APM 通常认为是 Application Performance Management 的简写,即监控系统。
它主要有三个方面的内容,分别是 Logs(日志)、Traces(链路追踪) 和 Metrics(报表统计)。
1、首先 Logs 最好理解,就是对各个应用中打印的 log 进行收集和提供查询能力。
Logs 系统的重要性不言而喻,通常我们在排查特定的请求的时候,是非常依赖于上下文的日志的。
以前我们都是通过 terminal 登录到机器里面去查 log(我好几年都是这样过来的),但是由于集群化和微服务化的原因,继续使用这种方式工作效率会比较低,因为你可能需要登录好几台机器搜索日志才能找到需要的信息,所以需要有一个地方中心化存储日志,并且提供日志查询。
Logs 的典型实现是 ELK (ElasticSearch、Logstash、Kibana),三个项目都是由 Elastic 开源,其中最核心的就是 ES 的储存和查询的性能得到了大家的认可,经受了非常多公司的业务考验。
Logstash 负责收集日志,然后解析并存储到 ES。通常有两种比较主流的日志采集方式,一种是通过一个客户端程序 FileBeat,收集每个应用打印到本地磁盘的日志,发送给 Logstash;另一种则是每个应用不需要将日志存储到磁盘,而是直接发送到 Kafka 集群中,由 Logstash 来消费。
Kibana 是一个非常好用的工具,用于对 ES 的数据进行可视化,简单来说,它就是 ES 的客户端。
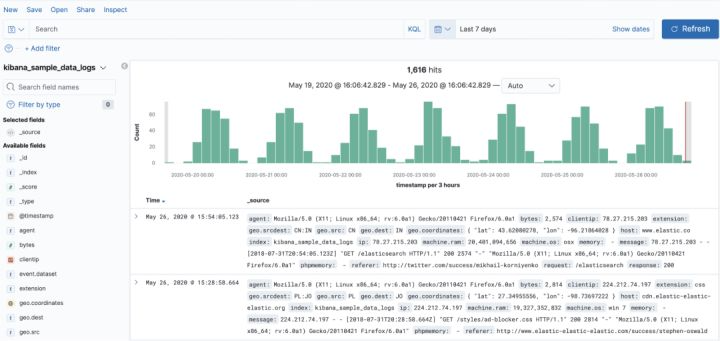
