什么是NoSQL,它是“Not Only SQL”的缩写,它的意义是:适用关系型数据库的时候就使用关系型数据库,不适用关系型数据库的时候也没有必要非使用关系型数据库不可,可以考虑使用更加合适的数据存储
关系型数据库简史
1969年,埃德加·弗兰克·科德(Edgar Frank Codd)发表了一篇跨时代的论文,首次提出来关系数据模型店概念
数据库分类
数据库根据不同的数据模型(数据的表现形式)主要分成层次型、网络型和关系型3种。
1、层次型数据库
早期的数据库称为层次型数据库,数据的关系都是以简单的树形结构来定义的。这种非常简单的构造在碰到复杂数据的时候往往会造成数据的重复(同一数据在数据库中反复出现),出现数据冗余问题。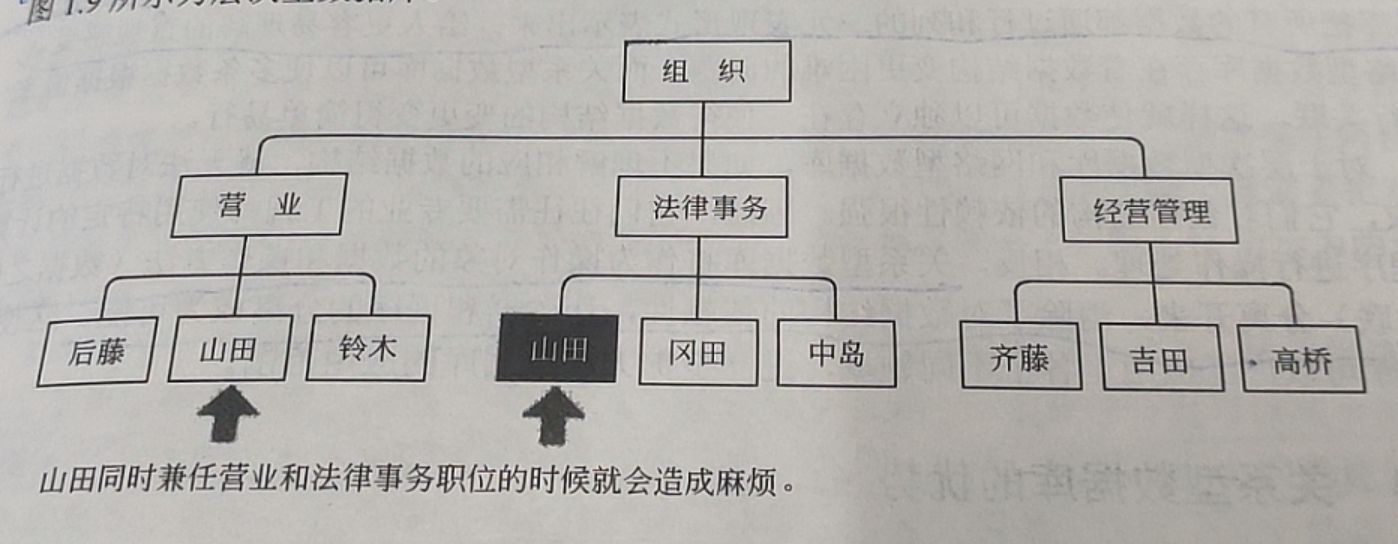
2、网络型数据库
它拥有层次数据库相近的数据结构,同时各种数据又如同网状交织在一起。网络型数据库对数据结构有很强的依赖性,不理解散据结构就无法进行相应的数据访问。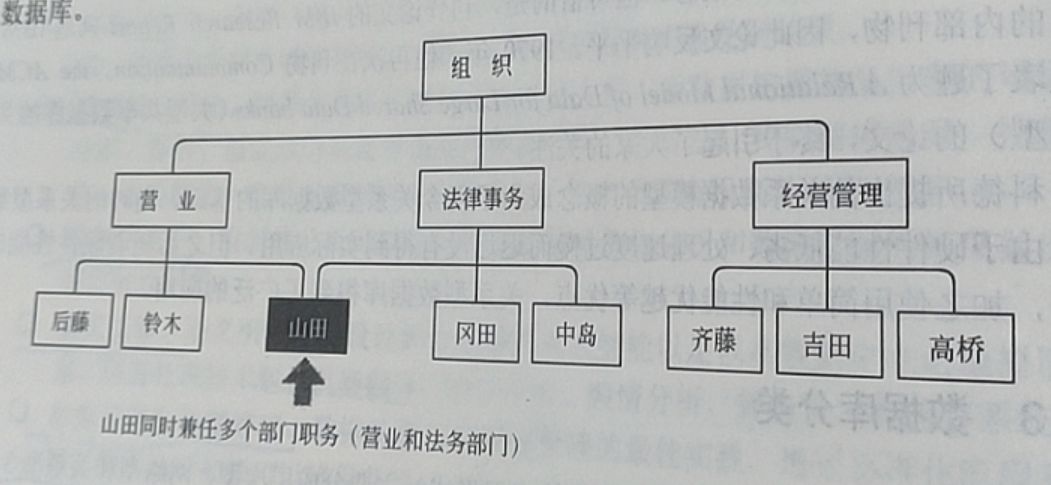
3、关系型数据库
