安装之间去官网下压缩包就行了 https://zookeeper.apache.org/releases.html
注意:3.5.5以上的版本要下载文件名带有bin的
我这里下载的最新版本是apache-zookeeper-3.6.1-bin.tar.gz
配置参数
安装启动zookeeper都非常简单,主要改conf/zoo.cfg文件就行了,conf目录下面本没有zoo.cfg,把zoo_sample.cfg改个名就行了
- tickeTime:心跳时间间隔(ms)
- initLimit:心跳帧,用于集群中Leader(主节点)和Flower(从节点)初始化时通信时限,集群中的follower跟随者服务器(F)与leader领导者服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)initLimit* tickTime,用它来限定集群中的Zookeeper服务器连接到Leader的时限。
- syncLimit:leader与folleower之间的最大响应时间,超过syncLimit * tickTime,Leader认为follower挂掉
- dataDir: 必须配置! 数据文件目录+数据持久化路径,如果目录不存在需要自己创建
- clientPort:连接端口

选举机制
- 半数机制:集群半数以上机器存活,集群可用,所以zookeeper适合安装奇数台服务器
- 只有一个为leader,其余为follower,leader通过内部选举机制产生
- 每个服务启动都先投票给自己,但如果没有超过半数就没有选出leader,于是就投给当前myid号大的,依次类推直到有超过半数的投票leader就选出来了,这种选举机制只是启动的时候
节点类型
- 持久节点:客户端和服务器断开连接后,创建的节点不删除
- 持久化节点
- 持久化顺序编号节点,创建znode时设置顺序标识,客户端可以通过顺序号推断事件的顺序
- 临时节点:客户端和服务器断开连接后,创建的节点删除,临时节点也可以创建序列化节点
- 容器节点
监听机制
动态感知节点的变化,传到客户端
集群配置
至少需要三个节点
三个服务器上在上面配置的dataDir目录里创建一个文件myid
myid只用写一个数字即可,id集群内唯一
echo 2 | tee zkData/myid
三个节点的myid都建好了就改zoo.cfg的配置
格式:server.{myid}={ip地址}:{选举通信端口}:{选举通信端口}
# cluster
server.2=192.168.101.51:2888:3888
server.3=192.168.101.50:2888:3888
server.4=192.168.101.52:2888:3888
都改好了就可以启动了,这里的三台服务器至少启动两台(半数以上),集群内的zookeeper才可以工作
[root@localhost zookeeper]# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@localhost zookeeper]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
客户端命令操作
查看目录
-s 就是详情,老版本是ls2
ls -s [目录]
创建目录,3.4.x必须有内容,3.5.5以后可以创建空节点了
不加参数:普通节点
-e:短暂节点,客户端连接断开就消失
-s:序列号节点
-c:容器节点
create [目录] "内容"
给目录加内容或更新 -s 表详情
set -s /threekingdom/wei "caocao"
获取目录内容 -s 表详情信息
get -s /threekingdom/wei
监听节点内容变化
get和ls命令都可以get 用于监听内容,ls用于监听子节点
3.4.x
get /threekingdom watch
3.5.5以后
get -w /threekingdom
只能监听一次
删除节点
delete /threekingdom/wei
递归删除
deleteall /threekingdom
分布式配置文件
zookeeper的节点有点类似redis的存储方式,即key:value格式
将配置消息序列化成json格式字符串作为节点的值即可
create /order/config "{k:v}"
监听器原理
- 首先有一个main()线程
- 在main线程中创建zookeeper客户端,这是会创建客户端,一个负责网络通信(connect),一个负责监听(listener)
