BigTable中实际的数据都是以子表的形式保存在子表服务器上的,客户一般也只和子表服务器进行通信。
SSTable及子表基本结构
SSTable是Google为BigTable设计的内部数据存储格式。所有的SSTable文件都是存储在GFS上的,用户可以通过键来查询相应的值,如图是SSTable格式的基本示意图: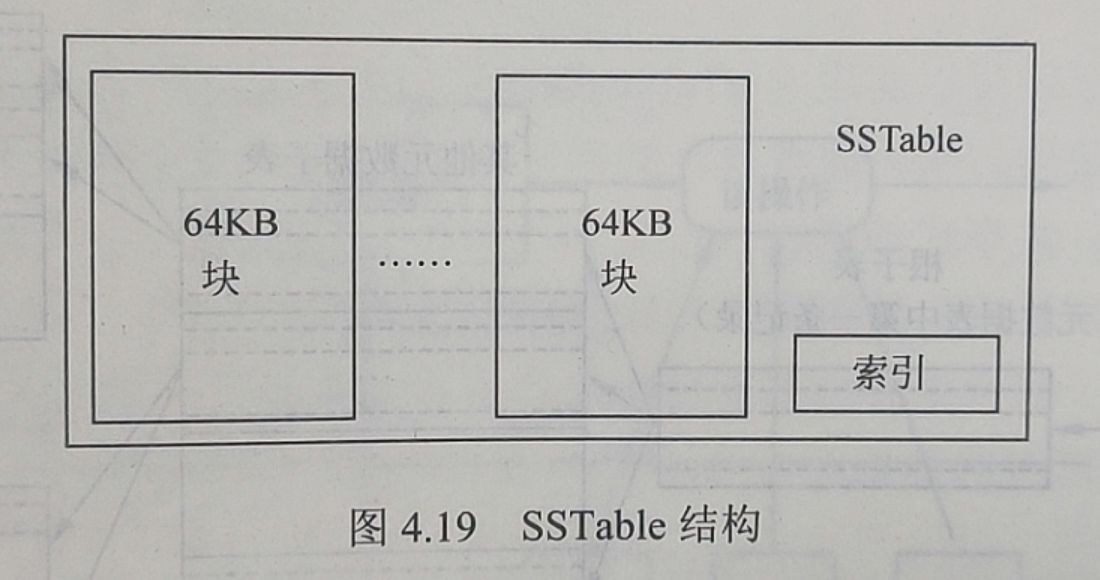
SSTable中的数据被划分成一个一个的块(Block),每个块的大小是可以设置的,一般来说设置为64KB。在SSTable的结尾有一个索引(Index),这个索引保存了SSTable中块的位置信息,在SSTable打开时这个索引会被加载进内存,这样用户在查找某个块时首先在内存中查找块的位置信息,然后在硬盘上直接找到这个块,这种查找方法速度非常快。由于每个SSTable一般都不是很大,用户还可以选择将其整体加载进内存,这样查找起来会更快。
从概念上来讲,子表是表中一系列行的集合,它在系统中的实际组成如下图所示: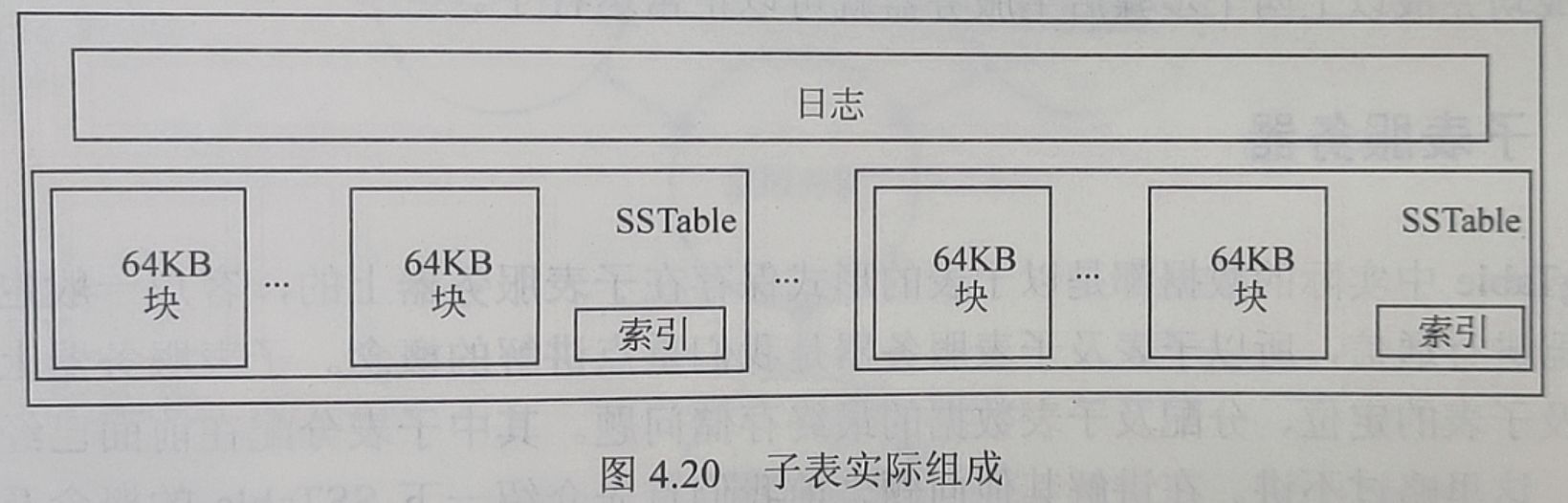
