主从复制配置
受条件限制现只搭一主一从
一主一从和一主多从其实都是一样的,而且从节点也可以有从节点
主从复制都是基于语句进行复制的,安装之类的配置是不会复制的
主节点配置
vim /etc/my.cnf
添加下面的内容
最好所有节点都加上这个配置
注意:需要配置在[mysqld]标签下
server-id=1log-bin=mysql-binlog-slave-updatesslave-skip-errors=all
server-id:服务id 集群中唯一,每个节点不能重名
log-bin:日志文件前缀
log-slave-updates:日志有变化,从节点自动更新
slave-skip-errors=all:跳过所有错误,执行出错的语句不会在从节点同步更新
然后重启服务,登录mysql
输入这个命令查看能看到id说明配置成功
mysql> show variables like 'server_id';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 1 |
+---------------+-------+
1 row in set (0.01 sec)
查看节点状态
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 156 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
可以看到日志文件的全名为mysql-bin.000001位置为156,意思就是说同步从156行开始
这些信息需要在从节点配置
从节点配置
登录从节点的mysql执行
change master to
master_host='主节点ip',
master_user='主节点的用户名',
master_port=主节点的端口,
master_password='密码',
master_log_file='日志文件名(与上面显示的File一致)',
master_log_pos=上面显示的位置(与上面显示的Position一致);
执行举例:
mysql> change master to
-> master_host='192.168.101.51',
-> master_user='root',
-> master_password='1234',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=156;
Query OK, 0 rows affected, 2 warnings (0.03 sec)
-- 开启从节点
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
查看从节点状态
-- \G表示将输出结果格式化,不加没法看
show slave status\G;
是否正常主要看两个参数,都为yes才表示成功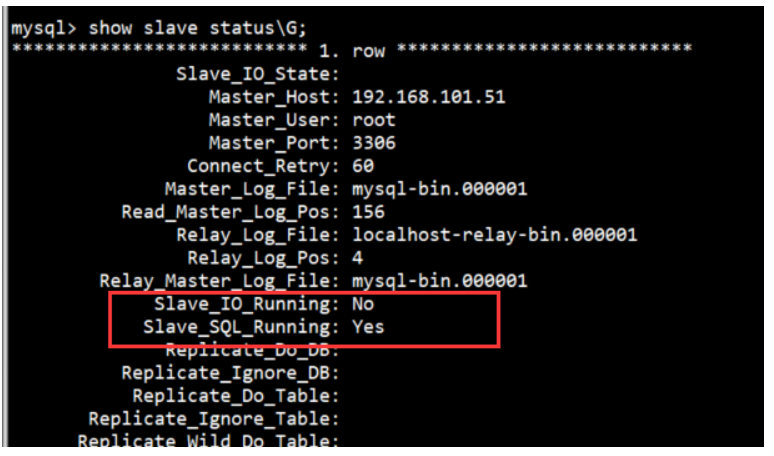
这里Slave_IO_Running为NO可能是因为防火墙没有关闭
systemctl status firewalld查看后发现都关了
于是要看一下出错原因
是因为两个MYSQL服务的UUID相同才导致出错,因为从节点的虚拟机是克隆的所以UUID一样了,必须要不同才行
先关闭两个服务器上的MySQL服务
systemctl stop mysqld
然后都要删除一个文件,这个文件会在启动的时候自动生成
rm -rf /var/lib/mysql/auto.cnf
如果这个路径没有就用locate命令找一下
locate auto.cnf
都删除完了再重启服务systemctl start mysqld

show slave status 各个参数的解释
- Slave_IO_State
这里显示了当前slave I/O线程的状态(slave连接到master的状态)。状态信息和使用show processlist | grep “system user”(会显示两条信息,一条slave I/O线程的,一条是slave SQL线程的)显示的内容一样。
slave I/O线程的状态,有以下几种:
1) waiting for master update
这是connecting to master状态之前的状态
2) connecting to master
I/O线程正尝试连接到master
3) checking master version
在与master建立连接后,会出现该状态。该状态出现的时间非常短暂。
4) registering slave on master
在与master建立连接后,会出现该状态。该状态出现的时间非常短暂。
5) requesting binlog dump
在与master建立连接后,会出现该状态。该状态出现的时间非常短暂。在这个状态下,I/O线程向master发送请求,请求binlog,位置从指定的binglog 名字和binglog的position位置开始。
