优化方法,之前的学习网络都是直接调用一个函数optimizer进行优化,原书的这一章节对这里进行了详细的分析
优化方法的原理
比如说一个函数,想要求出最小值,就要保证这个自变量的运动方向是朝着正确的方向进行的
https://zhuanlan.zhihu.com/p/36564434

梯度下降
梯度下降就是计算出一个batch里的所有数据的梯度,然后求解出平均值再进行迭代
随机梯度下降
由于梯度下降的计算量比较大,所以为了减小计算量,有了随机梯度下降。
随机梯度下降就是在一个batch里的数据的所有梯度里挑一个作为下降的量进行计算
小批量梯度下降
小批量梯度下降就是二者的中间体,就是取出一个小批量那么多的数据计算梯度然后取平均值。
如果这个小批量的大小是1,那就是随机梯度下降。如果是batch_size,那就是梯度下降
动量法

指数加权移动平均
在这里的采样加权平均的想法很新奇,也是动量法的核心
指数加权移动平均变形
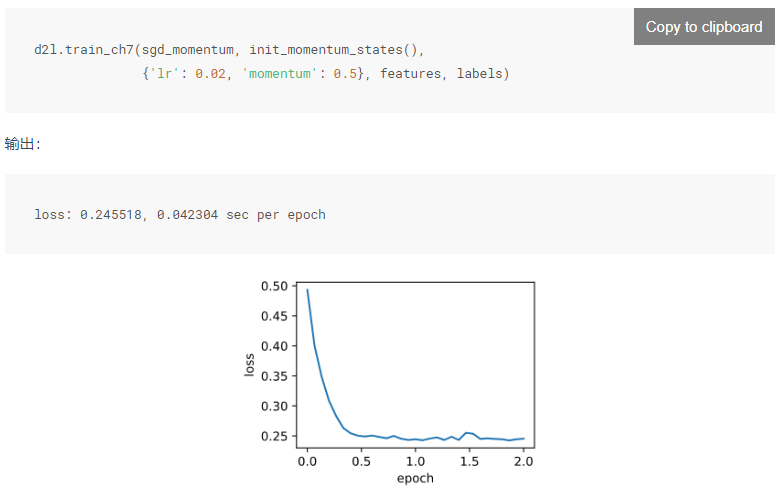
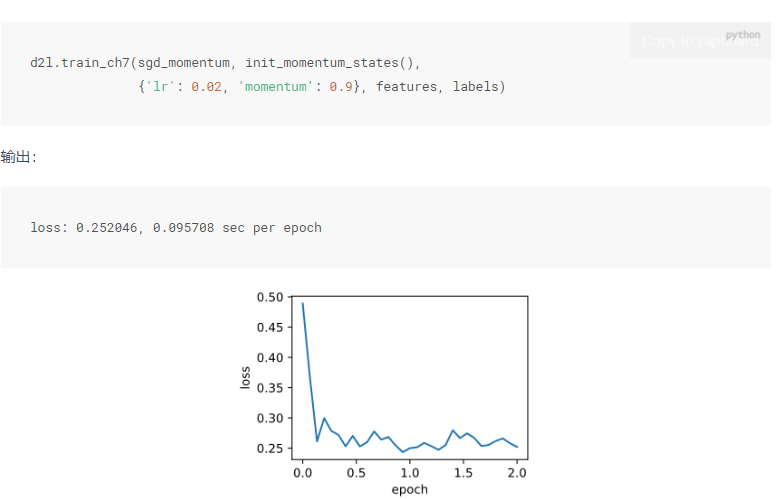
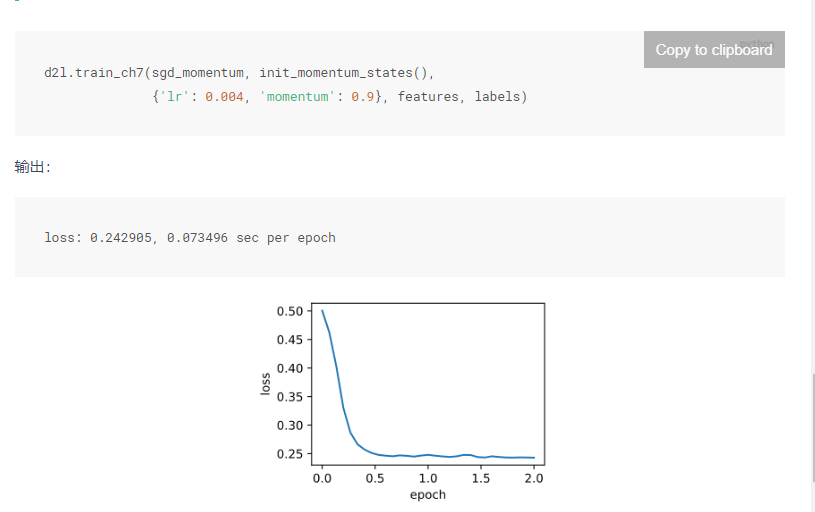
在后续的运行结果的分析里可以观察到上文黑体里的内容,在加权平均之后除于了1-y,结果就是没有平均,那么对于这个动量法的超参数y来说,y越大就意味着会采样更多的之前时间步的梯度,累加的会更大,也就是会导致震荡的更加的严重,可以适当的调低学习率
AdaGrad
由于有很多个特征变量,但是学习率只有一个,有的特征变量在计算的时候梯度小,有的梯度又很大,就会导导致学习率大的时候,变化小的特征变量收敛的号,但是变化大的疯狂震荡,反之也有同理的问题
所以AdaGrad算法就是为了解决这个问题,它针对每一个特征变量都有对应的参数以调整对应的学习率
RMSProp
先前的AdaGrad在计算的过程中s数值会不断的叠加,导致到后面所有的特征变量的学习率都下降了,如果说这个模型的优化效率不太行就会导致收敛过慢,所以这个RMSRrop结合了上两种的算法,对AdaGrad近几次的数据进行采样和加权平均

AdaDelta
除了RMSProp算法以外,另一个常用优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有用解的问题做了改进 [1]。有意思的是,AdaDelta算法没有学习率这一超参数。

Adam


若有收获,就点个赞吧
0 人点赞
