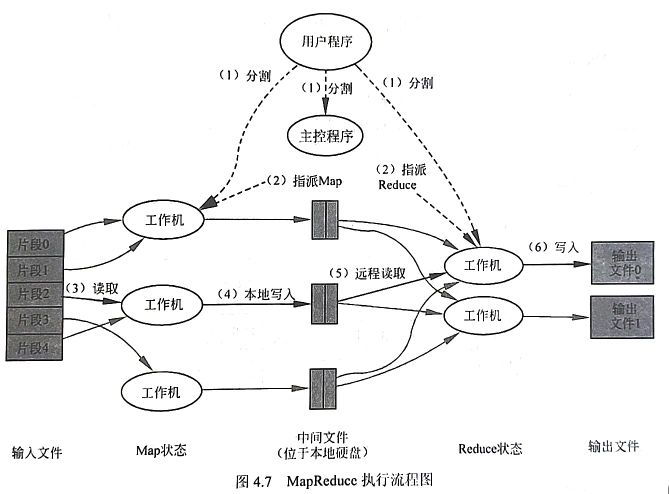
- 用户程序中的MapReduce函数库首先把输入文件分成M块,每块大概16MB~64MB(可以通过参数决定),接着在集群的机器上执行处理程序
- 这些分派的执行程序中有一个程序比较特别,它是主控程序Master。剩下的执行程序都是作为Master分派工作的Worker(工作机)。总共有M个Map任务和R个Reduce任务需要分派,Master选择空闲的Worker来分配这些Map或者Reduce任务
- 一个分配律Map任务的Worker读取并处理相关的输入块。它处理输入的数据,并且将分析出的
对传递给用户定义的Map函数。Map函数产生的中间结果 对暂时缓冲到内存。 - 这些缓冲到内存的中间结果将被定时写到本地硬盘,这些数据通过分区函数分成R个区。中间结果在本地硬盘的位置信息将被发送回Master,然后Master负责把这些位置信息传送给Reducer Worker。