6) waiting to reconnect after a failed binlog dump request
如果因为连接断开,导致binglog的请求失败,I/O线程会进入睡眠状态。然后定期尝试重连。尝试重连的时间间隔,可以使用命令"change master to master_connect_trt=X;"改变。
7) reconnecting after a failed binglog dump request
I/O进程正在尝试连接master
8) waiting for master to send event
说明,已经成功连接到master,正等待二进制日志时间的到达。如果master 空闲,这个状态会持续很长时间。如果等待的时间超过了slave_net_timeout(单位是秒)的值,会出现连接超时。在这种状态下,I/O线程会人为连接失败,并开始尝试重连
9) queueing master event to the relay log
此时,I/O线程已经读取了一个event,并复制到了relay log 中。这样SQL 线程可以执行此event
10) waiting to reconnect after a failed master event read
读取时出现的错误(因为连接断开)。在尝试重连之前,I/O线程进入sleep状态,sleep的时间是master_connect_try的值(默认是60秒)
11) reconnecting after a failed master event read
I/O线程正尝试重连master。如果连接建立,状态会变成"waiting for master to send event"
12) waiting for the slave sql thread to free enough relay log space
这是因为设置了relay_log_space_limit,并且relay log的大小已经整张到了最大值。I/O线程正在等待SQL线程通过删除一些relay log,来释放relay log的空间。
13) waiting for slave mutex on exit
I/O线程停止时会出现的状态,出现的时间非常短。
- Master_Host
mysql主库的ip地址
- Master_User
这个是master上面的一个用户。用来负责主从复制的用户,创建主从复制的时候建立的(具有reolication slave权限)。
- Master_Port
master服务器的端口 一般是3306
- Connect_Retry
连接中断后,重新尝试连接的时间间隔。默认值是60秒。
与master相关的日志的信息
- Master_Log_File
当前I/O线程正在读取的主服务器二进制日志文件的名称。
- Read_Master_Log_Pos
当前I/O线程正在读取的二进制日志的位置。
与relay log相关的信息
- Relay_Log_File
当前slave SQL线程正在读取并执行的relay log的文件名。
- Relay_Log_Pos
当前slave SQL线程正在读取并执行的relay log文件中的位置;(Relay_Log_File下的Relay_Log_Pos其实一一对应着Relay_Master_Log_File的Exec_Master_Log_Pos。)
- Relay_Master_Log_File
当前slave SQL线程读取并执行的relay log的文件中多数近期事件,对应的主服务器二进制日志文件的名称。(说白点就是我SQL线程从relay日志中读取的正在执行的sql语句,对应主库的sql语句记录在主库的哪个binlog日志中)
slave I/O和SQL线程的状态(重要)
- Slave_IO_Running
I/O线程是否被启动并成功地连接到主服务器上。
- Slave_SQL_Running
SQL线程是否被启动。
- Replicate_Do_DB
Replicate_Ignore_DB
Replicate_Do_Table
Replicate_Ignore_Table
Replicate_Wild_Do_Table
Replicate_Wild_Ignore_Table
这些参数都是为了用来指明哪些库或表在复制的时候不要同步到从库,但是这些参数用的时候要小心,因为 当跨库使用的时候 可能会出现问题。
一般情况下 ,限制的时候都用Replicate_Wild_Ignore_Table这个参数。
- Last_Errno
Last_Error
slave的SQL线程读取日志参数的的错误数量和错误消息。错误数量为0并且消息为空字符串表示没有错误。
如果Last_Error值不是空值,它也会在从属服务器的错误日志中作为消息显示。
- Skip_Counter
SQL_SLAVE_SKIP_COUNTER的值,用于设置跳过sql执行步数。