每个子表都是由多个SSTable及日志(Log)文件构成的。有一点需要注意,那就是不同子表的SSTable可以共享,也就是说某些SSTable会参与多个子表的构成,而由子表构成的表则不存在子表重叠的现象。BigTable中的日志文件是一种共享日志,也就是说系统并不是对子表服务器上的每个子表都单独地建立一个日志文件,每个子表服务器上仅保存一个日志文件,某个子表日志只是这个共享日志的一个片段。这样会节省大量的空间,但在恢复时却有一定的难度,因为不同的子表可能会被分配到不同的子表服务器上,一般情况下每个子表服务器都需要读取整个共享日志来获取其对应的子表日志。Google为了避免这种情况出现,对日志做了一些改进。BigTable规定将日志的内容按照键值进行排序,这样不同的子表服务器都可以连续读取日志文件了。一般来说每个子表的大小在100MB~200MB之间。每个子表服务器上保存的子表数量可以从几十到上千不等,通常情况下是100个左右
子表地址
子表地址的查询是经常碰到的操作。在BigTable系统的内部采用的是一种类似B+树的三层查询体系。子表地址结构如下图所示: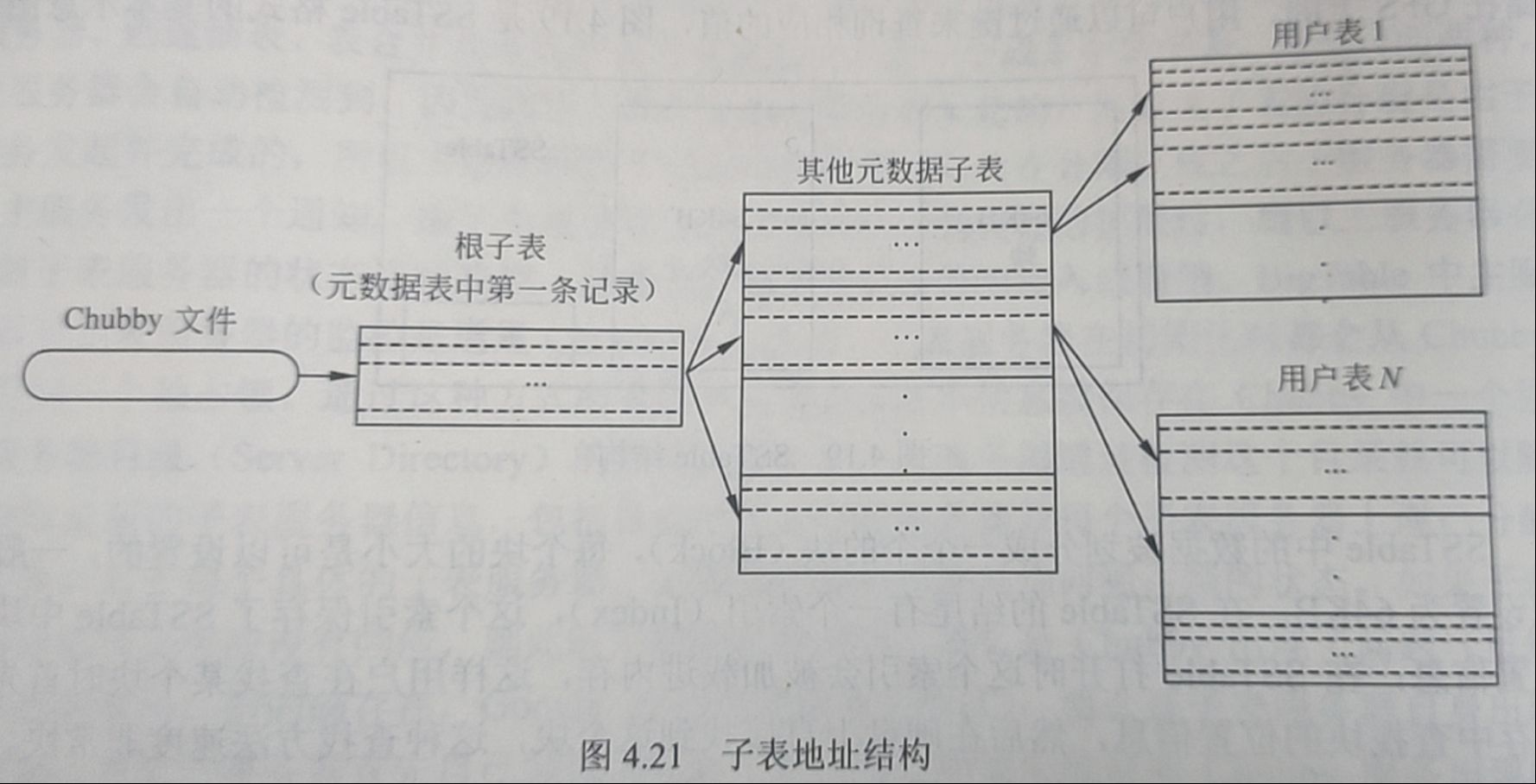