我们回过头来分析 Logs 系统,Logs 系统的数据来自于应用中打印的日志,它的特点是数据量可能很大,取决于应用开发者怎么打日志,Logs 系统需要存储全量数据,通常都要支持至少 1 周的储存。
每条日志包含 ip、thread、class、timestamp、traceId、message 等信息,它涉及到的技术点非常容易理解,就是日志的存储和查询。
使用也非常简单,排查问题时,通常先通过关键字搜到一条日志,然后通过它的 traceId 来搜索整个链路的日志。
题外话,Elastic 其实除了 Logs 以外,也提供了 Metrics 和 Traces 的解决方案,不过目前国内用户主要是使用它的 Logs 功能。
2、我们再来看看 Traces 系统,它用于记录整个调用链路。
前面介绍的 Logs 系统使用的是开发者打印的日志,所以它是最贴近业务的。而 Traces 系统就离业务更远一些了,它关注的是一个请求进来以后,经过了哪些应用、哪些方法,分别在各个节点耗费了多少时间,在哪个地方抛出的异常等,用来快速定位问题。
经过多年的发展,Traces 系统虽然在服务端的设计很多样,但是客户端的设计慢慢地趋于统一,所以有了 OpenTracing 项目,我们可以简单理解为它是一个规范,它定义了一套 API,把客户端的模型固化下来。
当前比较主流的 Traces 系统中,Jaeger、SkyWalking 是使用这个规范的,而 Zipkin、Pinpoint 没有使用该规范。限于篇幅,本文不对 OpenTracing 展开介绍。
下面这张图是我画的一个请求的时序图: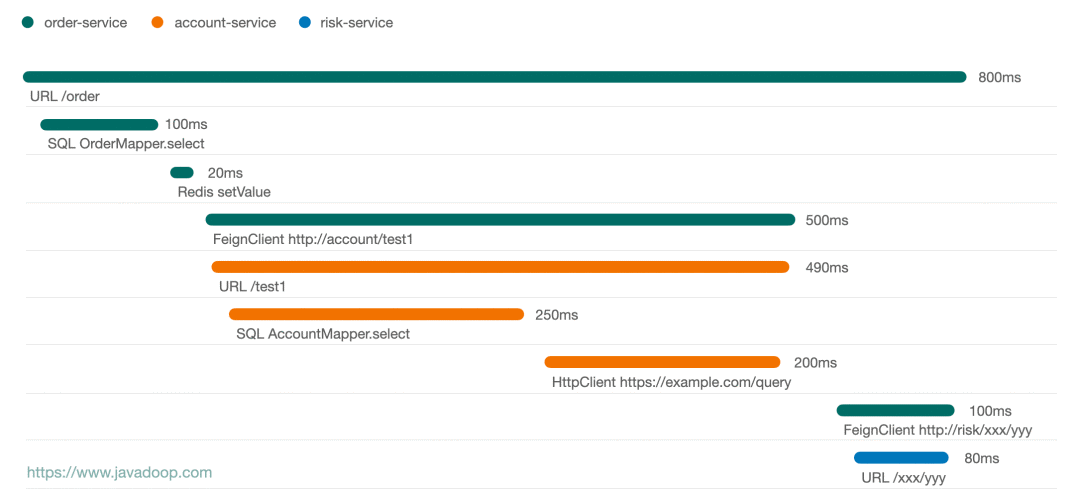
