区间划分是现在很热门的NoSQL数据库MongoDB的sharding方案中所使用的算法。
系统会首先把所有的数据划分为多个区间,然后再将这些区间分配到系统的各个节点上面。最简单的区间划分是一个节点只持有一个区间:在有n个节点的情况下,将划分键的取值区间均匀划分(这里的均匀是指划分后的每个 partition的数据量尽量一样大,而并非值域区间一样大)为n份,然后每个节点持有一块,如图,例如将用户首字母进行划分,可能有以下的划分方案:
如果发生数据分布不均匀的情况,可以通过调整区间分布达到均匀情况,数据迁移会很小: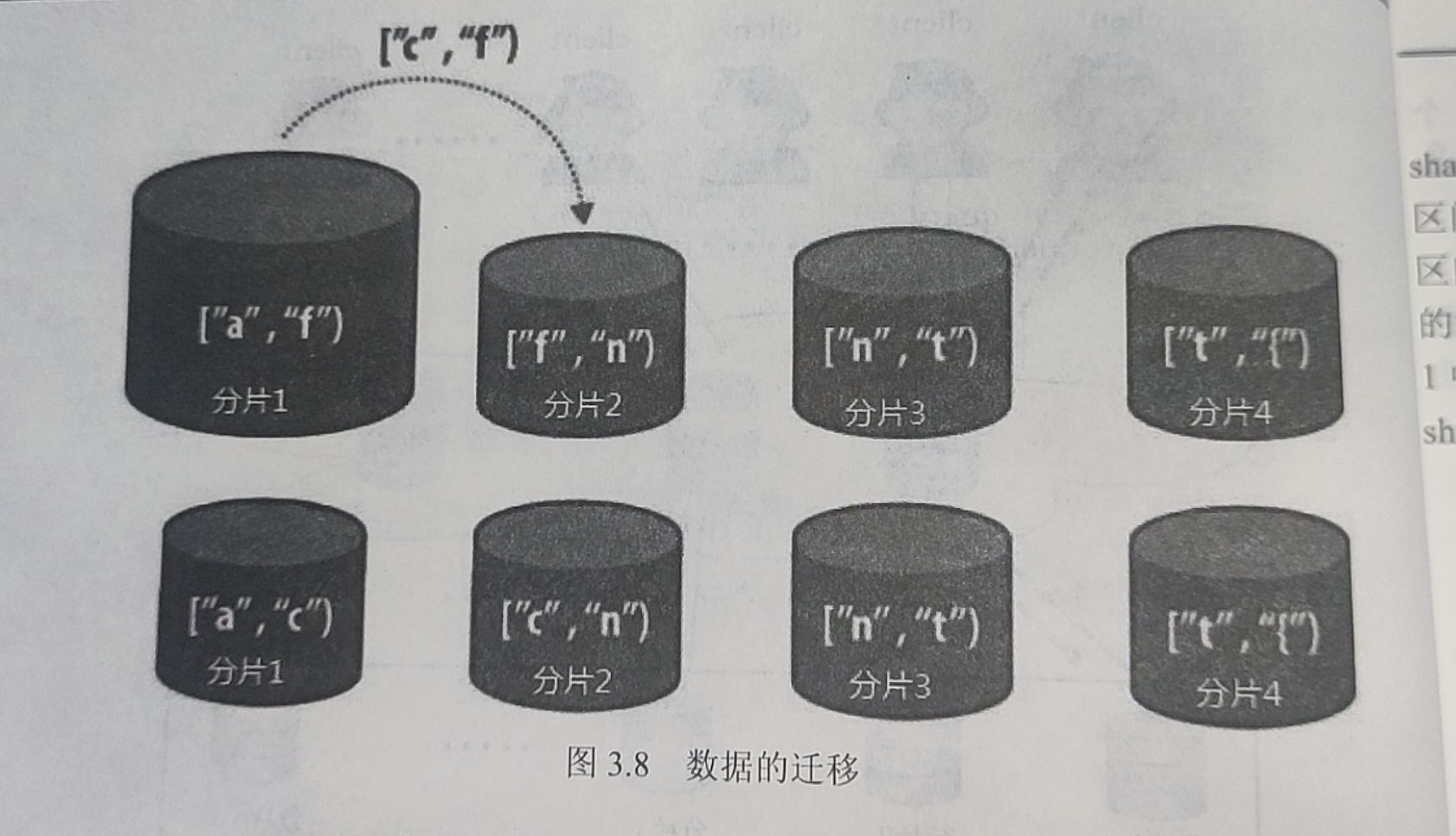