所有的子表地址都被记录在元数据表中,元数据表也是由一个个的元数据子表(Metadata tablet)组成的。根子表是元数据表中一个比较特殊的子表,它既是元数据表的第一条记录,也包含了其他元数据子表的地址,同时 Chubby中的一个文件也存储了这个根子表的信息。这样在查询时,首先从 Chubby中提取这个根子表的地址,进而读取所需的元数据子表的位置,最后就可以从元数据子表中找到待查询的子表。除了这些子表的元数据之外,元数据表中还保存了其他一些有利于调试和分析的信息,比如事件日志等。
为了减少访问开销,提高客户访问效率 BigTable使用了缓存(Cache)和预取(Prefetch)技术,这两种技术手段在体系结构设计中是很常用的。子表的地址信息被缓存在客户端,客户在寻址时直接根据缓存信息进行查找。一旦出现缓存为空或缓存信息过时的情况,客户端就需要按照图4.21所示的方式进行网络的来回通信(Network Round-trips)进行寻址,在缓存为空的情况下需要三个网络来回通信。如果缓存的信息是过时的,则需要六个网络来回通信。其中三个用来确定信息是过时的,另外三个获取新的地址。预取则是在每次访问元数据表时不仅仅读取所需的子表元数据,而是读取多个子表的元数据,这样下次需要时就不用再次访问元数据表。
子表数据存储及读写操作