从上面这个图中,可以非常方便地看出,这个请求经过了 3 个应用,通过线的长短可以非常容易看出各个节点的耗时情况。通常点击某个节点,我们可以有更多的信息展示,比如点击 HttpClient 节点我们可能有 request 和 response 的数据。
下面这张图是 Skywalking 的图,它的 UI 也是蛮好的:
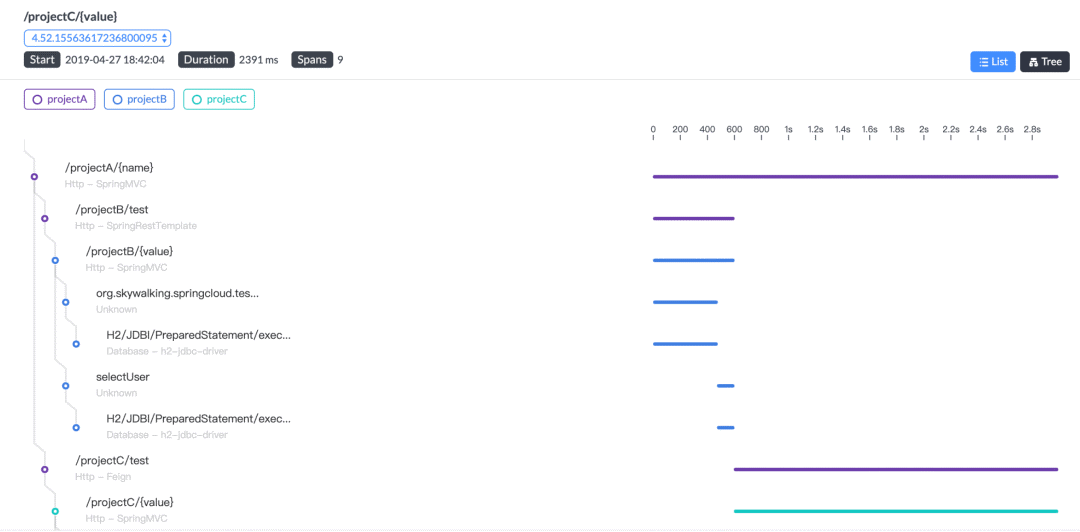
SkyWalking 在国内应该比较多公司使用,是一个比较优秀的由国人发起的开源项目,已进入 Apache 基金会。
另一个比较好的开源 Traces 系统是由韩国人开源的 Pinpoint,它的打点数据非常丰富,这里有官方提供的 Live Demo,大家可以去玩一玩。
最近比较火的是由 CNCF(Cloud Native Computing Foundation) 基金会管理的 Jeager: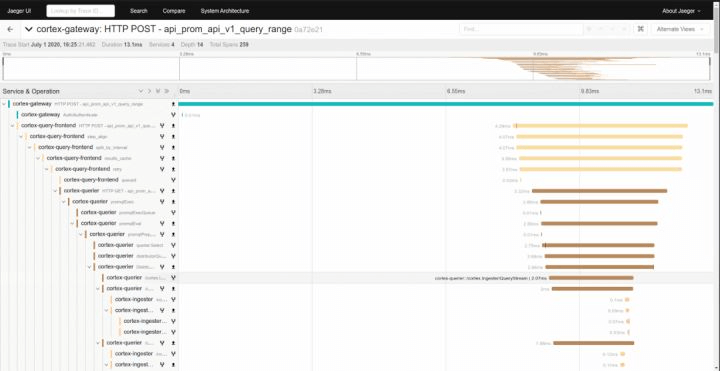
当然也有很多人使用的是 Zipkin,算是 Traces 系统中开源项目的老前辈了: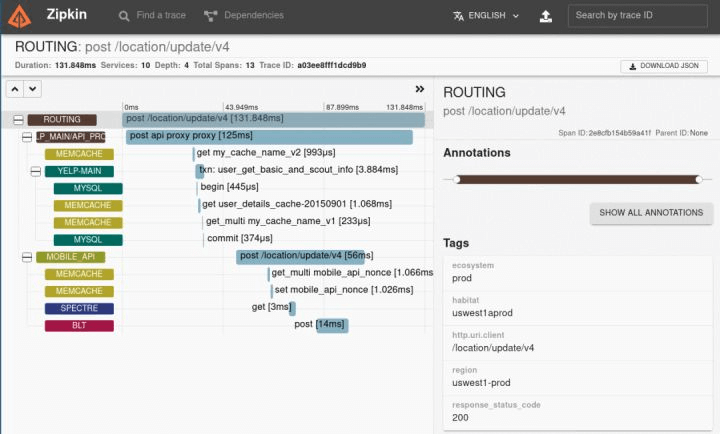
上面介绍的是目前比较主流的 Traces 系统,在排查具体问题的时候它们非常有用,通过链路分析,很容易就可以看出来这个请求经过了哪些节点、在每个节点的耗时、是否在某个节点执行异常等。
虽然这里介绍的几个 Traces 系统的 UI 不一样,大家可能有所偏好,但是具体说起来,表达的都是一个东西,那就是一颗调用树,所以我们要来说说每个项目除了 UI 以外不一样的地方。
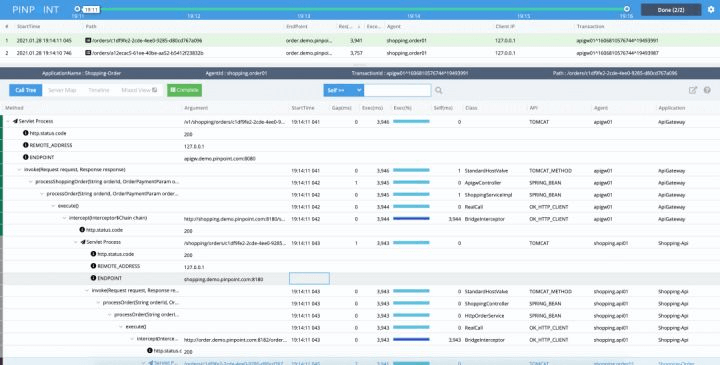
首先肯定是数据的丰富度,你往上拉看 Pinpoint 的树,你会发现它的埋点非常丰富,真的实现了一个请求经过哪些方法一目了然。
