基于前面的决策树的思路
之前的决策树主要是为了进行分类,也就是根据信息熵的变化规律选择特征和特征值作为分类的依据对数据进行分类
这里的思路就是利用树进行回归
分类的目标就是所有的数据最后可以归结到叶子节点里(也就是每一种的类别)
特别就是针对不同的离散型的特征,对每一个特征的每一种数据建立一个分叉
这里的回归就是利用一个阈值对数据进行分割,也就是可以处理连续的数据类型
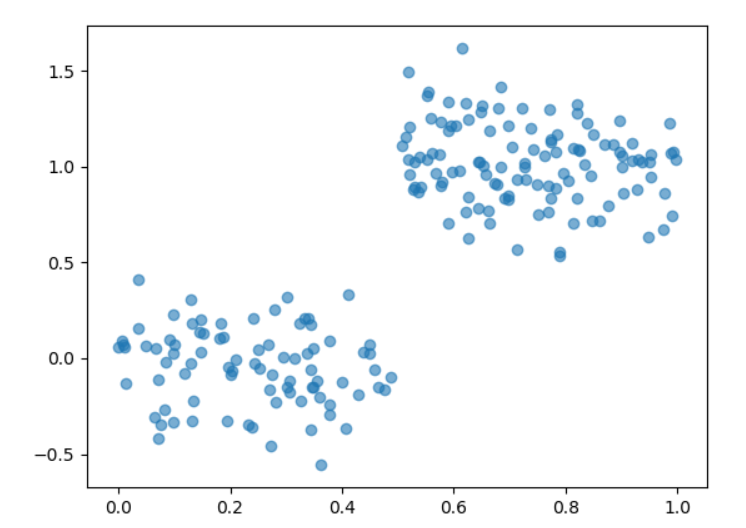
很明显的对于下面这种有明显的两类的特征的数据
树模型很成功的分出了两个分支对应两个数据块

改进
上述的模型依旧和分类非常的相似,就是对数据进行划分
如果是想要应用到回归上,就需要把划分的依据,也就是损失的计算修改
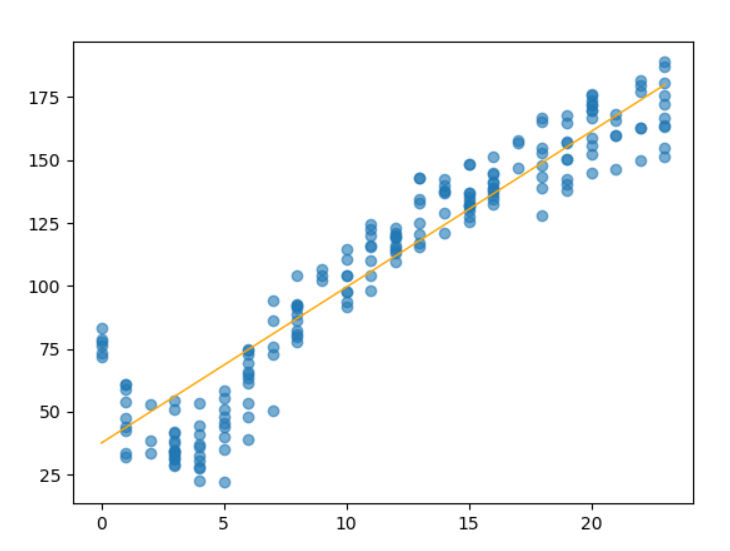
对于线性拟合有一个直接可以求出线性参数(根据求导求逆)
如果对于一些数据是多段的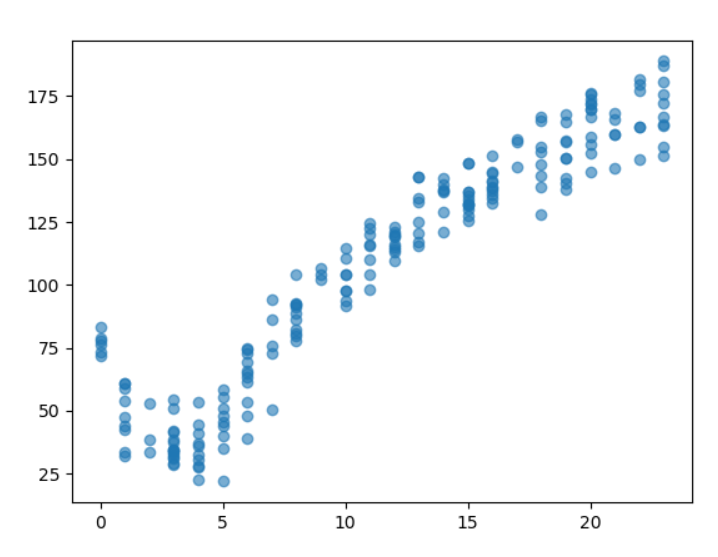
如果直接使用直线进行拟合很显然效果不好
def linearSolve(dataSet): #helper function used in two placesm,n = shape(dataSet)X = mat(ones((m,n))); Y = mat(ones((m,1)))#create a copy of data with 1 in 0th