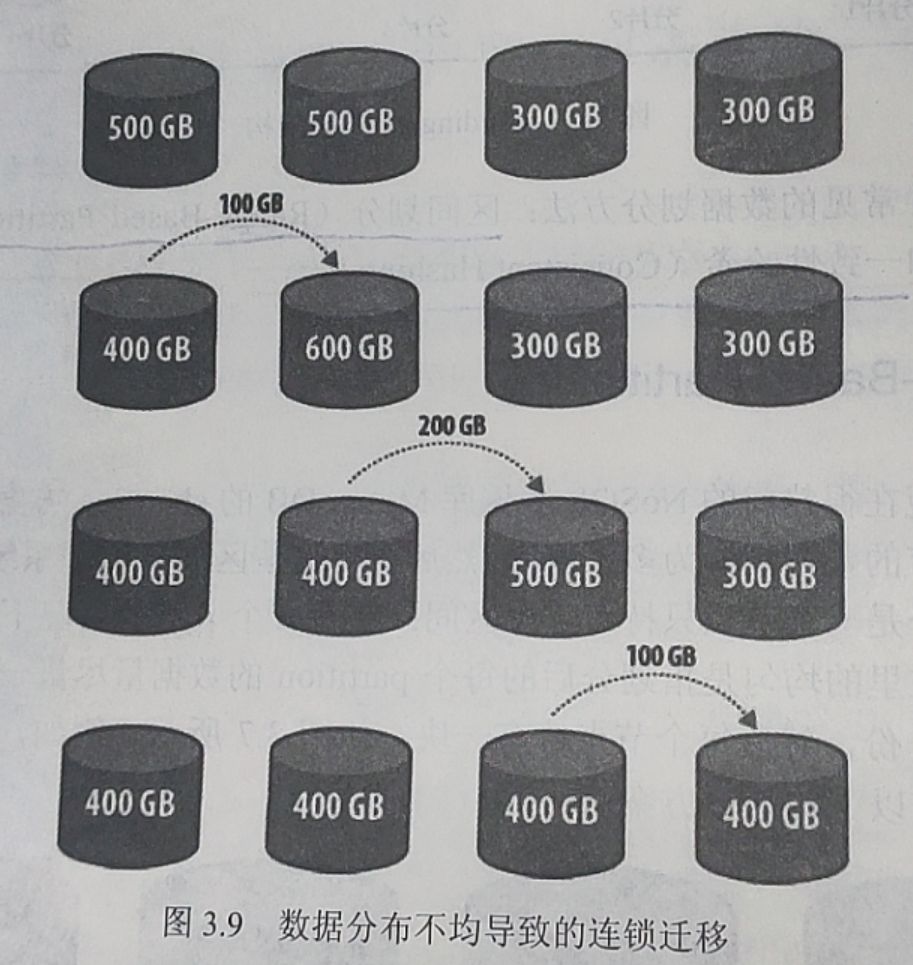
另外一些情况可能导致连锁迁移
- 情况一:数据分布不均匀,调整导致的连锁迁移
- 情况二:增加或删除节点导致的连锁迁移
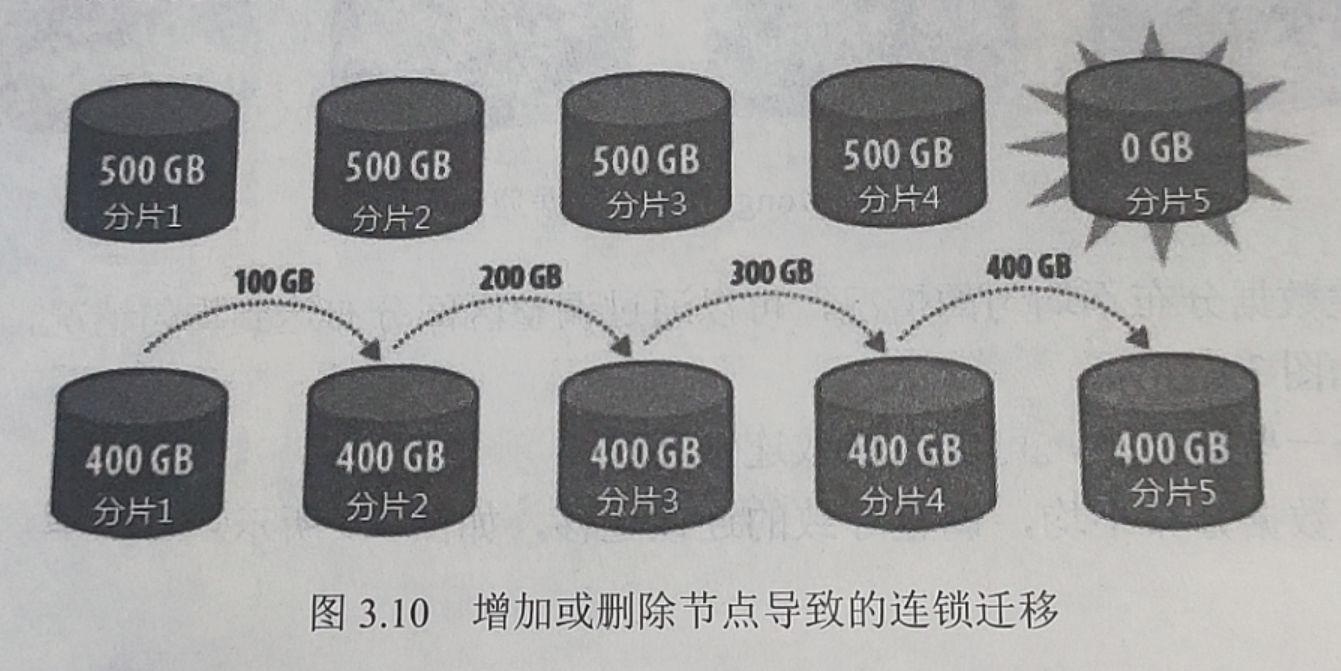
为了解决这个问题,MongoDB采用的是每个节点持有多个区间的方案(Multiple rangeshards)。当需要进行迁移的时候,将持有过多数据的节点上的区间分裂,使得分裂出来的区间刚好满足迁移需要,然后再进行迁移。举例来说(图3.11),如果shard 1中存有【a,f】区间的数据,数据量为500G,此时需要从shard 1上面迁移100G 到shard 4,以保证数据的均匀分布。