轮流放置是最简单的划分方法:即每条元组都会被依次放置在下一个节点上,以此进行循环。
一般在实际应用中为了处理的方便,通常按照主键的值来决定次序从而进行划分。即给定一个表T,表T的划分键(Partitioning Key)是k,需要划分的节点数目N,那么元组t∈T将会被放置在节点n上面,其中n=t.k mod N。由于划分只与划分键有关,因此我们可以把对元组的划分简化为对数字的划分,对于不是数字的键值可以通过其他方式比如哈希转化为数字形式。如图: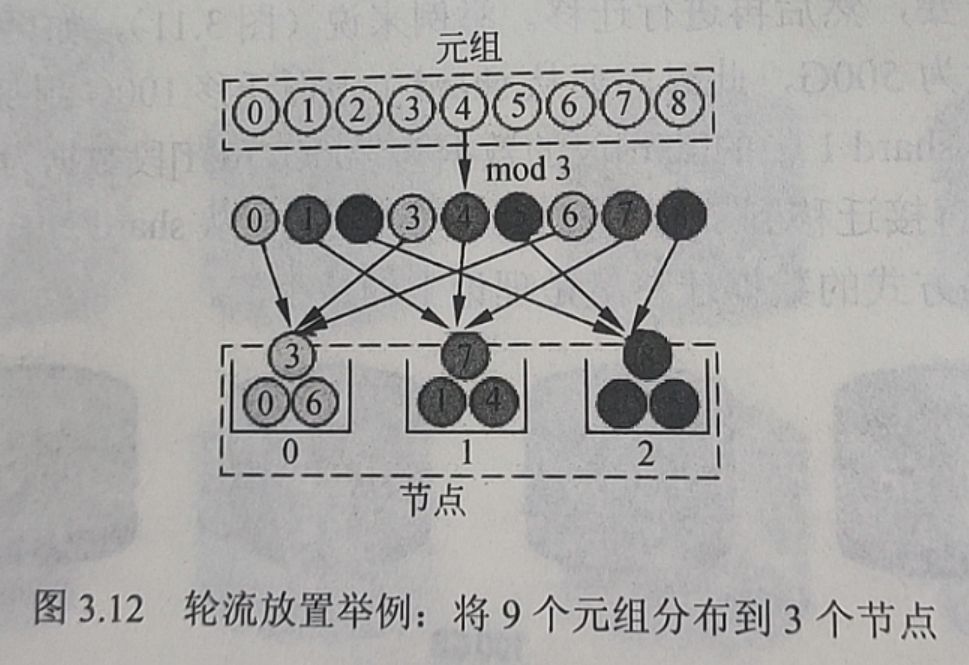
但是,简单的直接用划分键上的值来计算放置节点的算法可能会造成数据的不均匀。因此,轮流放置有很多改进版,比如说哈希方式(Hashing),即n=hash(t.k)mod N。先将划分键的值进行hash操作,变成一个与输入分布无关、输出均匀的值,然后再进行取模操作。哈希函数可以有很多选择,你可以针对你的应用的特征去选取。
优点:轮流放置算法的实现非常简单,而且几乎不需要元数据就可以进行查询的路由,因此有着比较广泛的应用。例如,EMC 的Greenplum的分布式数据仓库采用的就是轮流放置和哈希相结合的方式。
缺点:轮流放置同样具有很明显的缺点。当系统中添加或者删除节点时,数据的迁移量非常巨大。举个有20个节点的例子(图3.13),当系统由4个节点变为5个节点时,会有如下的放置结果:红色部分是mod 4和mod5时结果不相等的情况,不相等意味着这些元组当系统由4个节点变为5个节点时需要进行迁移。也就是说多达80%的元组都需要迁移。数据的迁移会对系统的性能造成很大的影响,严重时可能会中断系统的服务。当系统的节点数目频繁变化时,是不提倡使用这种方式的。
数据迁移量大的问题可以通过改进轮流放置算法来达到,比较常见的两个改进算法是一致性哈希和范围分区划分算法。

若有收获,就点个赞吧
0 人点赞