postionX[:,1:n] = dataSet[:,0:n-1]; Y = dataSet[:,-1]#and strip out YxTx = X.T*Xif linalg.det(xTx) == 0.0:raise NameError('This matrix is singular, cannot do inverse,\n\try increasing the second value of ops')ws = xTx.I * (X.T * Y)return ws,X,Y
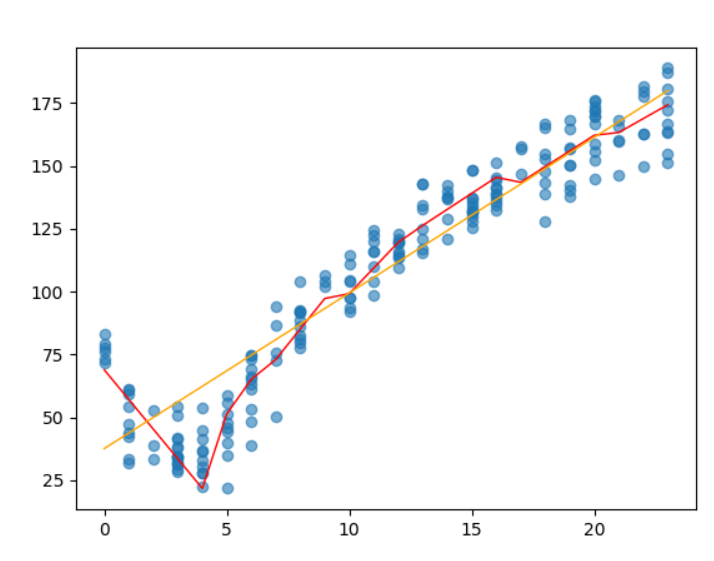
考虑到使用树可以对数据探究得到合理的划分,也就是在每一个维度的特征上对所有的特征值进行尝试划分,查看划分前后是否有损失的减小,如果有就进行一次划分
可以看到红色的线就是对数据进行了分段的拟合
树在这里的作用就是对数据进行尝试划分,对每一个子段利用回归公式拟合,然后看误差是否缩小
剪枝
如果对每一个数据都进行切分和建立叶子节点,则可能会出现过拟合的现象(过于依赖训练集导致整个树过于庞大)则可以考虑对一棵树进行剪枝的操作
预剪枝
在建立树的时候设置阈值,对于划分之后优化效果不明显的树和叶子直接就不建立
后剪枝
建立了树之后利用数据进行修剪
简单的想法就是做DFS,如果有两端的叶子或者是树可以进行合并会导致损失减小则合并(这个数据不一定是训练数据,可能是测试数据)

若有收获,就点个赞吧
0 人点赞