关系型数据库把所有的数据通过行和列的二元表现形式表示出来,给人更容易理解的直观感受。关系型数据库将作为操作对象的数据和操作方法(数据之间的关联)分离开来,消除了对数据结构的依赖性,让数据和程序的分离成为可能。这使得数据库可以广泛应用于各个不同的领域,进一步扩大了数据库的应用范围。
关系型数据库的优势
1、通用性及高性能
2、突出的优势:
- 保持数据的一致性(事务处理)
- 由于以标准化为前提,数据更新的开销很小(相同字段基本都只有一处)
- 可以进行Join等复杂查询
- 存在很多实际成果和专业技术信息(成熟的技术)
不擅长的处理
也就是缺点:
- 大量数据的写入操作
- 为有数据更新的表做索引或表结构(schema)变更
- 字段不固定时应用
- 对简单查询需要快速返回结果的处理
1、大量的数据写入处理
在数据读入方面,由复制产生的主从模式(数据的写入由主数据库负责,数据的读取由从数据库负责),可以比较简单地通过增加从数据库来实现规模化。但是,在数据的写入方面却完全没有简单的方法来解决规模化问题。例如,要想将数据的写入规模化,可以考虑把主数据库从一台增加到两台,作为互相关联复制的二元主数据库来使用。确实这样似乎可以把每台主数据库的负荷减少一半,但是更新处理会发生冲突(同样的数据在两台服务器同时更新成其他值),可能会造成数据的不一致。为了避免这样的问题,就需要把对每个表的请求分别分配给合适的主数据库来处理,这就不那么简单了。图1.11所示为两台主机问题,图1.12所示为二元主数据库问题的解决办法。
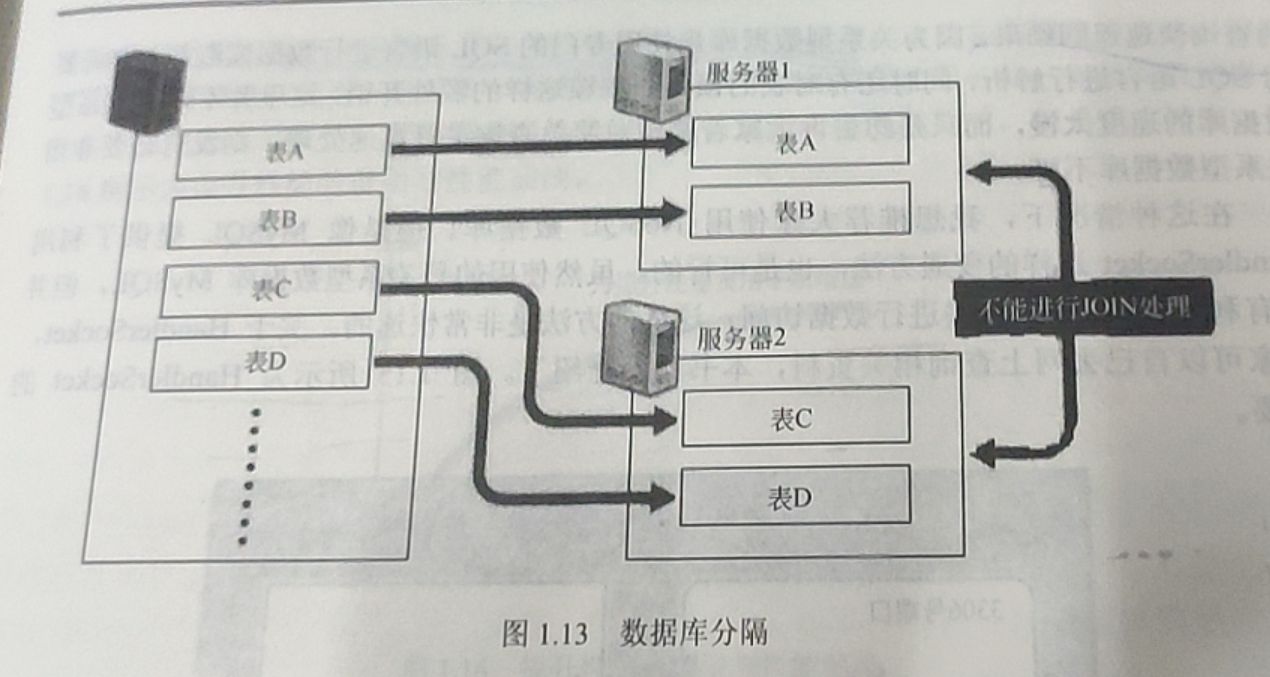
另外也可以考虑把数据库分割开来,分别放在不同的数据库服务器上,比如将这个表放在这个数据库服务器上,那个表放在那个数据库服务器上。数据库分割可以减少每台数据库服务器上的数据量,以便减少硬盘IO(输入/输出)处理,实现内存上的高速处理,效果非常显著。但是,由于分别存储在不同服务器上的表之间无法进行JOIN 处理,数据分割的时候就需要预先考虑这些问题。数据库分割之后,如果一定要进行JOIN处理,就必须要在程序中进行关联,这是非常困难的。图1.13所示为数据库分割。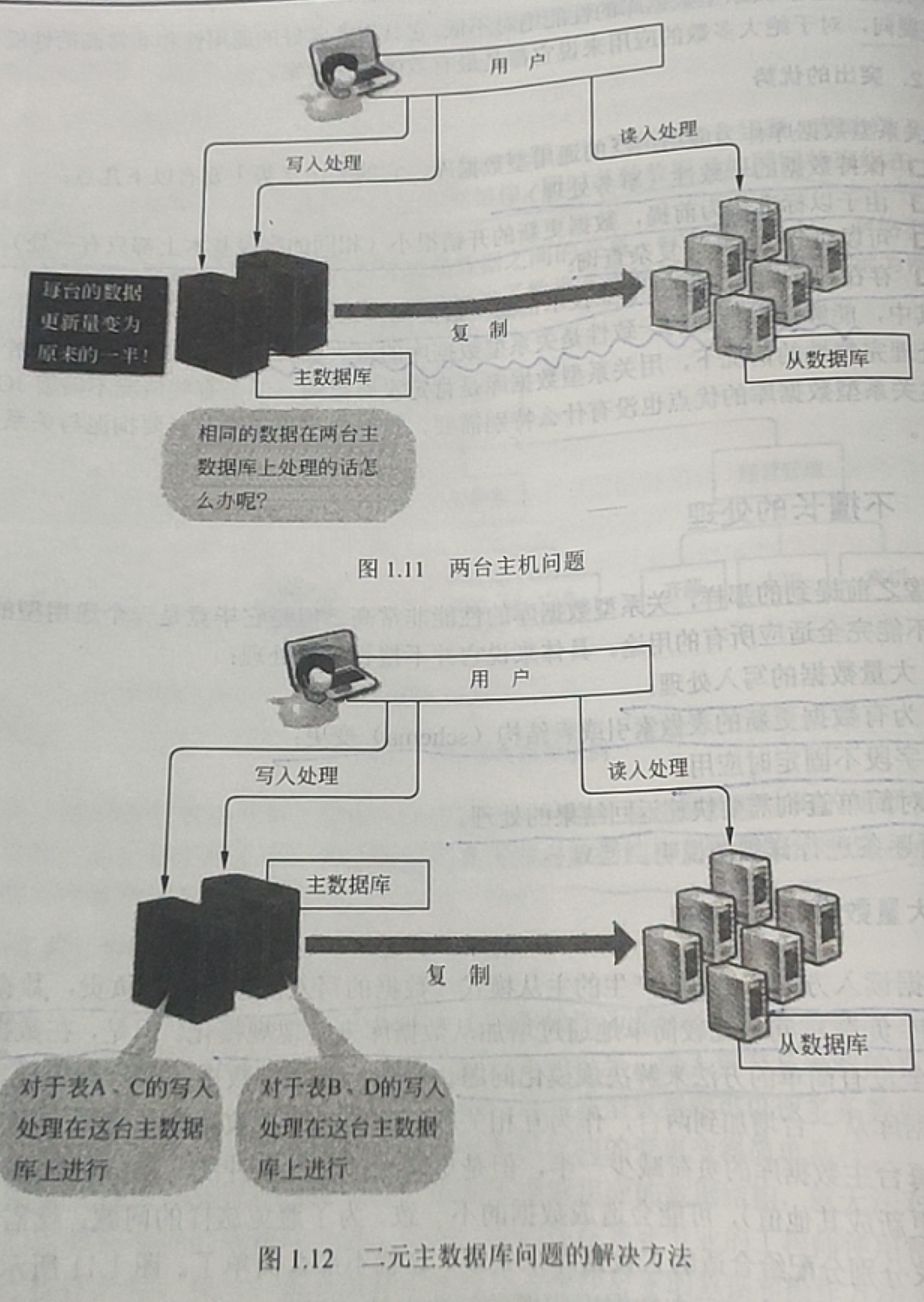
2、为有数据更新的表做索引或表结构(schema)变更