- 当Master通知Reduce的Worker关于中间
对的位置时,它调用远程过程来从Map Worker的本地硬盘上读取缓冲垫中间数据。当Reduce Worker读到所有的中间数据,它就使用中间key进行排序,这样可以使得相同key的值都在一起。因为有许多不同key的Map都对应相同的Reduce任务,所以,排序是必需的。如果中间结果集过于庞大,那么就需要使用外排序。 - Reduce Worker根据每一个唯一中间key来遍历所有的排序后的中间数据,并且把key和相关的中间结果值集合传递给用户定义的Reduce函数。Reduce函数的结果输出到一个最终的输出文件。
- 当所有的Map任务和Reduce任务都已经完成的时候,Master激活用户程序。此时MapReduce返回用户程序的调用点。
由于MapReduce是用在成百上千机器上处理海量数据的,所以容错机制是不可或缺的。总的来说,MapReduce是通过重新执行失效的地方来实现容错的。
1、Master失效
在Master中,会周期性的设置检查点(checkpoint),并导出Master的数据。一旦某个任务失效了,就可以从最近都一个检查点恢复并重新执行。不过由于只有一个Master在运行,如果Master失效,则只能终止整个MapReduce程序的运行并重新开始。
2、Worker失效
相对于Master失效,Worker失效算是一种常见的状态。Master会周期性地给Worker发送ping命令,如果没有Worker应答,则Master认为Worker失效,终止对这个Worker的任务调度,把失效Worker的任务调度到其他Worker上重新执行。
3、案例分析
单词计数(Word Count)是一个经典的问题,也是能体现MapReduce设计思想的最简单算法之一。该算法主要是为了完成对文字数据中所出现的单词进行计数。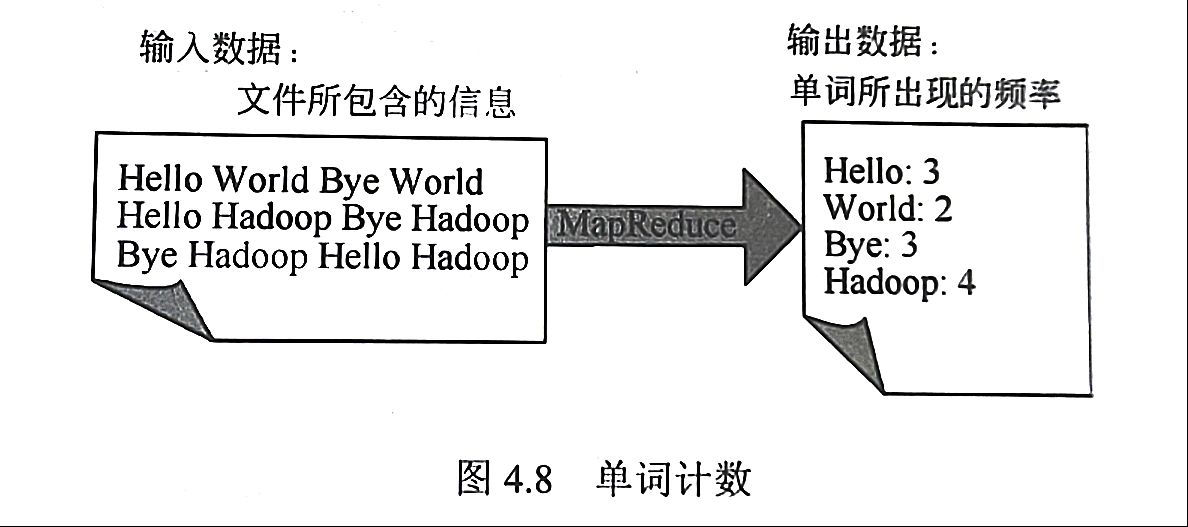
伪代码