- 通过connect线程将注册的监听事件发生给zookeeper
- 在zookeeper注册监听器列表将注册的监听事件添加到列表中
- zookeeper监听到右数据或路径变化,就会将消息发送给listener线程
- listener线程内部调用有process()方法,该方法由程序员写

- 监听节点数据变化
get -w path - 监听子节点增减变化
ls -w path
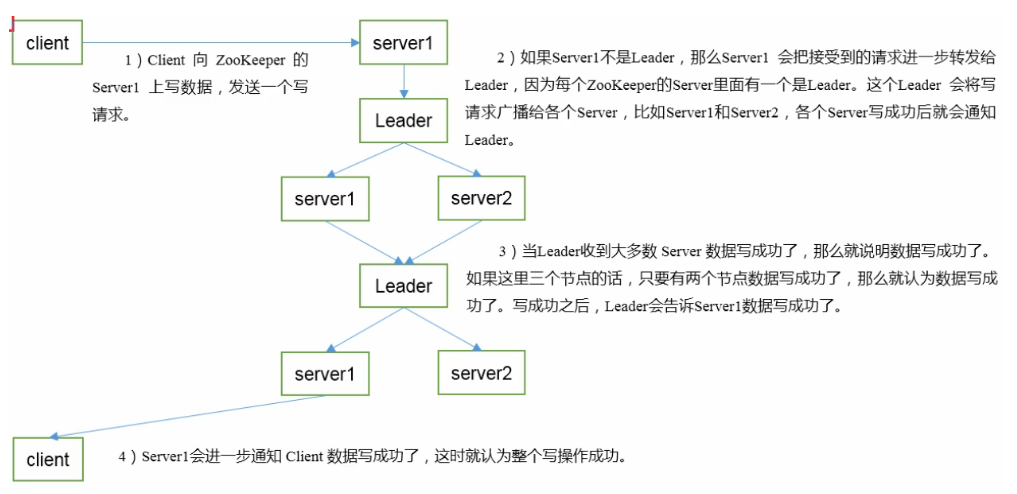
写数据流程
Java Api
Java操作zookeeper的方法和客户端命令基本比较像
采坑记
maven依赖,因为我用的zookeeper版本是3.6.1所以导的依赖版本也一致
<!-- zookeeper -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.1</version>
</dependency>
java客户端连接zookeeper是异步请求,所以这里要用一下JUC的减法计数器类,让异步变同步
如果不加进行操作比如创建节点的时候就会报错
//集群连接地址
private final String connectString = "192.168.101.50:2181,192.168.101.53:2181,192.168.101.52:2181";
//连接超时时间
private final int sessionTimeout = 5000;
private ZooKeeper zkClient;
private final CountDownLatch countDownLatch = new CountDownLatch(1);
//连接zookeeper集群
@Before
public void init() throws Exception {
//三个参数:1.连接的ip地址 2.超时时间(ms) 3.监听器类 我这里使用lambda表达式写法
//zookeeper客户端连接是异步的请求,所以要用一下减法计数器
zkClient = new ZooKeeper(connectString, sessionTimeout, watchedEvent -> {
if (watchedEvent.getState() == Watcher.Event.KeeperState.SyncConnected) {
System.out.println("Watch received event");
//连接成功就减一 线程就不阻塞
countDownLatch.countDown();
}
});
//没连接成功就阻塞
countDownLatch.await();
}
创建节点方法
//创建节点
@Test
public void createNode() throws KeeperException, InterruptedException {
// 参数1:要创建的节点路径 参数2:数据 参数3:访问权限 参数4:节点类型
// CreateMode.PERSISTENT_SEQUENTIAL是临时节点
// CreateMode.PERSISTENT是永久节点
// CreateMode.EPHEMERAL 带序号的永久节点
// CreateMode.EPHEMERAL_SEQUENTIAL 带序号的临时节点
String path = zkClient.create("/threekingdom", "luoguanzhong".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("添加的路径为:" + path);
}
获取子节点
//获取子路径和监听
@Test
public void getDataAndWatch() throws KeeperException, InterruptedException {
//获取子节点的路径和是否监听
List<String> children = zkClient.getChildren("/", true);
for (String path : children) {
System.out.println("节点:" + path);
//获取节点
// 第二个参数是 启用监听 上面启用了这里就不启用了
// 第三个参数是 stat对象这里不需要传入
byte[] data = zkClient.getData("/" + path, false, null);
System.out.println(new String(data));
