通常情况下,数据服务器的访问量是很大的,而且不同的应用程序访问该数据集不同的部分。在这种情况下,我们可以通过将数据的不同部分分配到不同的服务器上来提高水平拓展性,这种技术就是分片。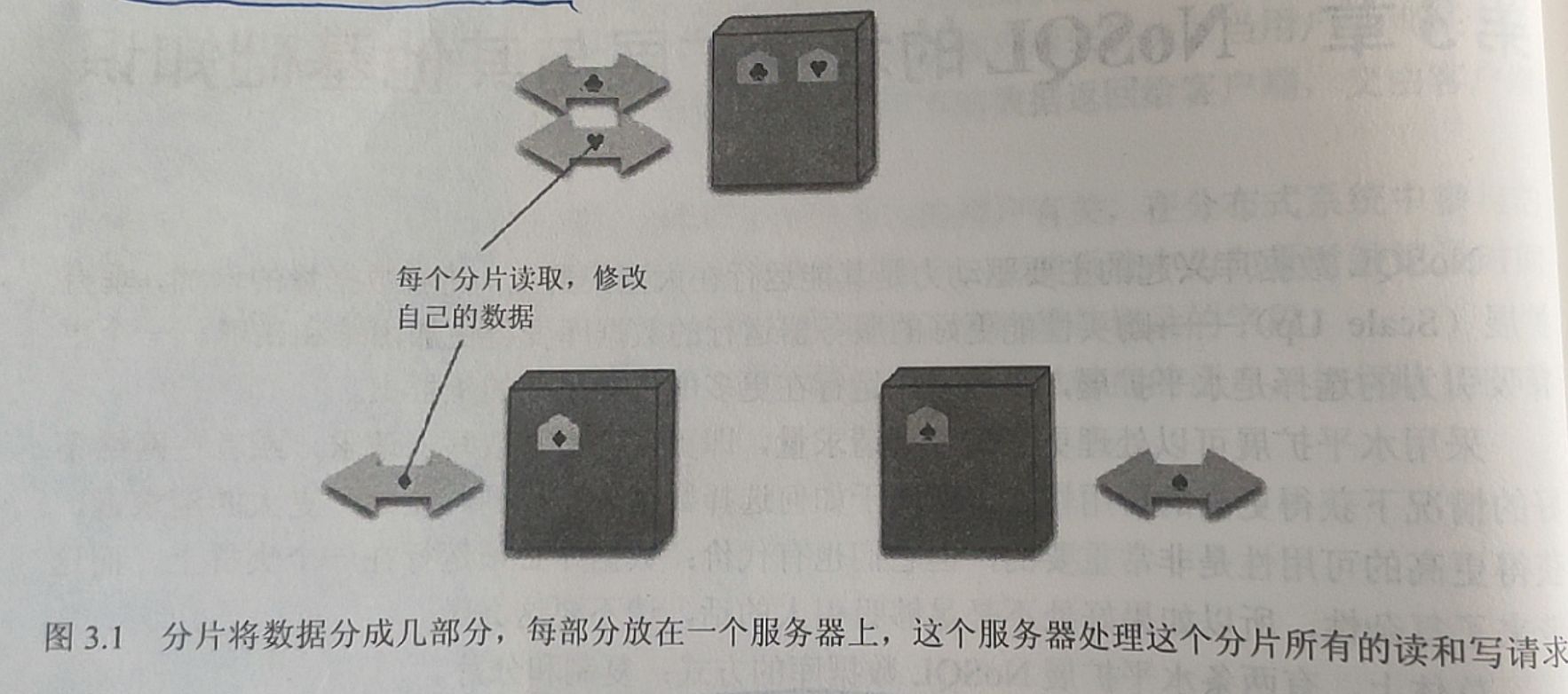
在理想情况下,不同的用户在访问不同的服务器节点。每个用户只需要去跟一台服务器打交道,所以请求能够得到快速的响应。服务器之间的负载得到很好的平衡——如果我们有10台服务器,每一个只需要处理负载的10%。
当然,理想的情况是非常罕见的。为了接近理想情况,我们必须保证一起访问的互相关联的数据分布在同一节点以提供最佳的数据访问。
这个问题的第一部分是如何聚集数据,这样一个用户在大多数情况下能从一台服务器得到他需要的全部数据,我们应该将通常一起访问的数据存放在一起。当涉及到布置在节点上的数据,有几种因素可以帮助提高性能。如果你知道某些数据的最大访问量来源于一个物理位置,你可以把数据存放在接近访问者的地方。比如如果你有一个上海人的订单,则这部分数据可以放置在华东地区的数据中心。
另一个因素是试图保持负载平衡。这意味着,你应该尝试安排数据以便使它们均匀的分布,这样每个节点都承担基本等量的负载。数据的访问可能会随时间变化,例如,如果一些数据往往在周末访问最多,那么业务相关的一些规则可能需要考虑。在某些情况下,把一起访问的数据放在一起是有效的。 Bigtable中的行按字典顺序排序,一般情况下行是网址域名的反向(例如,com.qq.www)。通过这种方式,腾讯的网页数据可以被同时访问,这将提高整体效率。
分片对提高性能特别有用,因为它可以同时改善读写性能。使用复制,特别是使用缓存,可以大大提高读取性能,但对于有大量写入的应用程序效果不好。分片提供了一种应对写入的横向扩展方法。
分片的系统也有更好的可管理性。对于系统的升级和配置可以按照分片一个一个来做,并不会对服务器产生大的影响。
但是分片单独使用效果并不好。虽然数据分布在不同的节点上,但是一个节点的故障使该分片的数据不可用,就像只有单个服务器一样。唯一的好处是只有该分片的数据受到了影响,其他的数据仍然可用。但是让一个数据库丢失其数据的一部分显然是一个非常糟糕的主意。如果只有一台服务器,我们可以管理它,保持该服务器稳定运行的工作量和成本并不高。但是如果使用一个较大的集群,那么通常我们会使用市场上一般的服务器,而这些服务器不太可靠,你将很可能遇到节点故障。因此,在实践中,单独分片可能会降低系统的可用性。
尽管分片在如今的 NoSQL 时代变得更加容易,它仍然是不能掉以轻心的一个步骤。有些数据库需要从一开始就使用分片,在这种情况下,明智的做法是在生产环境中,刚开始就运行在一个集群上。有些数据库可以从一个单一的服务器开始,在这种情况下,开始时只使用单服务器,在你的负载确定太高时才使用分片。在任何情况下,从一个单一的节点转变成一个集群都是非常困难的。我们听说很多故事,因为他们使用分片过晚,所以当他们在生产环境中使用分片时,他们的数据库完全不可用了,因为将分片数据移动到新的服务器上消耗了所有的数据库资源。这里的教训是你应使用分片早一些,以便系统一边完成这种转变,一边仍能提供服务。

若有收获,就点个赞吧
0 人点赞