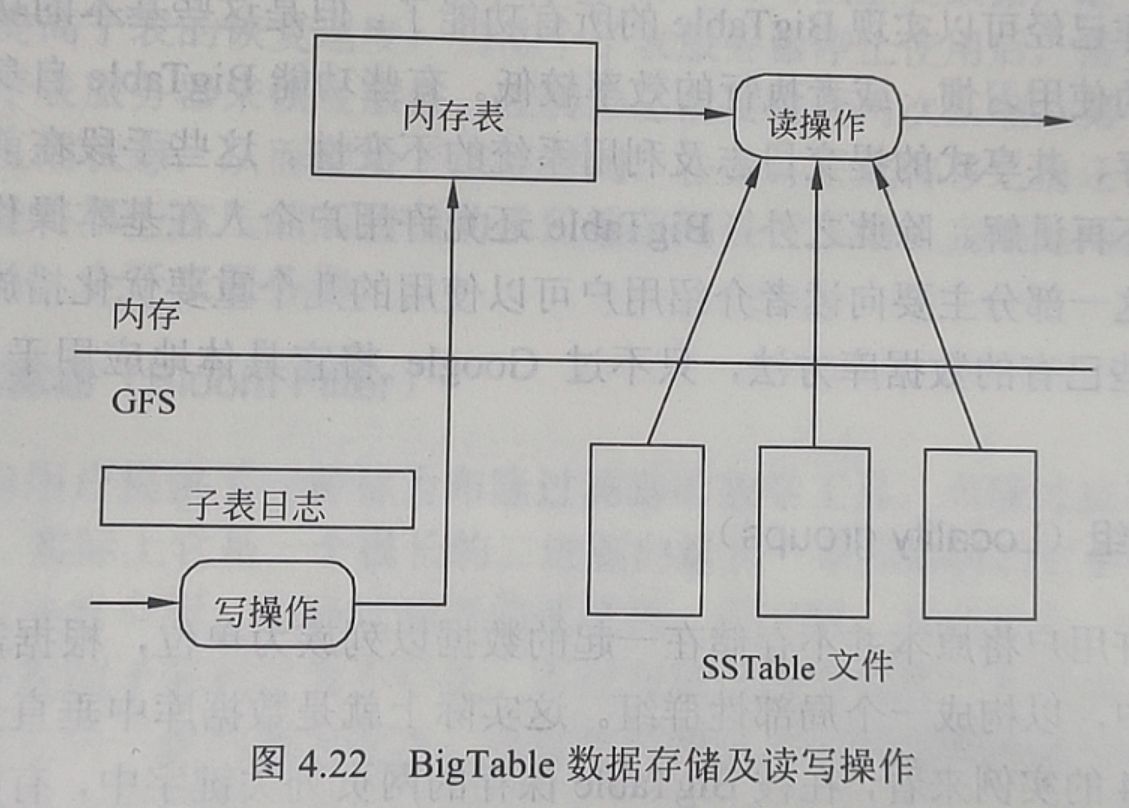
在数据的存储方面BigTable做出了一个非常重要的选择,那就是将数据存储划分成两块。较新的数据存储在内存中一个称为内存表(Memtable)的有序缓冲里,较早的数据则以 SSTable格式保存在GFS 中。这种技术在数据库中不是很常用,但Google还是做出了这种选择,实际运行的效果也证明Google的选择虽然大胆却是正确的。
从图4.22中可以看出读和写操作有很大的差异性。做写操作(Write Op)时,首先查询Chubby中保存的访问控制列表确定用户具有相应的写权限,通过认证之后写入的数据首先被保存在提交日志(Commit Log)中。提交日志中以重做记录(Redo Record)的形式保存着最近的一系列数据更改,这些重做记录在子表进行恢复时可以向系统提供已完成的更改信息。数据成功提交之后就被写入内存表中。在做读操作(Rcad Op)时,首先还是要通过认证,之后读操作就要结合内存表和SSTable 文件来进行,因为内存表和SSTable中都保存了数据。
