第 14 章 DOM
本章内容
- 理解文档对象模型(DOM)的构成
- 节点类型
- 浏览器兼容性
MutationObserver接口
文档对象模型(DOM,Document Object Model)是HTML和XML文档的编程接口。DOM表示由多层节点构成的文档,通过它开发者可以添加、删除和修改页面的各个部分。脱胎于网景和微软早期的动态HTML(DHTML,Dynamic HTML),DOM现在是真正跨平台、语言无关的表示和操作网页的方式。
DOM Level 1在1998年成为W3C推荐标准,提供了基本文档结构和查询的接口。本章之所以介绍DOM,主要因为它与浏览器中的HTML网页相关,并且在JavaScript中提供了DOM API。
注意 IE8及更低版本中的DOM是通过COM对象实现的。这意味着这些版本的IE中,DOM对象跟原生JavaScript对象具有不同的行为和功能。
14.1 节点层级
任何HTML或XML文档都可以用DOM表示为一个由节点构成的层级结构。节点分很多类型,每种类型对应着文档中不同的信息和(或)标记,也都有自己不同的特性、数据和方法,而且与其他类型有某种关系。这些关系构成了层级,让标记可以表示为一个以特定节点为根的树形结构。以下面的HTML为例:
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<p>Hello World!</p>
</body>
</html>
如果表示为层级结构,则如图14-1所示。
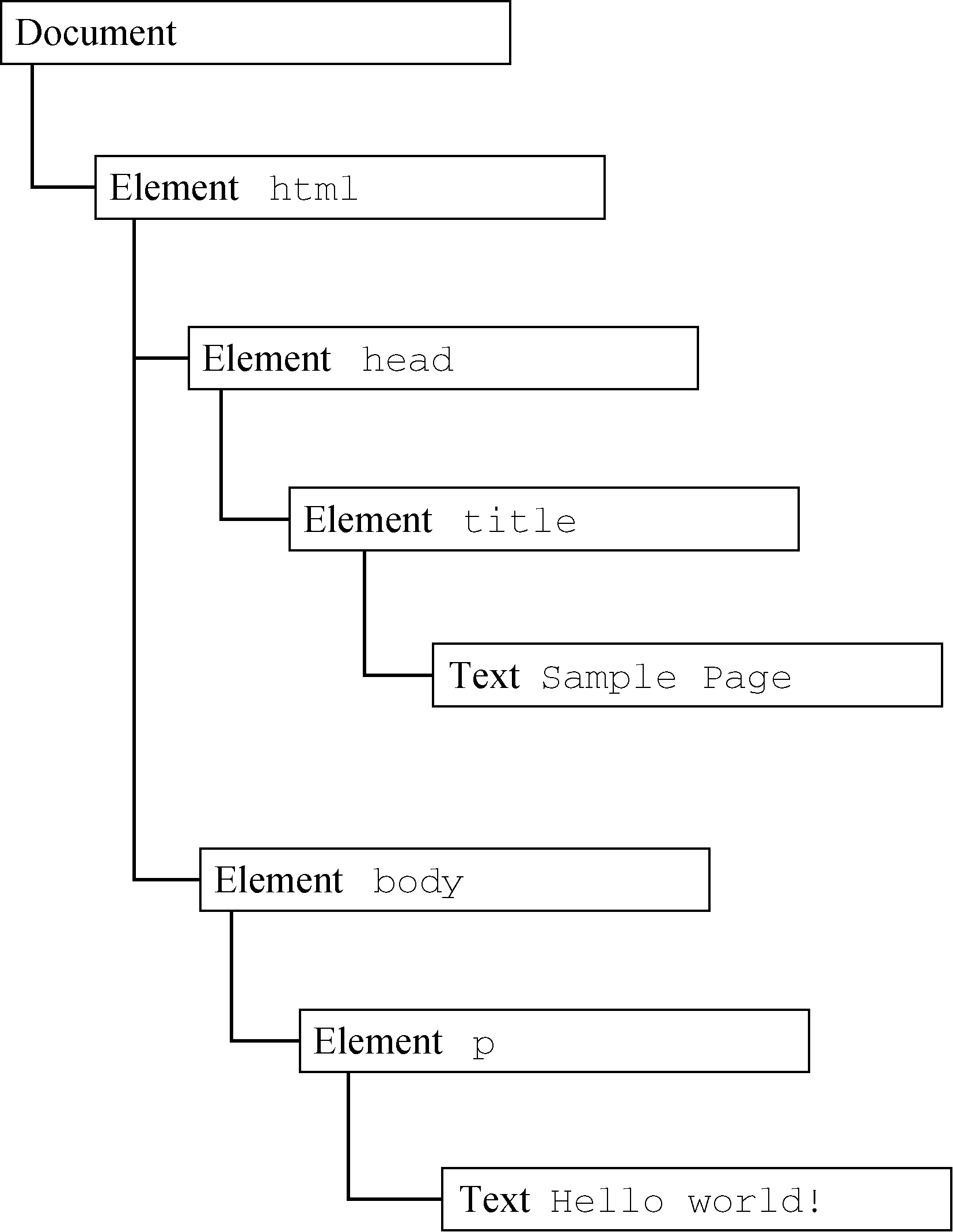
图 14-1
其中,document节点表示每个文档的根节点。在这里,根节点的唯一子节点是<html>元素,我们称之为文档元素(documentElement)。文档元素是文档最外层的元素,所有其他元素都存在于这个元素之内。每个文档只能有一个文档元素。在HTML页面中,文档元素始终是<html>元素。在XML文档中,则没有这样预定义的元素,任何元素都可能成为文档元素。
HTML中的每段标记都可以表示为这个树形结构中的一个节点。元素节点表示HTML元素,属性节点表示属性,文档类型节点表示文档类型,注释节点表示注释。DOM中总共有12种节点类型,这些类型都继承一种基本类型。
14.1.1 Node类型
DOM Level 1描述了名为Node的接口,这个接口是所有DOM节点类型都必须实现的。Node接口在JavaScript中被实现为Node类型,在除IE之外的所有浏览器中都可以直接访问这个类型。在JavaScript中,所有节点类型都继承Node类型,因此所有类型都共享相同的基本属性和方法。
每个节点都有nodeType属性,表示该节点的类型。节点类型由定义在Node类型上的12个数值常量表示:
Node.ELEMENT_NODE(1)Node.ATTRIBUTE_NODE(2)Node.TEXT_NODE(3)Node.CDATA_SECTION_NODE(4)Node.ENTITY_REFERENCE_NODE(5)Node.ENTITY_NODE(6)Node.PROCESSING_INSTRUCTION_NODE(7)Node.COMMENT_NODE(8)Node.DOCUMENT_NODE(9)Node.DOCUMENT_TYPE_NODE(10)Node.DOCUMENT_FRAGMENT_NODE(11)Node.NOTATION_NODE(12)
节点类型可通过与这些常量比较来确定,比如:
if (someNode.nodeType == Node.ELEMENT_NODE){
alert("Node is an element.");
}
这个例子比较了someNode.nodeType与Node.ELEMENT_NODE常量。如果两者相等,则意味着someNode是一个元素节点。
浏览器并不支持所有节点类型。开发者最常用到的是元素节点和文本节点。本章后面会讨论每种节点受支持的程度及其用法。
nodeName与nodeValue