经统计, shard 1 中的【a, d】段的数据为400G, 【d, f】段数据为100G,因此将shard1中的【d, f】段的数据直接迁移到shard 4上面。同理,需要从shard 2中迁移100G的数据到shard 3中。这种迁移方式的数据迁移量是理论上的最小值。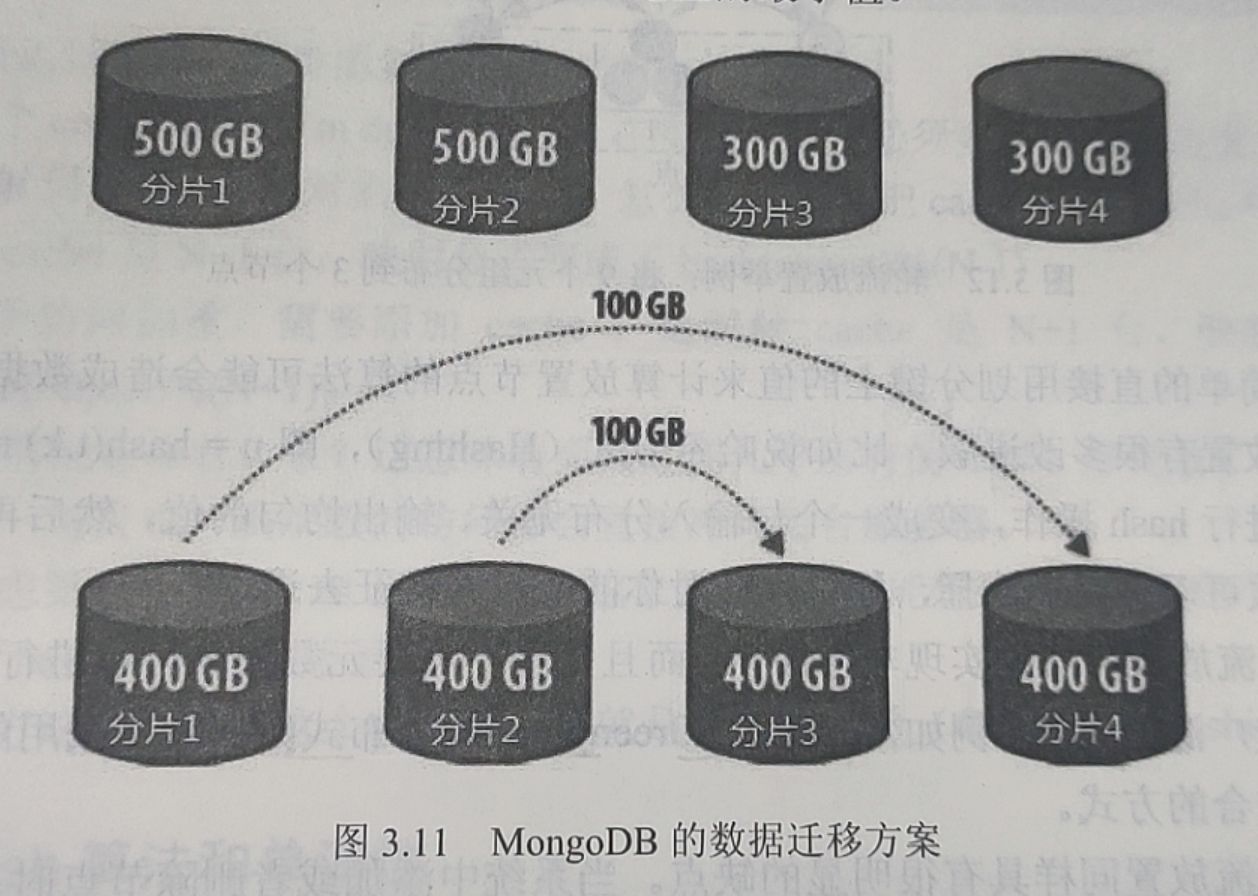
每个节点多个区间做法的缺点是使得对元数据的处理变得复杂,我们需要记录每个节点上面存储的所有区间。但是一般来说,每个节点上面的区间数目不是很大,因此元数据的数目不会很大。这种同时保证了数据的最小迁移,并且实现也比较简单的方案是一个很理想的做法,虽然它的无数据管理和同步上面会有一些问题。
另外,区间划分非常适合处理有区间查询的查询语句,但是也带来很大的一个trade-off。如果一个查询需要访问到多条元组,那么对区间的边界的选取就变得非常棘手,如果选择不当的话,很容易造成一个查询需要在多个节点上面进行运行的情况,这种跨节点的操作会对系统的性能造成很大的影响。
当然了,对于分区划分来说,对于很多应用还是非常适合的,但是对于某些应用就非常不适合。同样下面介绍的轮流放置和一致性哈希算法也是如此,在实际应用中,我们需要具体分析来选择合适的方法。

若有收获,就点个赞吧
0 人点赞