- Exec_Master_Log_Pos
slave SQL线程当前执行的事件,对应在master相应的二进制日志中的position。(结合Relay_Master_Log_File理解,而且在Relay_Master_Log_File这个值等于Master_Log_File值的时候,Exec_Master_Log_Pos是不可能超过Read_Master_Log_Pos的。)
- Relay_Log_Space
所有原有的中继日志结合起来的总大小。
- Until_Condition
Until_Log_File
Until_Log_Pos
在START SLAVE语句的UNTIL子句中指定的值。
Until_Condition具有以下值:
- 如果没有指定UNTIL子句,则没有值
- 如果从属服务器正在读取,直到达到主服务器的二进制日志的给定位置为止,则值为Master
- 如果从属服务器正在读取,直到达到其中继日志的给定位置为止,则值为Relay
Until_Log_File和Until_Log_Pos用于指示日志文件名和位置值。日志文件名和位置值定义了SQL线程在哪个点中止执行。
- Master_SSL_Allowed
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Master_SSL_Verify_Server_Cert
Master_SSL_Crl:
Master_SSL_Crlpath:
这些字段显示了被从属服务器使用加密相关的参数。这些参数用于连接主服务器。
Master_SSL_Allowed具有以下值:
- 如果允许对主服务器进行SSL连接,则值为Yes
- 如果不允许对主服务器进行SSL连接,则值为No
- 如果允许SSL连接,但是从属服务器没有让SSL支持被启用,则值为Ignored。
与SSL有关的字段的值对应于–master-ca,–master-capath,–master-cert,–master-cipher和–master-key选项的值。
- seconds_Behind_Master
这个值是时间戳的差值。是slave当前的时间戳和master记录该事件时的时间戳的差值。
- Last_IO_Errno:
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
最后一次I/O线程或者SQL线程的错误号和错误消息。
- Replicate_Ignore_Server_Ids
主从复制,从库忽略的主库服务器Id号。就是不以这些服务器Id为主库。
- Master_Server_Id
Master_UUID
Master_Info_File
分别表示主库服务器id号,主库服务器的UUID好,还有在从库中保存主库服务器相关的目录位置。
- SQL_Delay
一个非负整数,表示秒数,Slave滞后多少秒于master。
- SQL_Remaining_Delay
当 Slave_SQL_Running_State 等待,直到MASTER_DELAY秒后,Master执行的事件,此字段包含一个整数,表示有多少秒左右的延迟。在其他时候,这个字段是NULL。
- Slave_SQL_Running_State:
SQL线程运行状态:
- Reading event from the relay log
线程已经从中继日志读取一个事件,可以对事件进行处理了。
- Has read all relay log; waiting for the slave I/O thread to update it
线程已经处理了中继日志文件中的所有事件,现在正等待I/O线程将新事件写入中继日志。
- Waiting for slave mutex on exit
线程停止时发生的一个很简单的状态。
- Master_Retry_Count
连接主库失败最多的重试次数。
- Master_Bind:
slave从库在多网络接口的情况下使用,以确定用哪一个slave网络接口连接到master。
- Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
最后一次I/O线程或者SQL线程错误时的时间戳。
GTID模式相关
- Retrieved_Gtid_Set:
获取到的GTID
- Executed_Gtid_Set:
执行过的GTID
- Auto_Position
记录在GTID模式下是否开启了自动事务校验。
- replicate_rewrite_db
同步的时候需要更改的db名称,例如
master与slave同步fandb这个库,但因为需要slave需要将fandb改名为dudb,master不能改,就需要这个参数。在Slave端的my.cnf中加入
replicate-rewrite-db=fandb->dudb
- Channel_Name
在多源复制下(5.7支持),复制通道的名称,可以有多个。

若有收获,就点个赞吧
0 人点赞