在使用关系型数据库时,为了加快查询速度需要创建索引,为了增加必要的字段就一定需要改变表结构。为了进行这些处理,需要对表进行共享锁定,这期间数据变更(更新、插入和删除等)是无法进行的。如果需要进行一些耗时操作(例如为数据量比较大的表创建索引或者是变更其表结构),就需要特别注意:长时间内数据可能无法进行更新。
3、字段不固定时的应用
如果字段不固定,利用关系型数据库也是比较困难的。有人会说:“需要的时候,加个字段就可以了”,这样的方法也不是不可以,但在实际运用中每次进行反复的表结构变更是非常痛苦的
4、对简单查询需要快速返回结果的处理
关系型数据库并不擅长对简单查询快速返回结果
NoSQL数据库
1、易于数据的分散
关系型数据库不擅长大量数据的写入处理,各个数据之间存在关联是关系型数据库得名的主要原因。如果想要使服务器能够轻松地处理更大量的数据,那么只有2种选择:
- 提升性能:通过提升现行服务器自身的性能来提高处理能力
- 增大规模:使用多台廉价的服务器来提高处理能力
2、不对大量数据进行处理的话就没有使用的必要吗
错,以下这些用途可以感受到NoSQL的好处:
- 希望顺畅地对数据进行缓存(Cache)处理- 希望对数组或集合类型的数据进行高速处理- 希望将数据全部保存到硬盘上

若有收获,就点个赞吧
0 人点赞
