java8特性 stream使用小记
类似SQL的操作
尽量使用stream而不用循环
可以基于stream流实现过滤,排序,查找等一系列操作
stream对象中还有一个parallel()方法很重要,并行流,数据很多的时候用来加快效率
public class TestStreamAPI {private static List<Employee> employees = Arrays.asList(new Employee("张三", 18, 8888, Status.BUSY),new Employee("李四", 58, 9999, Status.FREE),new Employee("赵六", 28, 3333, Status.VOCATION),new Employee("王五", 28, 4444, Status.FREE),new Employee("田七", 22, 5555, Status.FREE));public static void main(String[] args) {//中间操作// 除非触发终止操作 否者中间操作不会处理Stream<Employee> stream = employees.stream()//内部迭代.filter((e) -> e.getAge() > 20)// //截取 获取指定数量的元素// .limit(2)// //跳过前n个元素// .skip(2)//根据hashcode和equals方法去重 需要重写这两个方法// .distinct();//终止操作// 一次性执行全部操作Optional<Employee> optional = stream// 映射 对每个元素都进行相应的操作// 提取名字// .map(Employee::getName)// sorted排序方法// 无参 自然排序// 有参 定制排序/* .sorted(//以年龄升序// Comparator.comparing(Employee::getAge)//使用此方法reverseOrder()就是降序Comparator.comparing(Employee::getAge, Comparator.reverseOrder())//其余按此方法升序或降序.thenComparing(Employee::getNum, Comparator.reverseOrder()))*///提取最大值// .max(Comparator.comparing(Employee::getAge));//提取最小值.min(Comparator.comparing(Employee::getAge));System.out.println(optional.get());/*查找与匹配allMatch 检查是否匹配所有元素anyMatch 检查是否至少匹配一个元素noneMatch 检查是否没有匹配元素findFirst 返回第一个元素findAny 返回任意元素count 返回元素个数max 返回流中最大值min 返回流中最小值*/boolean b = employees.stream()// .allMatch(m -> m.getStatus().equals(Status.BUSY));.anyMatch(m -> m.getStatus().equals(Status.BUSY));int sum = employees.stream().mapToInt(Employee::getAge).sum();System.out.println(sum);System.out.println(b);}}enum Status {/*** 空闲*/FREE,/*** 忙碌*/BUSY,/*** 休假*/VOCATION}
List根据某一字段分组
Map<String, List<IpConfigSearchVo>> ipCollect = ipAll.stream().collect(Collectors.groupingBy(IpConfigSearchVo::getDiscoveryConfigId));
List根据某一字段进行去重
dataSourcesList = dataSourcesList.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(//根据ip字段去重Comparator.comparing(XX::getIpAddress))), ArrayList::new));
List转Map
List<User> userList = Arrays.asList(
new User().setId("B").setName("张三"),
new User().setId("A").setName("李四"),
new User().setId("A").setName("张窟窿"),
new User().setId("C").setName("王五")
);
//第三个参数表示 key冲突时取新的
Map<String, String> useMap = userList.stream()
.collect(Collectors.toMap(User::getId, User::getName, (key1, key2) -> key1));
//第四个参数表示 自定义返回map类型
Map<String, String> useMap2 = userList.stream()
.collect(Collectors.toMap(User::getId, User::getName, (key1, key2) -> key1, LinkedHashMap::new));
List聚合
例:将多个List
list.stream()
.flatMap(List::stream)
//去重
.distinct()
.collect(Collectors.toList());
函数式接口
Java8提供四大函数式接口,均只提供一个方法,传输时可直接用lambda表达式
函数式接口不止这些,但很多相似
- Consumer
消费型接口 void accept(T t); - 传一个参数然后对参数进行相应的操作
- Supplier
供给型接口 T get(); - 产生对象
- Function
- Predicate
