BigTable是一个分布式多维映射表,表中的数据是通过一个行关键字(Row Key)、一个列关键字(Column Key)及一个时间戳(Time Stamp)进行索引的。BigTable对存储在其中的数据不做任何解析,一律看做字符串,具体数据结构的实现需要用户自行处理。BigTable的存储逻辑可以表示为:
(row:string,column:string,time:int64)——> string
BigTable数据的存储结构如图所示: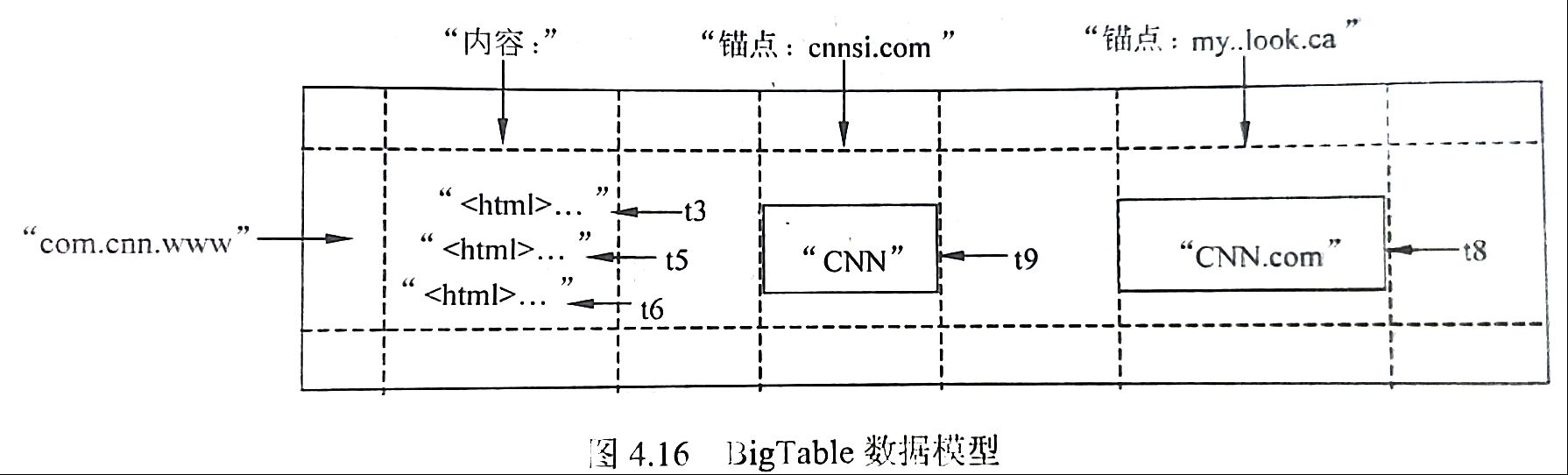
1、行
BigTable的行关键字可以是任意的字符串,但是大小不能够超过64KB。BigTable和传统的关系型数据库有很大不同,它不支持一般意义上的事务,但能保证对于行的读写操作具有原子性(Atomic)。表中数据都是根据行关键字进行排序的,排序使用的是词典序。图4.16是 BigTable数据模型的一个典型实例,其中com.cn.www就是一个行关键字。不直接存储网页地址而将其倒排是BigTable的一个巧妙设计。这样做至少会带来以下两个好处。
(1)同一地址域的网页会被存储在表中的连续位置,有利于用户查找和分析。
(2)倒排便于数据压缩,可以大幅提高压缩率。
单个的大表由于规模问题不利于数据的处理,因此BigTable将一个表分成了很多子表( Tablet),每个子表包含多个行。子表是 Big Table 中数据划分和负载均衡的基本单位。
2、列
BigTable并不是简单地存储所有的列关键字,而是将其组织成所谓的列族(Column Family),每个族中的数据都属干同一个类型,并且同族的数据会被压缩在一起保存。引入了列族的概念之后,列关键字就采用下述的语法规则来定义。
族名 :限定词(family :qualifier)
族名必须有意义,限定词则可以任意选定。在图4.16中,内容(Contents)和锚点(Anchor,就是HTML中的链接)都是不同的族。而cnnsi.com和 my.look.ca则是锚点族中不同的限定词。通过这种方式组织的数据结构清晰明了,含义也很清楚。族同时也是BigTable中访问控制(Access Control)的基本单元,也就是说访问权限的设置是在族这级别上进行的。
3、时间戳
Google的很多服务比如网页检索和用户的个性化设詈等都需要保存不同时间的数据,这些不同的数据版本必须通过时间戳来区分。图4.16中内容列的t3、t5和 t6表明其中保存了在t3、t5和t6这三个时间获取的网页。BigTable中的时间戳是64位整型数,具体的赋值方式可以采取系统默认的方式,也可以用户自行定义。
为了简化不同版本的数据管理,BigTable目前提供了两种设置:一种是保留最近都N个不同版本,图4.16中数据模型采取点就是这种方法,它保存最新的三个版本数据。另一种就是保留限定时间内的所有不同版本,比如可以保存最近10天的所有不同版本数据。失效的版本将会由BigTable的垃圾回收机制自动处理。

若有收获,就点个赞吧
0 人点赞
