多日学习,决定试试以前不敢搞的kaggle
下载了TiTanic数据集,入门尝试
首先
数据集是csv格式,所以引入了pandas的学习,之前偶尔有看到相关的代码,却一直没有上手写
今天就试了试,主要的操作就是读取,以及对行列数据的切割和合并
相关知识的参考链接https://blog.csdn.net/chenKFKevin/article/details/62049060
还有一个就是关于可以使用shape获取数据的行列数信息,其中有一个大坑就是
df = df.iloc[0:2, [0, 2]]
这里的0:2相当于[0,2)前闭后开,2是不在范围之内的。这就导致了我的数据一直少了一行,提交一直不成功。
然后
对数据进行处理,对于性别源数据是male,female。修改为0,1等等
接着
建立神经网络,目前我比较熟悉的也就是线性层,于是就使用线性层加上ReLu
最后
写一个预测的接口,预测结果,写回test.csv
总结
下附代码和运行评定结果
- 在数据的导入处理上不熟悉
- 可以考虑把网络和激活函数等组件封装为Module,然后返回预测结果,既可以训练又可以预测,本次是散的,才单独写一个预测的接口
- 对于如何提高预测结果,考虑增加隐藏层的神经元数目,增厚线性层和Relu交杂的结构,取得了一定的进展,同时加大了epoch训练量
- 代码以及模型相关的接口不熟。代码基本是这边抄一点,那边抄一点
运行结果
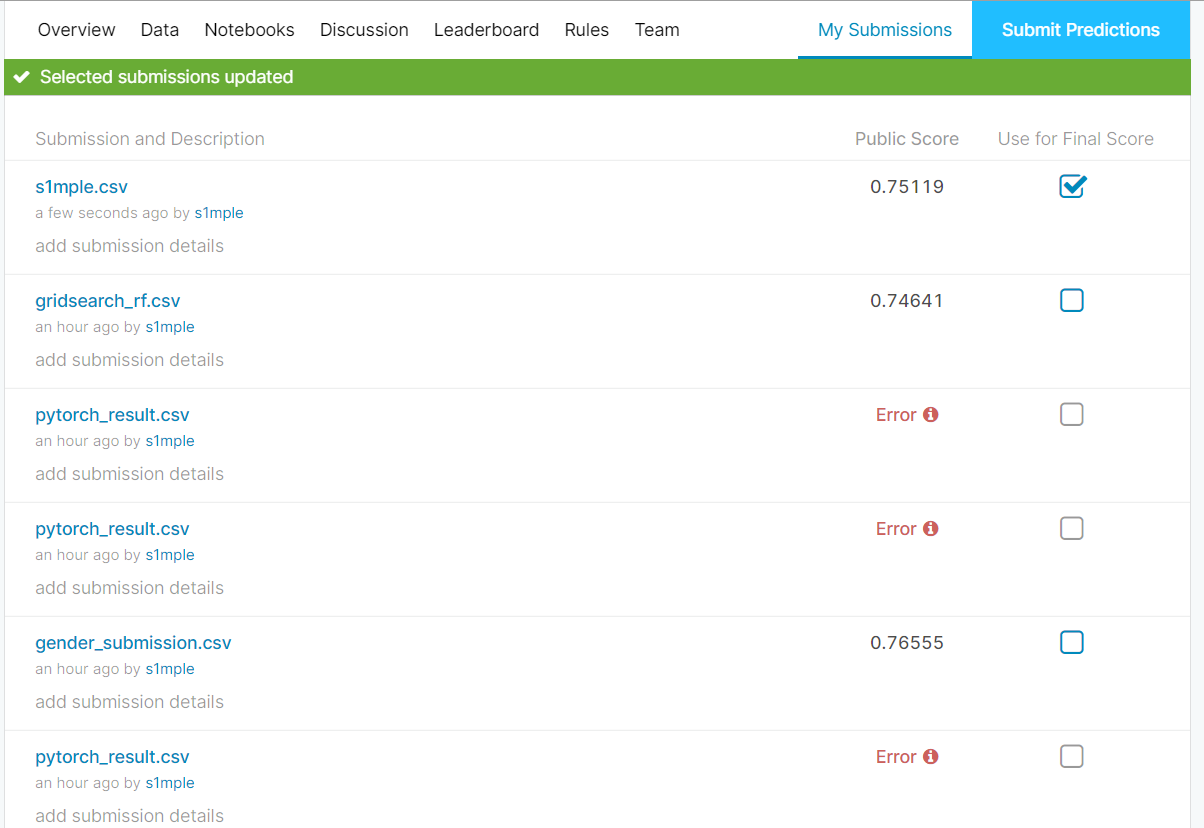
三个运行error就是由于数据少了一行,幸幸苦苦训练半天成果还没有默认的女性全部存活的分数高。。
一开始是单纯的两层线性层,一层ReLU,256的隐藏层神经元,300epoch
然后把数据和代码迁移到了Colab上,配置如下附代码:3线性层,2ReLu层,2048隐藏神经元,同时调低了batch_size到8,原来是32。在本地验证在训练集上的表现是从81%左右的正确率到了83%。
import pandas as pdimport numpy as npfrom sklearn.preprocessing import MinMaxScalerimport timeimport copyimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torch.nn.functionalfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsimport warningsimport torchUSE_CUDA = torch.cuda.is_available()base_path="/content/"read_train=pd.read_csv(base_path+'train.csv')#print(read_train.shape[0])#print(read_train.shape[1])read_traintrain_data=read_train.iloc[0:read_train.shape[0],[2,4,5]]print(len(train_data))train_data['Age'] = train_data['Age'].fillna(train_data['Age'].mean())train_data['Sex'] = [1 if x == 'male' else 0 for x in train_data.Sex]train_label=read_train.iloc[:read_train.shape[0],[1]]train_data=torch.tensor(train_data[:read_train.shape[0]].values,dtype=torch.float)train_label=torch.tensor(train_label[:read_train.shape[0]].values,dtype=torch.float)if USE_CUDA:train_data =train_data.cuda()train_label = train_label.cuda()loss = torch.nn.MSELoss()feature_num=train_data.shape[1]print(feature_num)print(feature_num)def get_net(feature_num):net = nn.Sequential(nn.Linear(feature_num, 2048),nn.ReLU(),nn.Linear(2048, 2048),nn.ReLU(),nn.Linear(2048, 1),)if USE_CUDA:net=net.cuda()#net = nn.Linear(feature_num, 1)for param in net.parameters():nn.init.normal_(param, mean=0, std=0.01)return