前面我们说到Sharding可以简单定义为将大数据库分布到多个物理节点上的一个分区方案。每个 shard都被放置在一个节点上面。Sharding系统是一个 shared-nothing的系统,基本上都采用图3.6中所示的架构。最下面是很多数据库服务器节点,每个节点上面都会运行一个或多个数据库的实例。中间一层叫做查询路由器,客户端的连接都通过它进行转发。查询路由器负责解析用户的查询语句,并将这些语句转发到包含有所需要的数据的shard 节点上面去执行。执行的结果也会通过查询路由器进行汇总并发送给相应的客户端。
对于这样一个sharding系统,我们需要考虑到下面几个问题:如何将数据划分到多个shard节点上面;用户的查询语句如何正确的转发到相应的节点上面去执行;当节点数据变化的时候怎样重新划分数据。对于数据划分和查询路由来说,所用的算法一般是对应的。下面就讲一下一些常用的数据划分的方法。这里的假设前提是:只考虑单个表,并且这个表的划分键(Partitioning Key)已经被指定。
常见的三种数据划分方式:区间划分(Range-Based Partitioning)、轮流放置(Round-Robin)和一致性哈希(Consistent Hashing)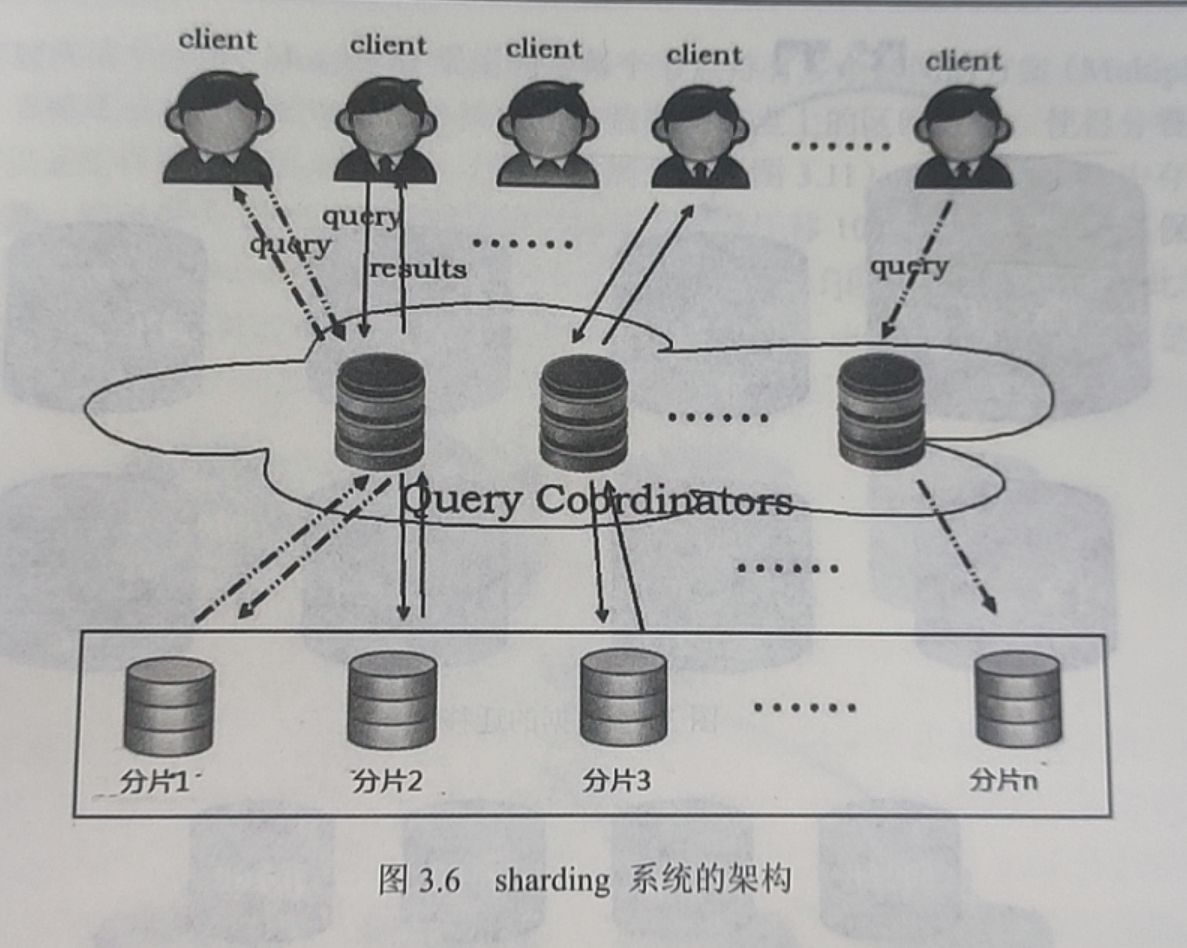

若有收获,就点个赞吧
0 人点赞