nodeName与nodeValue保存着有关节点的信息。这两个属性的值完全取决于节点类型。在使用这两个属性前,最好先检测节点类型,如下所示:if (someNode.nodeType == 1){ value = someNode.nodeName; // 会显示元素的标签名 }在这个例子中,先检查了节点是不是元素。如果是,则将其
nodeName的值赋给一个变量。对元素而言,nodeName始终等于元素的标签名,而nodeValue则始终为null。节点关系
文档中的所有节点都与其他节点有关系。这些关系可以形容为家族关系,相当于把文档树比作家谱。在HTML中,<body>元素是<html>元素的子元素,而<html>元素则是<body>元素的父元素。<head>元素是<body>元素的同胞元素,因为它们有共同的父元素<html>。
每个节点都有一个childNodes属性,其中包含一个NodeList的实例。NodeList是一个类数组对象,用于存储可以按位置存取的有序节点。注意,NodeList并不是Array的实例,但可以使用中括号访问它的值,而且它也有length属性。NodeList对象独特的地方在于,它其实是一个对DOM结构的查询,因此DOM结构的变化会自动地在NodeList中反映出来。我们通常说NodeList是实时的活动对象,而不是第一次访问时所获得内容的快照。
下面的例子展示了如何使用中括号或使用item()方法访问NodeList中的元素:let firstChild = someNode.childNodes[0]; let secondChild = someNode.childNodes.item(1); let count = someNode.childNodes.length;无论是使用中括号还是
item()方法都是可以的,但多数开发者倾向于使用中括号,因为它是一个类数组对象。注意,length属性表示那一时刻NodeList中节点的数量。使用Array.prototype.slice()可以像前面介绍arguments时一样把NodeList对象转换为数组。比如:let arrayOfNodes = Array.prototype.slice.call(someNode.childNodes,0);当然,使用ES6的
Array.from()静态方法,可以替换这种笨拙的方式:let arrayOfNodes = Array.from(someNode.childNodes);每个节点都有一个
parentNode属性,指向其DOM树中的父元素。childNodes中的所有节点都有同一个父元素,因此它们的parentNode属性都指向同一个节点。此外,childNodes列表中的每个节点都是同一列表中其他节点的同胞节点。而使用previousSibling和nextSibling可以在这个列表的节点间导航。这个列表中第一个节点的previousSibling属性是null,最后一个节点的nextSibling属性也是null,如下所示:if (someNode.nextSibling === null){ alert("Last node in the parent's childNodes list."); } else if (someNode.previousSibling === null){ alert("First node in the parent's childNodes list."); }注意,如果
childNodes中只有一个节点,则它的previousSibling和nextSibling属性都是null。
父节点和它的第一个及最后一个子节点也有专门属性:firstChild和lastChild分别指向childNodes中的第一个和最后一个子节点。someNode.firstChild的值始终等于someNode.childNodes[0],而someNode.lastChild的值始终等于someNode.childNodes[someNode.childNodes.length-1]。如果只有一个子节点,则firstChild和lastChild指向同一个节点。如果没有子节点,则firstChild和lastChild都是null。上述这些节点之间的关系为在文档树的节点之间导航提供了方便。图14-2形象地展示了这些关系。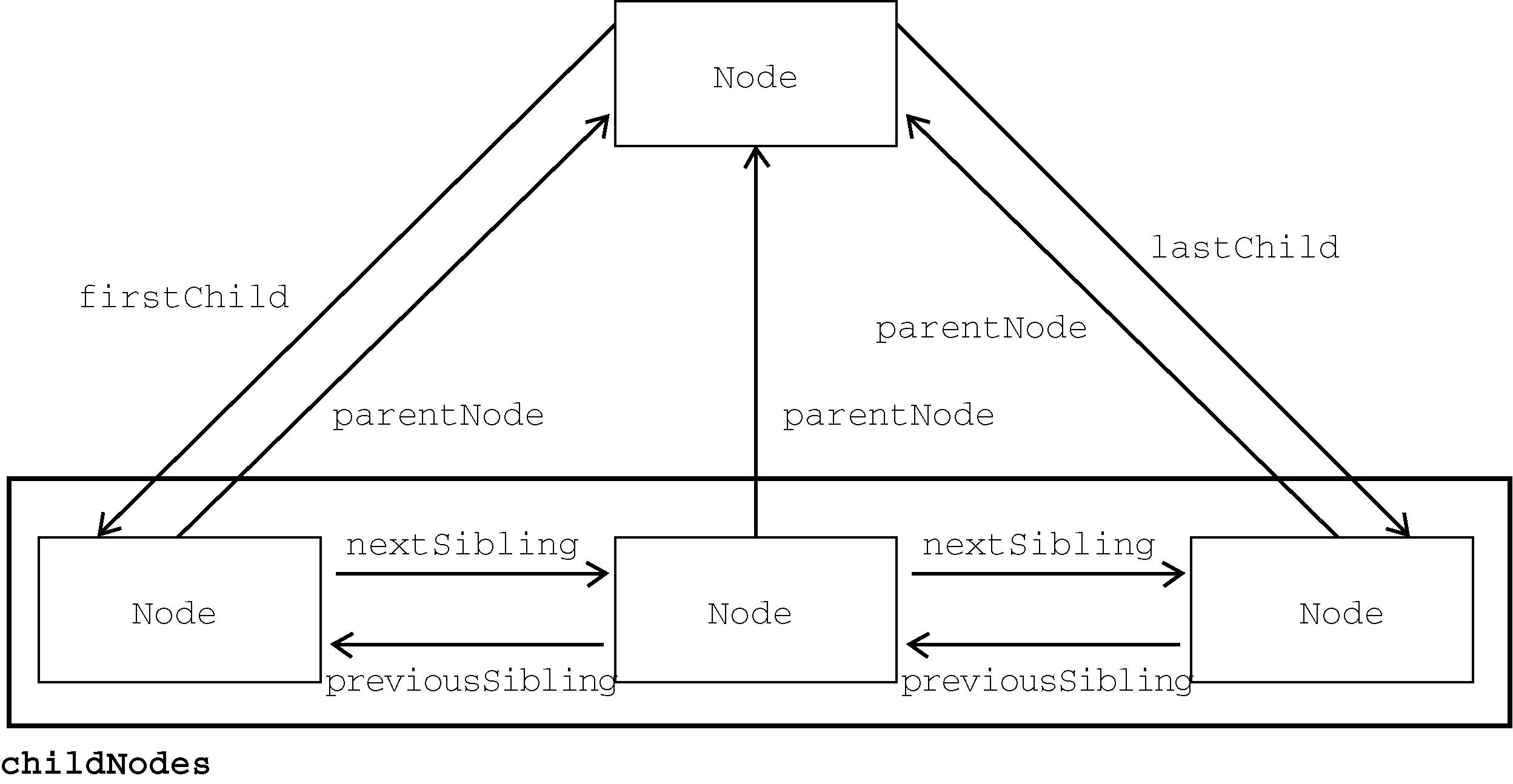
