BigTable是在Google的另外三个云计算组件基础之上构建的,其基本架构如下图: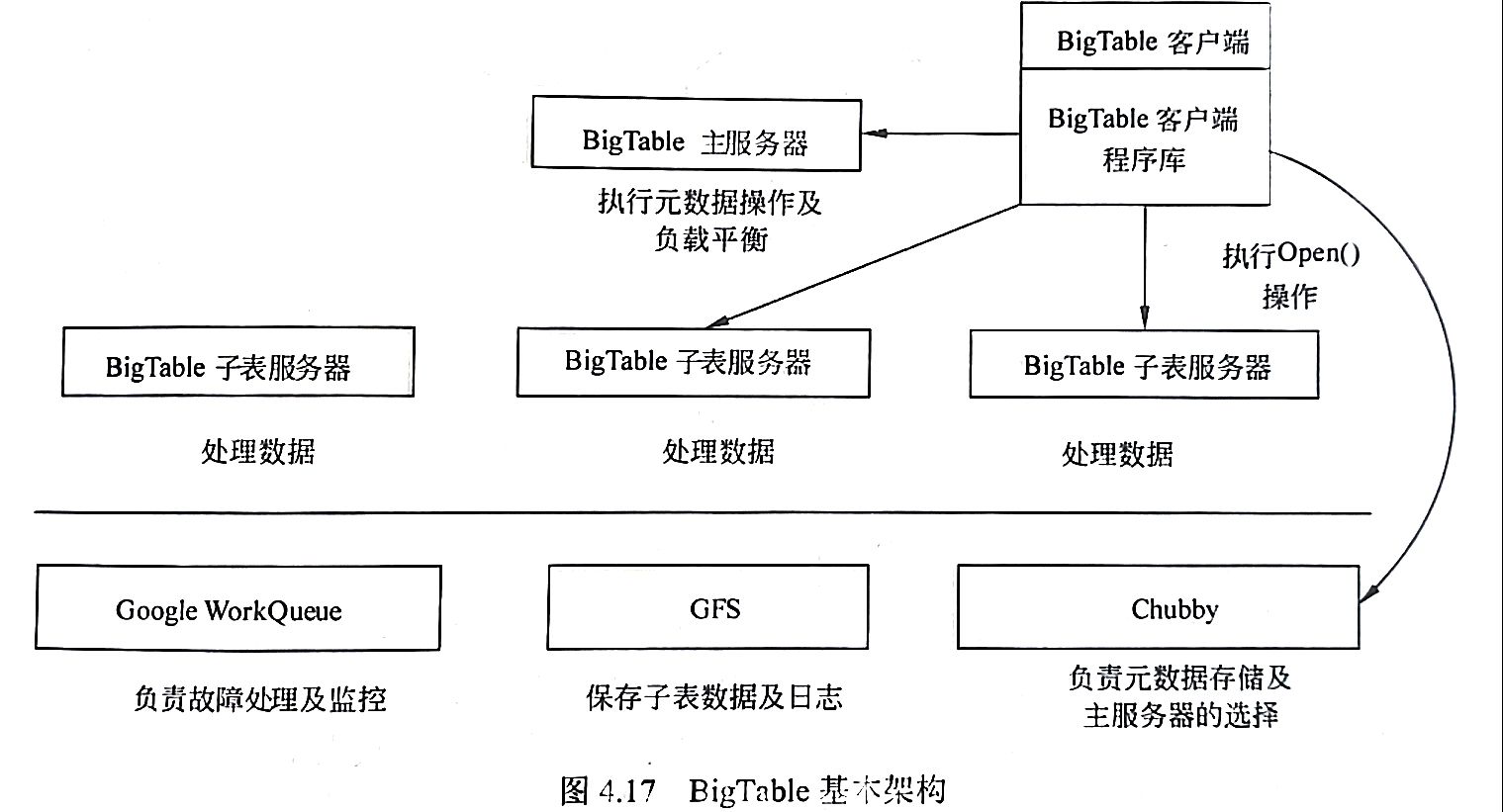
图中 WorkQueue是一个分布式的任务调度器,它主要被用来处理分布式系统队列分组和任务调度,关于其实现 Google并没有公开。在前面已经讲过,GFS是Google的分布式文件系统,在BigTable中 GFS主要用来存储子表数据及一些日志文件。BigTable还需要一个锁服务的支持,BigTable选用了Google自己开发的分布式锁服务Chubby。在 BigTable中Chubby主要有以下几个作用:
(1)选取并保证同一时间内只有一个主服务器(Master Server)。
(2)获取子表的位置信息。
(3)保存BigTable的模式信息及访问控制列表。
另外在 BigTable的实际执行过程中, Google的 MapReduce和 Sawzall 也被使用来改善其性能,不过需要注意的是这两个组件并不是实现BigTable所必需的。
BigTable主要由三个部分组成:客户端程序库(Client Library)、一个主服务器(MasterServer)和多个子表服务器(Tablet Server),这三个部分在图4.17中都有相应的表示。从图4.17中可以看出,客户需要访问BigTable服务时首先要利用其库函数执行Open()操作来打开一个锁(实际上就是获取了文件目录),锁打开以后客户端就可以和子表服务器进行通信了。和许多具有单个主节点的分布式系统一样,客户端主要与子表服务器通信,几乎不和主服务器进行通信,这使得主服务器的负载大大降低。主服务主要进行一些元数据的操作及子表服务器之间的负载调度问题,实际的数据是存储在子表服务器上的。客户程序库的概念比较简单。

若有收获,就点个赞吧
0 人点赞
