局部性群组
BigTable允许用户将原本并不存储在一起的数据以列族为单位,根据需要组织在一个单独的SSTable中,以构成一个局部性群组。这实际上就是数据库中垂直分区技术的一个应用。结合图4.24的实例来看,在被BigTable保存的网页列关键字中,有的用户可能只对网页内容感兴趣,那么它可以通过设置局部性群组只看内容这一列。有的则会对诸如网页语言和网站排名等可以用于分析的信息比较感兴趣,它也可以将这些列设置到一个群组中。局部性群组如图4.24所示。<br />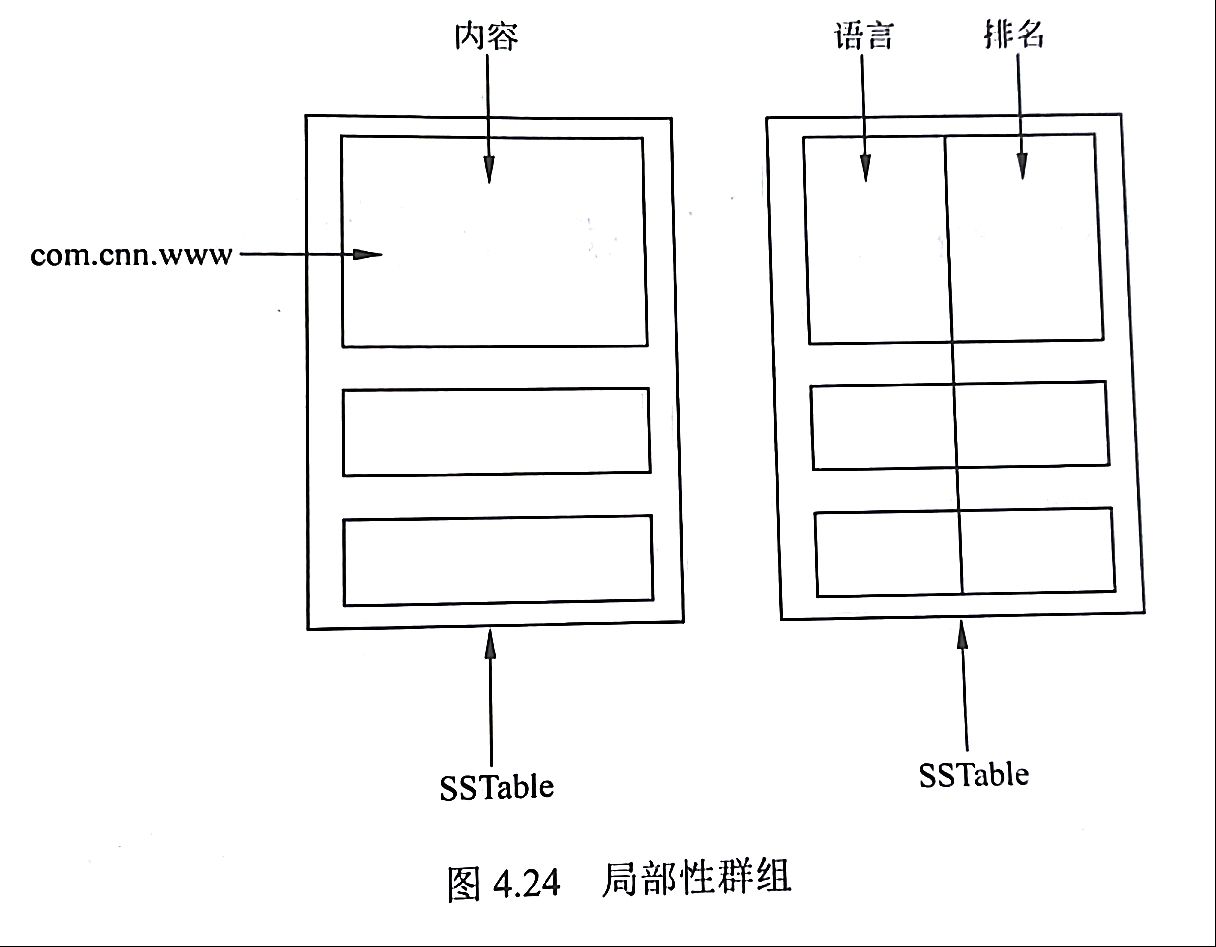
通过设置局部性群组用户可以只看自己感兴趣的内容,对某个用户来说的大量无用信息无需读取。对于一些较小的且会被经常读取的局部性群组,用户可以将其SSTable文件直接加载进内存,这可以明显地改善读取效率。
压缩
压缩可以有效地节省空间,BigTable中的压缩被应用于很多场合。首先压缩可以被用在构成局部性群组的SSTable 中,可以选择是否对个人的局部性群组的SSTable进行压缩。BigTable中这种压缩是对每个局部性群组独立进行的,虽然这样会浪费一些空间,但是在需要读时解压速度非常快。通常情况下,用户可以采用两步压缩的方式:第一步利用Bentley& McIlroy方式(BMDiff)在大的扫描窗口将常见的长串进行压缩;第二步采取Zippy技术进行快速压缩,它在一个16KB大小的扫描窗口内寻找重复数据,这个过程非常快。压缩技术还可以提高子表的恢复速度,当某个子表服务器停止使用后,需要将上面所有的子表移至另一个子表服务器来恢复服务。在转移之前要进行两次压缩,第一次压缩减少了提交日志中的未压缩状态,从而减少了恢复时间。在文件正式转移之前还要进行一次压缩,这次压缩主要是将第一次压缩后遗留的未压缩空间进行压缩。完成这两步之后压缩的文件就会被转移至另一个子表服务器。
布隆过滤器(Bloom Filter)
BigTable向用户提供了一种称为布隆过滤器的数学工具。布隆过滤器是巴顿·布隆在1970年提出的,实际上它是一个很长的二进制向量和一系列随机映射函数,在读操作中确定子表的位置时非常有用。布隆过滤器的速度快,省空间。而且它有一个最大的好处是它绝不会将一个存在的子表判定为不存在。不过布隆过滤器也有一个缺点,那就是在某些情况下它会将不存在的子表判断为存在。不过这种情况出现的概率非常小,跟它带来的巨大好处相比这个缺点是可以忍受的。
目前包括Google Analytics、Google Earth、个性化搜索、Orkut和 RRS阅读器在内的几十个项目都使用了BigTable。这些应用对 BigTable的要求及使用的集群机器数量都是各不相同的,但是从实际运行来看,BigTable完全可以满足这些不同需求的应用,而这一切都得益于其优良的构架以及恰当的技术选择。与此同时 Google还在不断地对 BigTable进行一系列的改进,通过技术改良和新特性的加入提高系统运行效率及稳定性。

若有收获,就点个赞吧
0 人点赞