图 14-2
有了这些关系,childNodes属性的作用远远不止是必备属性那么简单了。这是因为利用这些关系指针,几乎可以访问到文档树中的任何节点,而这种便利性是childNodes的最大亮点。还有一个便利的方法是hasChildNodes(),这个方法如果返回true则说明节点有一个或多个子节点。相比查询childNodes的length属性,这个方法无疑更方便。
最后还有一个所有节点都共享的关系。ownerDocument属性是一个指向代表整个文档的文档节点的指针。所有节点都被创建它们(或自己所在)的文档所拥有,因为一个节点不可能同时存在于两个或者多个文档中。这个属性为迅速访问文档节点提供了便利,因为无需在文档结构中逐层上溯了。注意 虽然所有节点类型都继承了
Node,但并非所有节点都有子节点。本章后面会讨论不同节点类型的差异。操纵节点
因为所有关系指针都是只读的,所以DOM又提供了一些操纵节点的方法。最常用的方法是appendChild(),用于在childNodes列表末尾添加节点。添加新节点会更新相关的关系指针,包括父节点和之前的最后一个子节点。appendChild()方法返回新添加的节点,如下所示:let returnedNode = someNode.appendChild(newNode); alert(returnedNode == newNode); // true alert(someNode.lastChild == newNode); // true如果把文档中已经存在的节点传给
appendChild(),则这个节点会从之前的位置被转移到新位置。即使DOM树通过各种关系指针维系,一个节点也不会在文档中同时出现在两个或更多个地方。因此,如果调用appendChild()传入父元素的第一个子节点,则这个节点会成为父元素的最后一个子节点,如下所示:// 假设someNode有多个子节点 let returnedNode = someNode.appendChild(someNode.firstChild); alert(returnedNode == someNode.firstChild); // false alert(returnedNode == someNode.lastChild); // true如果想把节点放到
childNodes中的特定位置而不是末尾,则可以使用insertBefore()方法。这个方法接收两个参数:要插入的节点和参照节点。调用这个方法后,要插入的节点会变成参照节点的前一个同胞节点,并被返回。如果参照节点是null,则insertBefore()与appendChild()效果相同,如下面的例子所示: ``` // 作为最后一个子节点插入 returnedNode = someNode.insertBefore(newNode, null); alert(newNode == someNode.lastChild); // true
// 作为新的第一个子节点插入 returnedNode = someNode.insertBefore(newNode, someNode.firstChild); alert(returnedNode == newNode); // true alert(newNode == someNode.firstChild); // true
// 插入最后一个子节点前面 returnedNode = someNode.insertBefore(newNode, someNode.lastChild); alert(newNode == someNode.childNodes[someNode.childNodes.length - 2]); // true