但是这真的是一个好事吗?值得大家去思考一下。两个方面,一个是对客户端的性能影响,另一个是服务端的压力。
其次,Traces 系统因为有系统间调用的数据,所以很多 Traces 系统会使用这个数据做系统间的调用统计,比如下面这个图其实也蛮有用的:
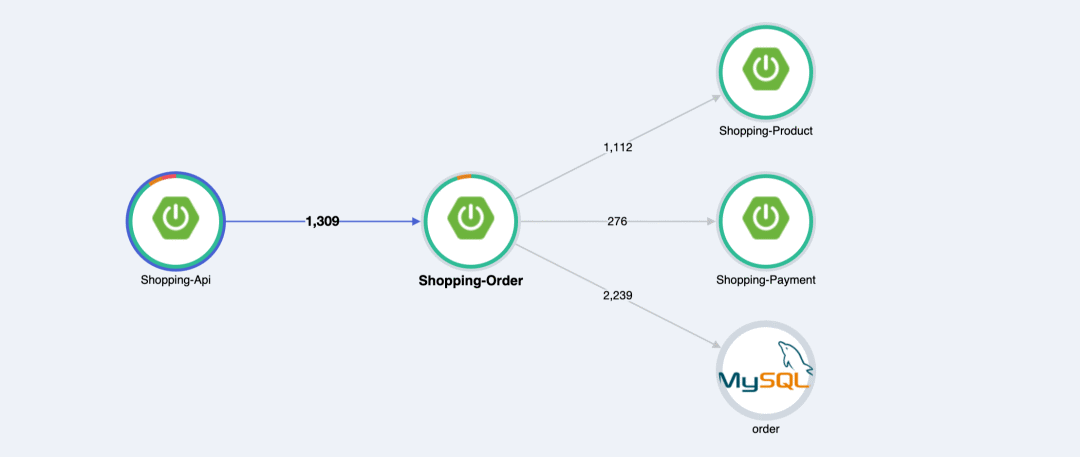
另外,前面说的是某个请求的完整链路分析,那么就引出另一个问题,我们怎么获取这个“某个请求”,这也是每个 Traces 系统的不同之处。
比如上图,它是 Pinpoint 的图,我们看到前面两个节点的圆圈是不完美的,点击前面这个圆圈,就可以看出来原因了:
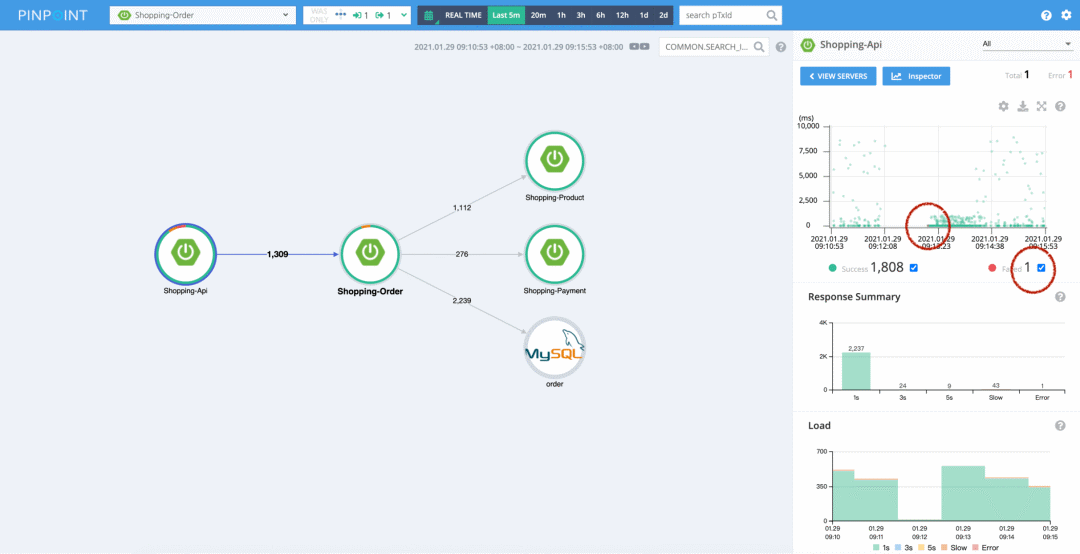
图中右边的两个红圈是我加的。我们可以看到在 Shopping-api 调用 Shopping-order 的请求中,有 1 个失败的请求,我们用鼠标在散点图中把这个红点框出来,就可以进入到 trace 视图,查看具体的调用链路了。限于篇幅,我这里就不去演示其他 Traces 系统的入口了。
还是看上面这个图,我们看右下角的两个统计图,我们可以看出来在最近 5 分钟内 Shopping-api 调用 Shopping-order 的所有请求的耗时情况,以及时间分布。在发生异常的情况,比如流量突发,这些图的作用就出来了。
对于 Traces 系统来说,最有用的就是这些东西了,当然大家在使用过程中,可能也发现了 Traces 系统有很多的统计功能或者机器健康情况的监控,这些是每个 Traces 系统的差异化功能,我们就不去具体分析了。

若有收获,就点个赞吧
0 人点赞