netdef train(net, train_data, train_label,num_epochs, learning_rate, batch_size):train_ls=[]dataset = torch.utils.data.TensorDataset(train_data, train_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)# 这里使用了Adam优化算法optimizer = torch.optim.Adam(params=net.parameters(), lr=learning_rate)net = net.float()for epoch in range(num_epochs):for X, y in train_iter:l = loss(net(X.float()), y.float())optimizer.zero_grad()l.backward()optimizer.step()train_ls.append(l.item())if epoch % 10 == 0:print("epoch ",str(epoch)," : ",l.item())return train_lsnet=get_net(feature_num)num_epochs, lr, batch_size = 1000 , 0.0002, 8loss_list=train(net, train_data, train_label, num_epochs,lr, batch_size )m_loss=0for i in loss_list:m_loss+=iprint(m_loss/num_epochs)pred=0with torch.no_grad():dataset = torch.utils.data.TensorDataset(train_data, train_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=False)print(len(train_iter))for X, y in train_iter:result=net(X.float())for i in range(len(result)):if result[i] > 0.5:result[i]= 1else:result[i]=0for i in range(len(result)):if result[i]==y[i]:pred+=1print(pred/891)read_test=pd.read_csv(base_path+'test.csv')test_data=read_test.iloc[:read_test.shape[0],[1,3,4]]test_data['Age'] = test_data['Age'].fillna(test_data['Age'].mean())test_data['Sex'] = [1 if x == 'male' else 0 for x in test_data.Sex]length=test_data.shape[0]#print(length)test_data=torch.tensor(test_data[:length].values,dtype=torch.float)all_result=[]idx=0with torch.no_grad():#print(len(test_data))result_dataset = torch.utils.data.TensorDataset(test_data)result_dataloader=torch.utils.data.DataLoader(result_dataset,batch_size=32,shuffle=False)for X in result_dataloader:temp=X[0].cuda()result=net(temp.float())for i in range(len(result)):idx+=1if result[i] > 0.5:result[i]= 1all_result.append(1)else:result[i]=0all_result.append(0)#print(idx)#print(len(all_result))df_output = pd.DataFrame()aux = pd.read_csv(base_path+'test.csv')df_output['PassengerId'] = aux['PassengerId']#print(len(df_output['PassengerId']))df_output['Survived'] =all_resultdf_output[['PassengerId','Survived']].to_csv(base_path+'s1mple.csv', index=False)

若有收获,就点个赞吧
0 人点赞