3. `appendChild()`和`insertBefore()`在插入节点时不会删除任何已有节点。相对地,`replaceChild()`方法接收两个参数:要插入的节点和要替换的节点。要替换的节点会被返回并从文档树中完全移除,要插入的节点会取而代之。下面看一个例子:
// 替换第一个子节点 let returnedNode = someNode.replaceChild(newNode, someNode.firstChild);
// 替换最后一个子节点 returnedNode = someNode.replaceChild(newNode, someNode.lastChild);
3. 使用`replaceChild()`插入一个节点后,所有关系指针都会从被替换的节点复制过来。虽然被替换的节点从技术上说仍然被同一个文档所拥有,但文档中已经没有它的位置。<br />要移除节点而不是替换节点,可以使用`removeChild()`方法。这个方法接收一个参数,即要移除的节点。被移除的节点会被返回,如下面的例子所示:
// 删除第一个子节点 let formerFirstChild = someNode.removeChild(someNode.firstChild);
// 删除最后一个子节点 let formerLastChild = someNode.removeChild(someNode.lastChild);
3. 与`replaceChild()`方法一样,通过`removeChild()`被移除的节点从技术上说仍然被同一个文档所拥有,但文档中已经没有它的位置。<br />上面介绍的4个方法都用于操纵某个节点的子元素,也就是说使用它们之前必须先取得父节点(使用前面介绍的`parentNode`属性)。并非所有节点类型都有子节点,如果在不支持子节点的节点上调用这些方法,则会导致抛出错误。
4. **其他方法**<br />所有节点类型还共享了两个方法。第一个是`cloneNode()`,会返回与调用它的节点一模一样的节点。`cloneNode()`方法接收一个布尔值参数,表示是否深复制。在传入`true`参数时,会进行深复制,即复制节点及其整个子DOM树。如果传入`false`,则只会复制调用该方法的节点。复制返回的节点属于文档所有,但尚未指定父节点,所以可称为孤儿节点(orphan)。可以通过`appendChild()`、`insertBefore()`或`replaceChild()`方法把孤儿节点添加到文档中。以下面的HTML片段为例:
- item 1
- item 2
- item 3
4. 如果`myList`保存着对这个`<ul>`元素的引用,则下列代码展示了使用`cloneNode()`方法的两种方式:
let deepList = myList.cloneNode(true); alert(deepList.childNodes.length); // 3(IE9之前的版本)或7(其他浏览器)
let shallowList = myList.cloneNode(false); alert(shallowList.childNodes.length); // 0
4. 在这个例子中,`deepList`保存着`myList`的副本。这意味着`deepList`有3个列表项,每个列表项又各自包含文本。变量`shallowList`则保存着`myList`的浅副本,因此没有子节点。`deepList.childNodes.length`的值会因IE8及更低版本和其他浏览器对空格的处理方式而不同。IE9之前的版本不会为空格创建节点。
> **注意** `cloneNode()`方法不会复制添加到DOM节点的JavaScript属性,比如事件处理程序。这个方法只复制HTML属性,以及可选地复制子节点。除此之外则一概不会复制。IE在很长时间内会复制事件处理程序,这是一个bug,所以推荐在复制前先删除事件处理程序。
4. 本节要介绍的最后一个方法是`normalize()`。这个方法唯一的任务就是处理文档子树中的文本节点。由于解析器实现的差异或DOM操作等原因,可能会出现并不包含文本的文本节点,或者文本节点之间互为同胞关系。在节点上调用`normalize()`方法会检测这个节点的所有后代,从中搜索上述两种情形。如果发现空文本节点,则将其删除;如果两个同胞节点是相邻的,则将其合并为一个文本节点。这个方法将在本章后面进一步讨论。