断言型接口 boolean test(T t); - 用于判断
try(){}与try{}
Java7新特性,支持使用try后面跟随()括号管理释放资源
例如通常使用try代码块
try {
fis = new FileInputStream(source);
fos = new FileOutputStream(target);
byte[] buf = new byte[8192];
int i;
while ((i = fis.read(buf)) != -1) {
fos.write(buf, 0, i);
}
}
catch (Exception e) {
e.printStackTrace();
} finally {
close(fis);
close(fos);
}
现在可以这么写,注意圆括号
try (
InputStream fis = new FileInputStream(source);
OutputStream fos = new FileOutputStream(target)
){
byte[] buf = new byte[8192];
int i;
while ((i = fis.read(buf)) != -1) {
fos.write(buf, 0, i);
}
}
catch (Exception e) {
e.printStackTrace();
}
try括号内的资源会在try语句结束后自动释放,前提是这些可关闭的资源必须实现 java.lang.AutoCloseable 接口
权限管理中的递归操作
资源表设计要求是可以无限制设置子节点,所以在这里就需要用到递归
对应的dto对象需要新加一个属性 private List<ResourceDTO> children 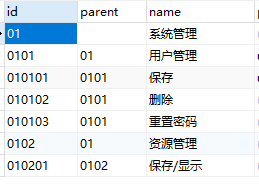
递归获取资源菜单 伪代码
使用mybatis plus提供的增删改查api,充分利用java8 新特性
解释一下为什么要先查询所有行
我看到我们公司的代码中递归获取资源菜单是在递归中查询数据库,这样的话效率会比较低,而资源表的数据一般不会很多,一次性把所有行查询出来,在java层面进行递归会好一些
public List<ResourceDTO> resourceList() {
//先把资源信息先全部查出来
List<ResourcePO> poList = this.list();
//将po集合转为dto集合
List<ResourceDTO> resources = CopyUtils.copyList(poList, ResourceDTO.class);
//只保留一级节点(父节点为空的节点) 用于页面展示
List<ResourceDTO> collect = resources.stream()
.filter(r -> StringUtils.isEmpty(r.getParent()))
.collect(Collectors.toList());
//获取子节点及子节点的子节点
return collect
.stream()
.map(resource -> resource.setChildren(getChildrenById(resource.getId(), resources)))
.collect(Collectors.toList());
}
/**
* 根据id递归查找子孙节点
*
* @param id 节点id
* @param tree 所有节点
* @return java.util.List<com.halayang.server.resource.dto.ResourceDTO>
* @author YangYudi
* @date 2021/2/18 16:37
*/
private List<ResourceDTO> getChildrenById(String id, List<ResourceDTO> tree) {
return tree.stream()
.filter(resourceDTO -> id.equals(resourceDTO.getParent()))
.map(resourceDTO -> resourceDTO.setChildren(getChildrenById(resourceDTO.getId(), tree)))
.collect(Collectors.toList());
}
递归删除资源菜单 伪代码
在删除一个节点时要连同子孙节点全部删除,也需要用到递归
根据id获取子孙的id集合进行批量删除
public boolean deleteResources(String id) {
List<String> ids = new ArrayList<>();
ids.add(id);
//先查询所有
List<ResourcePO> poList = this.list();
//根据节点id 查询子孙节点id 保存到一个list上
getChildrenIds(id, poList, ids);
return this.removeByIds(ids);
}
/**
* 根据当前节点id递归获取子孙节点id列表 保存到一个list上
*
* @param id id
* @param list 所有节点
* @param ids 结果集
* @author YangYudi
* @date 2021/2/18 17:22
*/
private void getChildrenIds(String id, List<ResourcePO> list, List<String> ids) {
list.forEach(resource -> {
if (resource.getParent().equals(id)) {
ids.add(resource.getId());
getChildrenIds(resource.getId(), list, ids);
}
});
}
lombok注解搭配spring注入
在类上加,自动生成构造方法,而且是懒加载
@RequiredArgsConstructor(onConstructor_ = {@Lazy})
被引用的类加final
private final RestTemplate restTemplate;

若有收获,就点个赞吧
0 人点赞
