正常流抽出,直接由 top 和 left 等属性确定自身的位置,不参加排版计算,也不影响其它元素。绝对定位元素由 position 属性控制。
- 浮动元素则是使得自己在正常流的位置向左或者向右移动到边界,并且占据一块排版空间。浮动元素由 float 属性控制。
渲染
把模型变为位图的过程。
这里的位图就是在内存里建立一张二维表格,把一张图片的每个像素对应的颜色保存进去(位图信息也是 DOM 树中占据浏览器内存最多的信息,我们在做内存占用优化时,主要就是考虑这一部分)。
浏览器中渲染这个过程,就是把每一个元素对应的盒变成位图。这里的元素包括 HTML 元素和伪元素,一个元素可能对应多个盒(比如 inline 元素,可能会分成多行)。每一个盒对应着一张位图。
这个渲染过程是非常复杂的,但是总体来说,可以分成两个大类:图形和文字。
盒的背景、边框、SVG 元素、阴影等特性,都是需要绘制的图形类。我们需要一个底层库来支持。
一般的操作系统会提供一个底层库,比如在Android中,由Skia,而Windows平台则有GDI,一般的浏览器会做一个兼容层来处理平台差异。
盒中的文字,也需要用底层库来支持,叫做字体库。字体库提供读取字体文件的基本能力,它能根据字符的码点抽取出字形。
字形分为像素字形盒矢量字形两种。通常的字体,会在 6px 8px 等小尺寸提供像素字形,比较大的尺寸则提供矢量字形。矢量字形本身就需要经过渲染才能继续渲染到元素的位图上去。目前最常用的字体库是 Freetype,这是一个 C++ 编写的开源的字体库。
注意,我们这里讲的渲染过程,是不会把子元素绘制到渲染的位图上的,这样,当父子元素的相对位置发生变化时,可以保证渲染的结果能够最大程度被缓存,减少重新渲染。
合成
合成的过程,就是为一些元素创建一个“合成后的位图”(我们把它称为合成层),把一部分子元素渲染到合成的位图上面。
合成是一个性能考量,那么合成的目标就是提高性能,根据这个目标,我们建立的原则就是最大限度减少绘制次数原则。
绘制
绘制是把“位图最终绘制到屏幕上,变成肉眼可见的图像”的过程,不过,一般来说,浏览器并不需要用代码来处理这个过程,浏览器只需要把最终要显示的位图交给操作系统即可。
“脏矩形”算法,也就是把屏幕均匀地分成若干矩形区域。
当鼠标移动、元素移动或者其它导致需要重绘的场景发生时,我们只重新绘制它所影响到的几个矩形区域就够了。
设置合适的矩形区域大小,可以很好地控制绘制时的消耗。设置过大的矩形会造成绘制面积增大,而设置过小的矩形则会造成计算复杂。
参考链接:
- 一次完整的HTTP事务是怎样一个过程?
- 浏览器的工作原理:新式网络浏览器幕后揭秘值得一看
- 渲染树构建、布局及绘制还没仔细看,觉得可以看看

若有收获,就点个赞吧
0 人点赞