<a name="17e76d58"></a>
### 14.1.2 `Document`类型
`Document`类型是JavaScript中表示文档节点的类型。在浏览器中,文档对象`document`是`HTMLDocument`的实例(`HTMLDocument`继承`Document`),表示整个HTML页面。`document`是`window`对象的属性,因此是一个全局对象。`Document`类型的节点有以下特征:
- `nodeType`等于9;
- `nodeName`值为`"#document"`;
- `nodeValue`值为`null`;
- `parentNode`值为`null`;
- `ownerDocument`值为`null`;
- 子节点可以是`DocumentType`(最多一个)、`Element`(最多一个)、`ProcessingInstruction`或`Comment`类型。
`Document`类型可以表示HTML页面或其他XML文档,但最常用的还是通过`HTMLDocument`的实例取得`document`对象。`document`对象可用于获取关于页面的信息以及操纵其外观和底层结构。
1. **文档子节点**<br />虽然DOM规范规定`Document`节点的子节点可以是`DocumentType`、`Element`、`ProcessingInstruction`或`Comment`,但也提供了两个访问子节点的快捷方式。第一个是`documentElement`属性,始终指向HTML页面中的`<html>`元素。虽然`document.childNodes`中始终有`<html>`元素,但使用`documentElement`属性可以更快更直接地访问该元素。假如有以下简单的页面:
1. 浏览器解析完这个页面之后,文档只有一个子节点,即`<html>`元素。这个元素既可以通过`documentElement`属性获取,也可以通过`childNodes`列表访问,如下所示:
let html = document.documentElement; // 取得对的引用 alert(html === document.childNodes[0]); // true alert(html === document.firstChild); // true
1. 这个例子表明`documentElement`、 `firstChild`和`childNodes[0]`都指向同一个值,即`<html>`元素。<br />作为`HTMLDocument`的实例,`document`对象还有一个`body`属性,直接指向`<body>`元素。因为这个元素是开发者使用最多的元素,所以JavaScript代码中经常可以看到`document.body`,比如:
let body = document.body; // 取得对的引用
1. 所有主流浏览器都支持`document.documentElement`和`document.body`。<br />`Document`类型另一种可能的子节点是`DocumentType`。`<!doctype>`标签是文档中独立的部分,其信息可以通过`doctype`属性(在浏览器中是`document.doctype`)来访问,比如:
let doctype = document.doctype; // 取得对<!doctype>的引用
1. 另外,严格来讲出现在`<html>`元素外面的注释也是文档的子节点,它们的类型是`Comment`。不过,由于浏览器实现不同,这些注释不一定能被识别,或者表现可能不一致。比如以下HTML页面:
1. 这个页面看起来有3个子节点:注释、`<html>`元素、注释。逻辑上讲,`document.childNodes`应该包含3项,对应代码中的每个节点。但实际上,浏览器有可能以不同方式对待`<html>`元素外部的注释,比如忽略一个或两个注释。<br />一般来说,`appendChild()`、`removeChild()`和`replaceChild()`方法不会用在`document`对象上。这是因为文档类型(如果存在)是只读的,而且只能有一个`Element`类型的子节点(即`<html>`,已经存在了)。**1**
2. **文档信息**<br />`document`作为`HTMLDocument`的实例,还有一些标准`Document`对象上所没有的属性。这些属性提供浏览器所加载网页的信息。其中第一个属性是`title`,包含`<title>`元素中的文本,通常显示在浏览器窗口或标签页的标题栏。通过这个属性可以读写页面的标题,修改后的标题也会反映在浏览器标题栏上。不过,修改`title`属性并不会改变`<title>`元素。下面是一个例子:
// 读取文档标题 let originalTitle = document.title;
// 修改文档标题 document.title = “New page title”;
2. 接下来要介绍的3个属性是`URL`、`domain`和`referrer`。其中,`URL`包含当前页面的完整URL(地址栏中的URL),`domain`包含页面的域名,而`referrer`包含链接到当前页面的那个页面的URL。如果当前页面没有来源,则`referrer`属性包含空字符串。所有这些信息都可以在请求的HTTP头部信息中获取,只是在JavaScript中通过这几个属性暴露出来而已,如下面的例子所示:
// 取得完整的URL let url = document.URL;
// 取得域名 let domain = document.domain;
// 取得来源 let referrer = document.referrer;
2. URL跟域名是相关的。比如,如果`document.URL`是`[http://www.wrox.com/WileyCDA/](http://www.wrox.com/WileyCDA/)`,则`document.domain`就是`www.wrox.com`。<br />在这些属性中,只有`domain`属性是可以设置的。出于安全考虑,给`domain`属性设置的值是有限制的。如果URL包含子域名如`p2p.wrox.com`,则可以将`domain`设置为`"wrox.com"`(URL包含“www”时也一样,比如`www.wrox.com`)。不能给这个属性设置URL中不包含的值,比如:
// 页面来自p2p.wrox.com
document.domain = “wrox.com”; // 成功
document.domain = “nczonline.net”; // 出错!
2. 当页面中包含来自某个不同子域的窗格(`<frame>`)或内嵌窗格(`<iframe>`)时,设置`document.domain`是有用的。因为跨源通信存在安全隐患,所以不同子域的页面间无法通过JavaScript通信。此时,在每个页面上把`document.domain`设置为相同的值,这些页面就可以访问对方的JavaScript对象了。比如,一个加载自`www.wrox.com`的页面中包含一个内嵌窗格,其中的页面加载自`p2p.wrox.com`。这两个页面的`document.domain`包含不同的字符串,内部和外部页面相互之间不能访问对方的JavaScript对象。如果每个页面都把`document.domain`设置为`wrox.com`,那这两个页面之间就可以通信了。<br />浏览器对`domain`属性还有一个限制,即这个属性一旦放松就不能再收紧。比如,把`document.domain` 设置为`"wrox.com"`之后,就不能再将其设置回`"p2p.wrox.com"`,后者会导致错误,比如:
// 页面来自p2p.wrox.com
document.domain = “wrox.com”; // 放松,成功
document.domain = “p2p.wrox.com”; // 收紧,错误!
