通常情况下Google 的一个数据中心仅运行一个Chubby单元(Chubby cell,下面会有详细讲解),而这个单元需要支持包括GFS、BigTable在内的众多Google服务。这种苛刻的服务要求使得Chubby 在设计之初就要充分考虑到系统需要实现的目标以及可能出现的各种问题。
Chubby 的设计目标主要有以下几点:
- 高可用性和高可靠性。这是系统设计的首要目标,在保证这一目标的基础上再考虑系统的吞吐量和存储能力。
- 高扩展性。将数据存储在价格较为低廉的RAM,支持大规模用户访问文件。
- 支持粗粒度的建议性锁服务。提供这种服务的根本目的是提高系统的性能。
- 服务信息的直接存储。可以直接存储包括元数据和系统参数在内的有关服务信息,而不需要再维护另一个服务。
- 支持通报机制。客户可以及时地了解到事件的发生。
- 支持缓存机制。通过一致性缓存将常用信息保存在客户端,避免了频繁地访问主服务器。
前面提到在分布式系统中保持数据一致性最常用也最有效的算法是 Paxos,很多系统就是将Paxos算法作为其一致性算法的核心。但是Google并没有直接实现一个包含了Paxos算法的函数库,相反,Google 设计了一个全新的锁服务Chubby。Google做出这种设计主要是考虑到以下几个问题:
(1)通常情况下开发者在开发的初期很少考虑系统的一致性问题,但是随着开发的不断进行,这种问题会变得越来越严重。单独的锁服务可以保证原有系统的架构不会发生改变,而使用函数库的话很可能需要对系统的架构做出大幅度的改动。
(2)系统中很多事件的发生是需要告知其他用户和服务器的,使用一个基于文件系统的锁服务可以将这些变动写入文件中。这样其他需要了解这些变动的用户和服务器直接访问这些文件即可,避免了因大量的系统组件之间的事件通信带来的系统性能下降。
(3)基于锁的开发接口容易被开发者接受。虽然在分布式系统中锁的使用会有很大的不同,但是和一致性算法相比,锁显然被更多的开发者所熟知。
一般来说分布式一致性问题通过quorum机制(简单来说就是根据少数服从多数都选举原则产生一个决议)做出决策,为了保证系统的高可用性,需要若干台机器,但是使用单独的锁服务的话一台机器也能保证这种高可用性。也就是说,Chubby在自身服务的实现时利用若干台机器实现了高可用性,而外部用户利用Chubby则只需一台机器可以保证高可用性
正是考虑到以上几个问题,Google设计了Chubby,而不是单独地维护一个函数库(实际上,Google有这样一个独立于Chubby的函数库,不过一般情况下并不会使用)。在设计的过程中有一些细节问题也值得我们关注,比如在Chubby 系统中采用了建议性的锁而没有采用强制性的锁。两者的根本区别在于用户访问某个被锁定的文件时,建议性的锁不会阻止这种行为,而强制性的锁则会,实际上这是为了便于系统组件之间的信息交互行为。另外 Chubby还采用了粗粒度(Coarse-Grained)锁服务而没有采用细粒度(Fine-Grained)锁服务,两者的差异在于持有锁的时间。细粒度的锁持有时间很短,常常只有几秒甚至更少,而粗粒度的锁持有的时间可长达几天,做出如此选择的目的是减少频繁换锁带来的系统开销。当然用户也可以自行实现细粒度锁,不过建议还是使用粗粒度的锁。
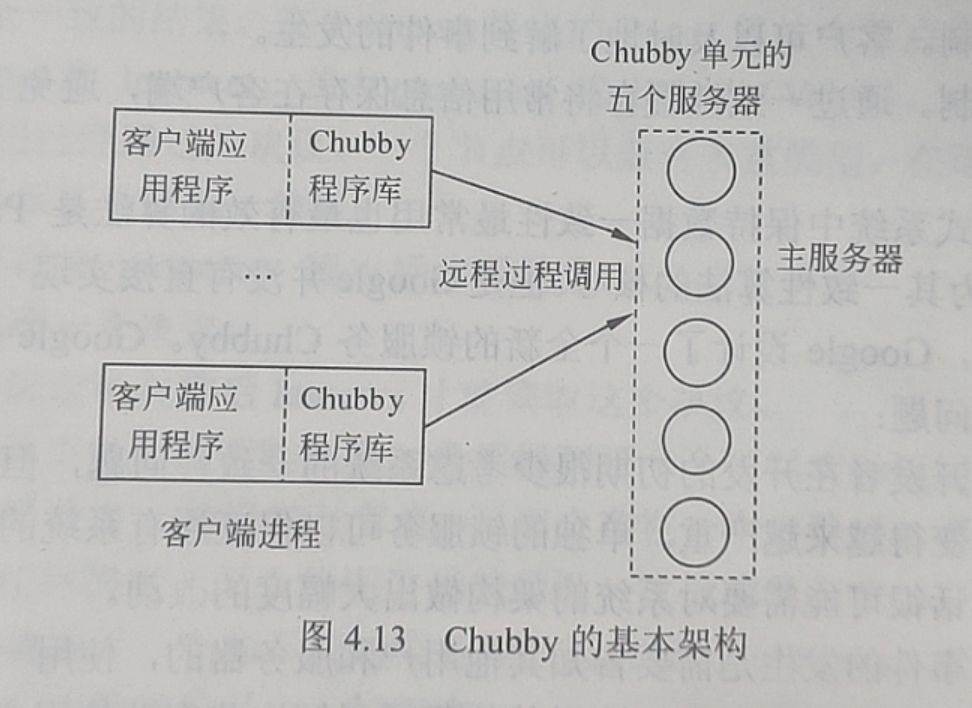
Chubby的基本架构。很明显,Chubby被划分成两个部分:客户端和服务器端,客户端和服务器端之间通过远程过程调用(RPC)来连接。在客户这一端每个客户应用程序都有一个Chubby程序库(Chubby Library),客户端的所有应用都是通过调用这个库中的相关函数来完成的。服务器一端称为Chubby单元,一般是由五个称为副本(Replica)的服务器组成的,这五个副本在配置上完全一致,并且在系统刚开始时处于对等地位。这些副本通过quorum机制选举产生一个主服务器(Master),并保证在一定的时间内有且仅有一个主服务器,这个时间就称为主服务器租约期(Master Lease)。如果某个服务器被连续推举为主服务器的话,这个租约期就会不断地被更新。租约期内的所有客户请求都是由主服务器来处理的。客户端如果需要确定主服务器的位置,可以向DNS发送一个主服务器定位请求,非主服务器的副本将对该请求做出回应,通过这种方式客户端能够快速和准确地对主服务器做出定位。

若有收获,就点个赞吧
0 人点赞