Map(K,V){For each word w in V:collect(w,1)}Reduce(K,V[]){int count = 0For each v in V:count += 1collect(K,count)}
- 根据文件所包含的信息分割(Split)文件,在这里把文件的每行分割为一组,共三组。这一步由系统自动完成
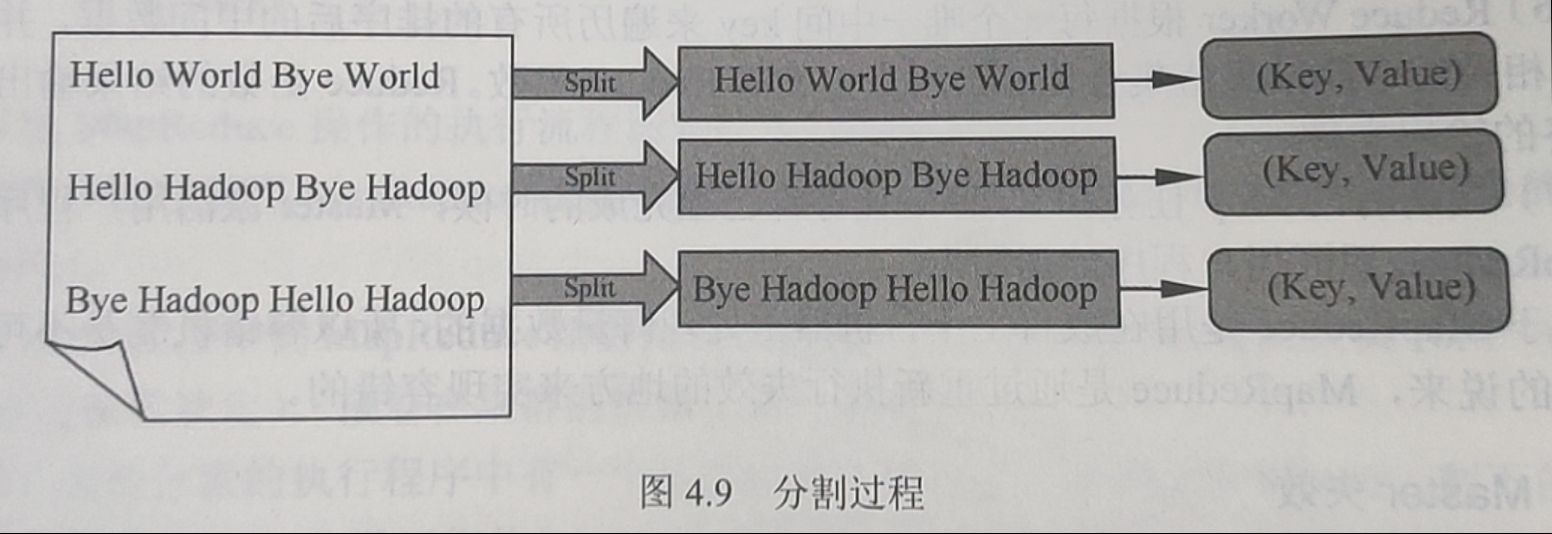
- 对分割之后的每一对
利用用户自定义的Map进行处理,再生成新的 对

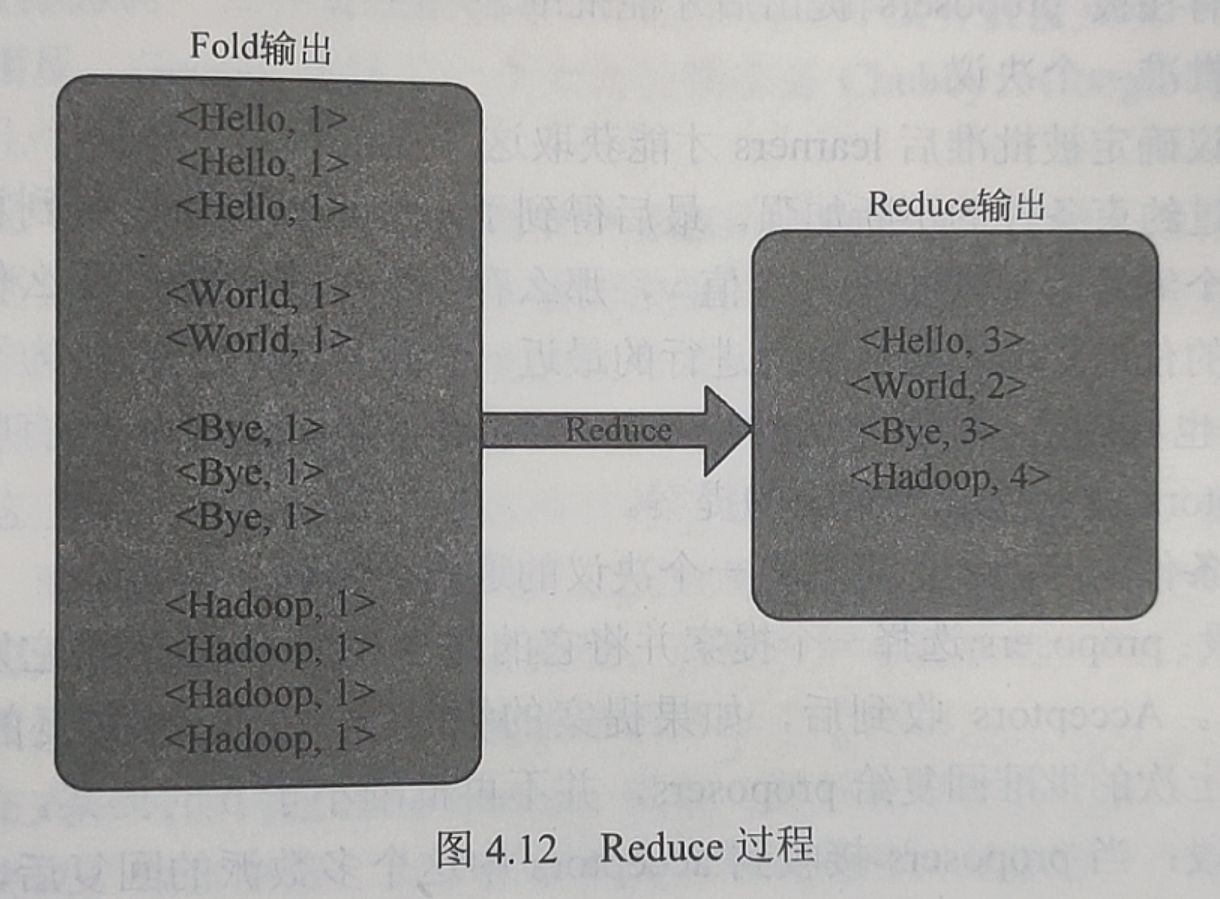
- Map输出之后有一个内部Fold过程,和第一步一样,都是由系统自动完成的
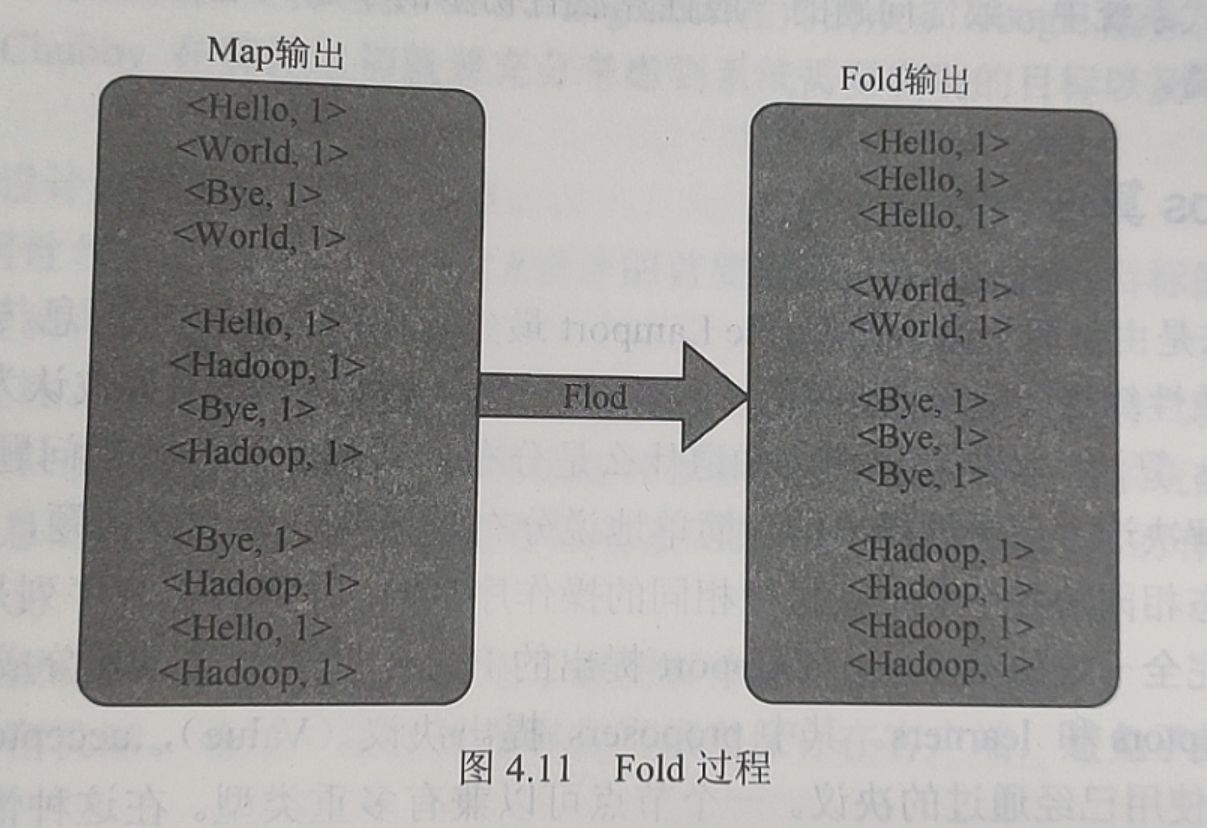
- 经过Fold步骤之后的输出与结果已经非常接近,再由用户定义的Reduce步骤完成最后的工作即可

若有收获,就点个赞吧
0 人点赞