3. **定位元素**<br />使用DOM最常见的情形可能就是获取某个或某组元素的引用,然后对它们执行某些操作。`document`对象上暴露了一些方法,可以实现这些操作。`getElementById()`和`getElementsByTagName()`就是`Document`类型提供的两个方法。<br />`getElementById()`方法接收一个参数,即要获取元素的ID,如果找到了则返回这个元素,如果没找到则返回`null`。参数ID必须跟元素在页面中的`id`属性值完全匹配,包括大小写。比如页面中有以下元素:
3. 可以使用如下代码取得这个元素:
let div = document.getElementById(“myDiv”); // 取得对这个3. 但参数大小写不匹配会返回`null`:
let div = document.getElementById(“mydiv”); // null
3. 如果页面中存在多个具有相同ID的元素,则`getElementById()`返回在文档中出现的第一个元素。<br />`getElementsByTagName()`是另一个常用来获取元素引用的方法。这个方法接收一个参数,即要获取元素的标签名,返回包含零个或多个元素的`NodeList`。在HTML文档中,这个方法返回一个`HTMLCollection`对象。考虑到二者都是“实时”列表,`HTMLCollection`与`NodeList`是很相似的。例如,下面的代码会取得页面中所有的`<img>`元素并返回包含它们的`HTMLCollection`:
let images = document.getElementsByTagName(“img”);
3. 这里把返回的`HTMLCollection`对象保存在了变量`images`中。与`NodeList`对象一样,也可以使用中括号或`item()`方法从`HTMLCollection`取得特定的元素。而取得元素的数量同样可以通过`length`属性得知,如下所示:
alert(images.length); // 图片数量
alert(images[0].src); // 第一张图片的src属性
alert(images.item(0).src); // 同上
3. `HTMLCollection`对象还有一个额外的方法`namedItem()`,可通过标签的`name`属性取得某一项的引用。例如,假设页面中包含如下的`<img>`元素:

3. 那么也可以像这样从`images`中取得对这个`<img>`元素的引用:
let myImage = images.namedItem(“myImage”);
3. 这样,`HTMLCollection`就提供了除索引之外的另一种获取列表项的方式,从而为取得元素提供了便利。对于`name`属性的元素,还可以直接使用中括号来获取,如下面的例子所示:
let myImage = images[“myImage”];
3. 对`HTMLCollection`对象而言,中括号既可以接收数值索引,也可以接收字符串索引。而在后台,数值索引会调用`item()`,字符串索引会调用`namedItem()`。<br />要取得文档中的所有元素,可以给`getElementsByTagName()`传入`*`。在JavaScript和CSS中,`*`一般被认为是匹配一切的字符。来看下面的例子:
let allElements = document.getElementsByTagName(““);
3. 这行代码可以返回包含页面中所有元素的`HTMLCollection`对象,顺序就是它们在页面中出现的顺序。因此第一项是`<html>`元素,第二项是`<head>`元素,以此类推。
> **注意** 对于`document.getElementsByTagName()`方法,虽然规范要求区分标签的大小写,但为了最大限度兼容原有HTML页面,实际上是不区分大小写的。如果是在XML页面(如XHTML)中使用,那么`document.getElementsByTagName()`就是区分大小写的。
3. `HTMLDocument`类型上定义的获取元素的第三个方法是`getElementsByName()`。顾名思义,这个方法会返回具有给定`name`属性的所有元素。`getElementsByName()`方法最常用于单选按钮,因为同一字段的单选按钮必须具有相同的`name`属性才能确保把正确的值发送给服务器,比如下面的例子:
3. 这里所有的单选按钮都有名为`"color"`的`name`属性,但它们的ID都不一样。这是因为ID是为了匹配对应的`<label>`元素,而`name`相同是为了保证只将三个中的一个值发送给服务器。然后就可以像下面这样取得所有单选按钮:
let radios = document.getElementsByName(“color”);
3. 与`getElementsByTagName()`一样,`getElementsByName()`方法也返回`HTMLCollection`。不过在这种情况下,`namedItem()`方法只会取得第一项(因为所有项的`name`属性都一样)。
4. **特殊集合**<br />`document`对象上还暴露了几个特殊集合,这些集合也都是`HTMLCollection`的实例。这些集合是访问文档中公共部分的快捷方式,列举如下。
- `document.anchors`包含文档中所有带`name`属性的`<a>`元素。