}
//阻塞就可以获取监听方法的信息了
Thread.sleep(Long.MAX_VALUE);
}
判断节点存不存在,以及获取节点
@Test
public void exist() throws KeeperException, InterruptedException {
//返回的Stat记录了该节点的具体信息,比如版本号,删除节点的时候有用
Stat stat = zkClient.exists("/threekingdom", false);
System.out.println("=============");
System.out.println(stat.getVersion());
}
分布式锁
节点已经创建过,其他人就不能创建了,这个特点就可以作为分布式锁
线程创建节点,该节点已存在就就监听,不存在就创建临时节点,完成业务就删除节点
创建的不是临时节点就会造成死锁现象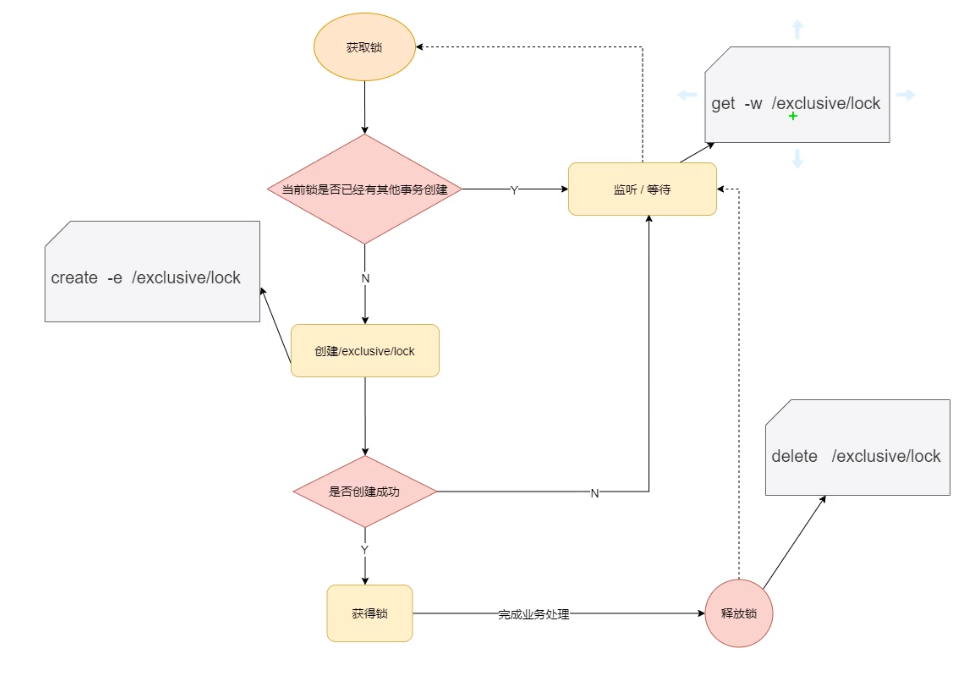
但是这样的加锁方式效率有点低了,每次只能有一个线程获取锁,其他线程就要等,是为羊群效应
所以采用顺序节点的方式更好,避免羊群效应
分布式锁 选zk还是redis
zookeeper是CP架构,先复制再返回
redis是AP架构,先返回再复制
通常优先考虑AP
zookeeper可靠性更好,redis效率更高、速度更快
没有绝对的谁好,根据业务场景权衡
Java代码实现
直接使用zookeeper的java api实现起来有点麻烦,这里要使用Netflix开源的一套框架curator来实现zk分布式锁
用起来非常简单,用springboot整合,springboot的代码就不用复制了
maven依赖
<!-- zookeeper分布式锁 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.3.0</version>
</dependency>
配置类
返回一个CuratorFramework对象,注意配置Bean注解的参数initMethod = “start”
初始化之后会调用CuratorFramework类底层的start方法
@Configuration
public class CuratorCfg {
@Bean(initMethod = "start")
public CuratorFramework curatorFramework() {
//超时时间 重试次数
RetryPolicy retryPolicy = new ExponentialBackoffRetry(5000, 3);
//客户端连接zookeeper 配置zookeeper集群的ip和端口
CuratorFramework client =
CuratorFrameworkFactory.newClient("192.168.101.50:2181,192.168.101.53:2181,192.168.101.52:2181",
retryPolicy);
return client;
}
}
分布式锁使用
注入CuratorFramework对象,然后使用InterProcessMutex对象的方法实现分布式锁
@Autowired
private CuratorFramework curatorFramework;
@GetMapping("/stock/reduce/{id}")
public Object reduceStock(@PathVariable Integer id) throws Exception {
// 创建作为分布式锁的节点节点,节点命名最好是跟业务相关
// 该方法底层会先帮我们创建父节点
InterProcessMutex processMutex = new InterProcessMutex(curatorFramework, "/product/" + id);
//加锁 该方法有两种
// 一种是有参 加锁成功超时时间
// 一种是无参 等到他加锁成功
// 这里用的是无参方法
try {
processMutex.acquire();
//根据id减库存的方法 具体代码就不复制了
goodInfoService.reduceStock(id);
} catch (Exception e) {
e.printStackTrace();
}finally {
//释放锁
processMutex.release();
}
return "ok!!!!!!!!";
}

若有收获,就点个赞吧
0 人点赞
