Distilling the Knowledge in a Neural Network
这篇介绍一下Hinton大神在15年做的一个黑科技技术,Hinton在一些报告中称之为Dark Knowledge,技术上一般叫做知识蒸馏(Knowledge Distillation)。核心思想是通过迁移知识,从而通过训练好的大模型得到更加适合推理的小模型。这个概念最早在06年的Paper: Model Compression中, Caruana提出一种将大模型学习到的函数压缩进更小更快的模型,而获得可以匹敌大模型结果的方法。
重点idea就是提出用soft target来辅助hard target一起训练,而soft target来自于大模型的预测输出。这里有人会问,明明true label(hard target)是完全正确的,为什么还要soft target呢?
hard target 包含的信息量(信息熵)很低,soft target包含的信息量大,拥有不同类之间关系的信息(比如同时分类驴和马的时候,尽管某张图片是马,但是soft target就不会像hard target 那样只有马的index处的值为1,其余为0,而是在驴的部分也会有概率。)[5]
这样的好处是,这个图像可能更像驴,而不会去像汽车或者狗之类的,而这样的soft信息存在于概率中,以及label之间的高低相似性都存在于soft target中。但是如果soft targe是像这样的信息[0.98 0.01 0.01],就意义不大了,所以需要在softmax中增加温度参数T(这个设置在最终训练完之后的推理中是不需要的)
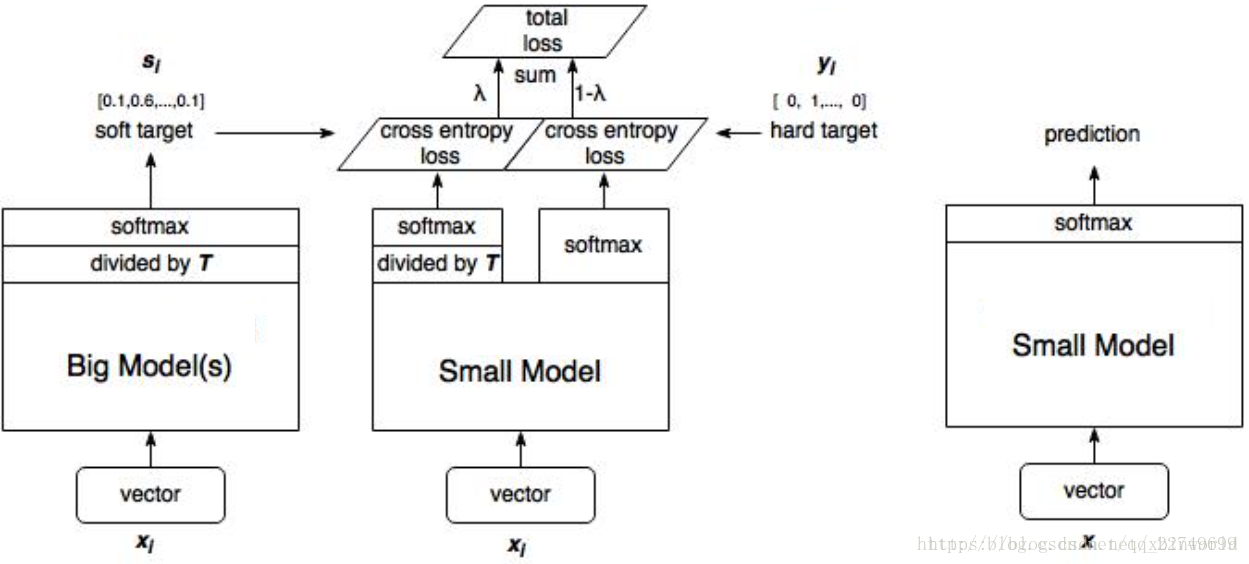
1、训练大模型:先用hard target,也就是正常的label训练大模型。
2、计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
3、训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
4、预测时,将训练好的小模型按常规方式(右图)使用。
在线蒸馏 codistillation
在分布式训练任务下,提出了一种替代标准SGD训练NN模型的方法codistillation,是一种非同步的算法,事实上有很多个Wieght的副本在独立训练,他可以有效“解决”机器增加但线性度不增加的问题,实验中还有一些数据表面可以比标准的SGD收敛更快。
也是distill的思想,但是因为是重头训练,所以什么是teacher model呢?作者提出用所有模型的预测平均作为teacher model,然后作为soft target来训练每一个模型。
在这篇论文中,使用codistillation来指代执行的distillation:
- 所有模型使用相同的架构;
- 使用相同的数据集来训练所有模型;
- 任何模型完全收敛之前使用训练期间的distillation loss。

若有收获,就点个赞吧
0 人点赞