- `document.applets`包含文档中所有`<applet>`元素(因为`<applet>`元素已经不建议使用,所以这个集合已经废弃)。
- `document.forms`包含文档中所有`<form>`元素(与`document.getElementsByTagName ("form")`返回的结果相同)。
- `document.images`包含文档中所有`<img>`元素(与`document.getElementsByTagName ("img")`返回的结果相同)。
- `document.links`包含文档中所有带`href`属性的`<a>`元素。
这些特殊集合始终存在于`HTMLDocument`对象上,而且与所有`HTMLCollection`对象一样,其内容也会实时更新以符合当前文档的内容。
5. **DOM兼容性检测**<br />由于DOM有多个Level和多个部分,因此确定浏览器实现了DOM的哪些部分是很必要的。`document.implementation`属性是一个对象,其中提供了与浏览器DOM实现相关的信息和能力。DOM Level 1在`document.implementation`上只定义了一个方法,即`hasFeature()`。这个方法接收两个参数:特性名称和DOM版本。如果浏览器支持指定的特性和版本,则`hasFeature()`方法返回`true`,如下面的例子所示:
let hasXmlDom = document.implementation.hasFeature(“XML”, “1.0”);
5. 可以使用`hasFeature()`方法测试的特性及版本如下表所列。
| 特性 | 支持的版本 | 说明 |
| :--- | :--- | :--- |
| `Core` | 1.0、2.0、3.0 | 定义树形文档结构的基本DOM |
| `XML` | 1.0、2.0、3.0 | `Core`的XML扩展,增加了对CDATA区块、处理指令和实体的支持 |
| `HTML` | 1.0、2.0 | `XML`的HTML扩展,增加了HTML特定的元素和实体 |
| `Views` | 2.0 | 文档基于某些样式的实现格式 |
| `StyleSheets` | 2.0 | 文档的相关样式表 |
| `CSS` | 2.0 | Cascading Style Sheets Level 1 |
| `CSS2` | 2.0 | Cascading Style Sheets Level 2 |
| `Events` | 2.0、3.0 | 通用DOM事件 |
| `UIEvents` | 2.0、3.0 | 用户界面事件 |
| `TextEvents` | 3.0 | 文本输入设备触发的事件 |
| `MouseEvents` | 2.0、3.0 | 鼠标导致的事件(单击、悬停等) |
| `MutationEvents` | 2.0、3.0 | DOM树变化时触发的事件 |
| `MutationNameEvents` | 3.0 | DOM元素或元素属性被重命名时触发的事件 |
| `HTMLEvents` | 2.0 | HTML 4.01事件 |
| `Range` | 2.0 | 在DOM树中操作一定范围的对象和方法 |
| `Traversal` | 2.0 | 遍历DOM树的方法 |
| `LS` | 3.0 | 文件与DOM树之间的同步加载与保存 |
| `LS-Async` | 3.0 | 文件与DOM树之间的异步加载与保存 |
| `Validation` | 3.0 | 修改DOM树并保证其继续有效的方法 |
| `XPath` | 3.0 | 访问XML文档不同部分的语言 |
5. 由于实现不一致,因此`hasFeature()`的返回值并不可靠。目前这个方法已经被废弃,不再建议使用。为了向后兼容,目前主流浏览器仍然支持这个方法,但无论检测什么都一律返回`true`。
6. **文档写入**<br />`document`对象有一个古老的能力,即向网页输出流中写入内容。这个能力对应4个方法:`write()`、`writeln()`、`open()`和`close()`。其中,`write()`和`writeln()`方法都接收一个字符串参数,可以将这个字符串写入网页中。`write()`简单地写入文本,而`writeln()`还会在字符串末尾追加一个换行符(`\n`)。这两个方法可以用来在页面加载期间向页面中动态添加内容,如下所示:
The current date and time is:
6. 这个例子会在页面加载过程中输出当前日期和时间。日期放在了`<strong>`元素中,如同它们之前就包含在HTML页面中一样。这意味着会创建一个DOM元素,以后也可以访问。通过`write()`和`writeln()`输出的任何HTML都会以这种方式来处理。<br />`write()`和`writeln()`方法经常用于动态包含外部资源,如JavaScript文件。在包含JavaScript文件时,记住不能像下面的例子中这样直接包含字符串`"</script>"`,因为这个字符串会被解释为脚本块的结尾,导致后面的代码不能执行:
6. 虽然这样写看起来没错,但输出之后的`"</script>"`会匹配最外层的`<script>`标签,导致页面中显示出`");`。为避免出现这个问题,需要对前面的例子稍加修改:

若有收获,就点个赞吧
0 人点赞