在数据存储中还有一个重要问题,就是数据压缩的问题。内存表的空间毕竟是很有限的,当其容量达到一个阈值时,旧的内存表就会被停止使用并压缩成SSTable格式的文件。在 BigTable 中有三种形式的数据压缩,分别是次压缩(Minor Compaction)、合并压缩(Merging Compaction)和主压缩(Major Compaction)。三者之间的关系如图4.23所示。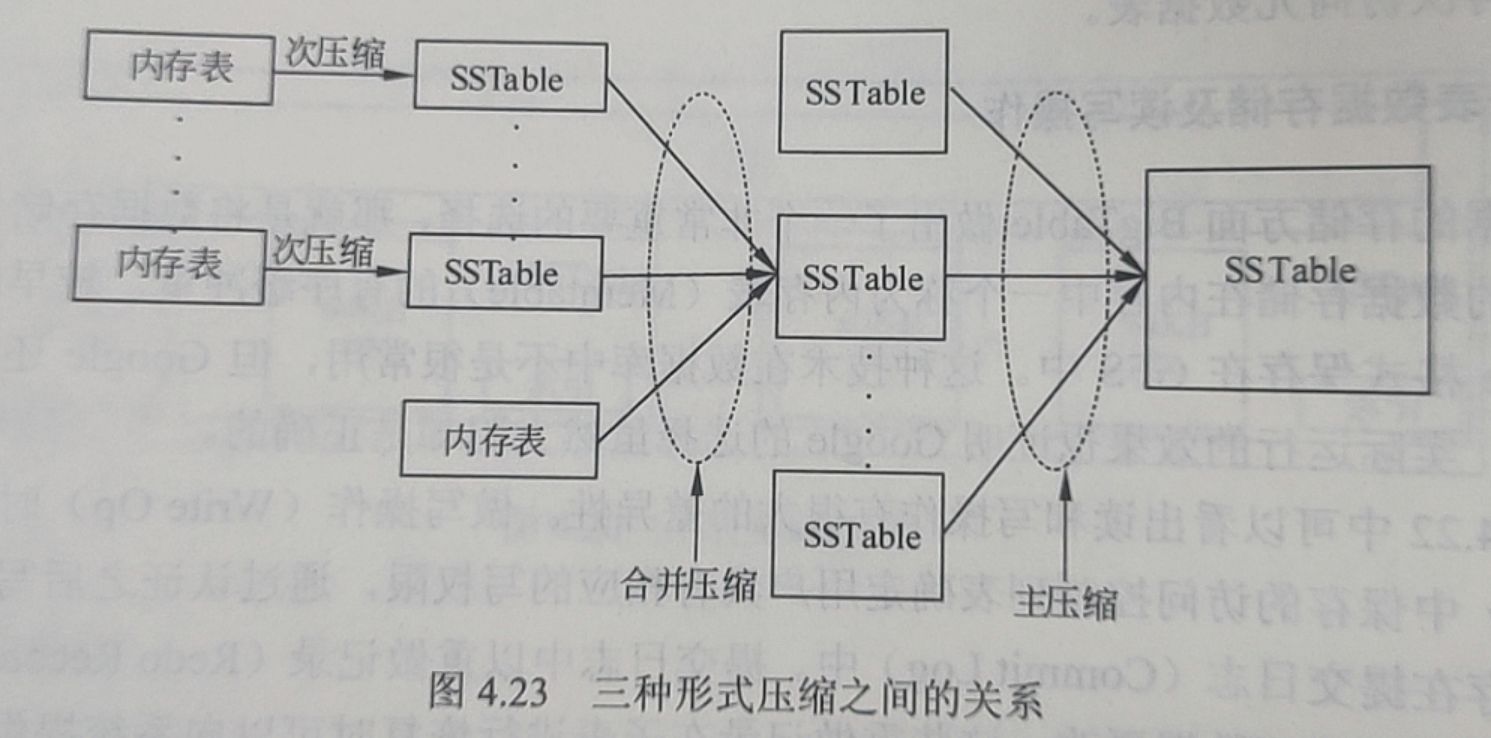
每一次旧的内存表停止使用时都会进行一个次压缩操作,这会产生一个SSTable。但如果系统中只有这种压缩的话,SSTable的数量就会无限制地增加下去。由于读操作要使用SSTable,数量过多的SSTable显然会影响读的速度。而在 BigTable 中,读操作实际上比写操作更重要,因此BigTable 会定期地执行一次合并压缩的操作,将一些已有的SSTable和现有的内存表一并进行一次压缩。主压缩其实是合并压缩的一种,只不过它将所有的SSTable一次性压缩成一个大的SSTable文件。主压缩也是定期执行的,执行一次主压缩之后可以保证将所有的被压缩数据彻底删除,如此一来,既回收了空间又能保证敏感数据的安全性(因为这些敏感数据被彻底删除了)。

若有收获,就点个赞吧
0 人点赞
