2.1 总体设计
Java 中的线程池核心实现类是 ThreadPoolExecutor,本章基于 JDK 1.8 的源码来分析 Java 线程池的核心设计与实现。我们首先来看一下 ThreadPoolExecutor 的 UML 类图,了解下 ThreadPoolExecutor 的继承关系。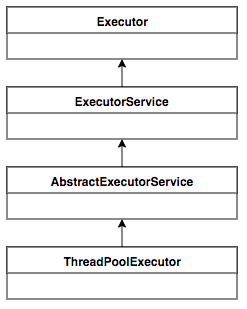
图 1 ThreadPoolExecutor UML 类图
ThreadPoolExecutor 实现的顶层接口是 Executor,顶层接口 Executor 提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供 Runnable 对象,将任务的运行逻辑提交到执行器 (Executor) 中,由 Executor 框架完成线程的调配和任务的执行部分。ExecutorService 接口增加了一些能力:(1)扩充执行任务的能力,补充可以为一个或一批异步任务生成 Future 的方法;(2)提供了管控线程池的方法,比如停止线程池的运行。AbstractExecutorService 则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。最下层的实现类 ThreadPoolExecutor 实现最复杂的运行部分,ThreadPoolExecutor 将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
ThreadPoolExecutor 是如何运行,如何同时维护线程和执行任务的呢?其运行机制如下图所示: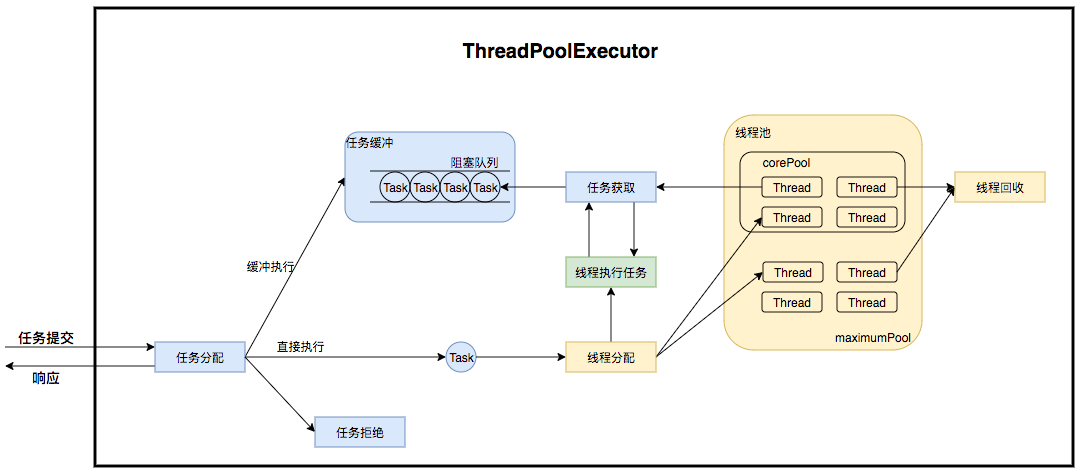
图 2 ThreadPoolExecutor 运行流程
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管理、线程管理。任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:(1)直接申请线程执行该任务;(2)缓冲到队列中等待线程执行;(3)拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
接下来,我们会按照以下三个部分去详细讲解线程池运行机制:
- 线程池如何维护自身状态。
- 线程池如何管理任务。
-
2.2 生命周期管理
线程池运行的状态,并不是用户显式设置的,而是伴随着线程池的运行,由内部来维护。线程池内部使用一个变量维护两个值:运行状态 (runState) 和线程数量 (workerCount)。在具体实现中,线程池将运行状态 (runState)、线程数量 (workerCount) 两个关键参数的维护放在了一起,如下代码所示:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
ctl 这个 AtomicInteger 类型,是对线程池的运行状态和线程池中有效线程的数量进行控制的一个字段, 它同时包含两部分的信息:线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount),高 3 位保存 runState,低 29 位保存 workerCount,两个变量之间互不干扰。用一个变量去存储两个值,可避免在做相关决策时,出现不一致的情况,不必为了维护两者的一致,而占用锁资源。通过阅读线程池源代码也可以发现,经常出现要同时判断线程池运行状态和线程数量的情况。线程池也提供了若干方法去供用户获得线程池当前的运行状态、线程个数。这里都使用的是位运算的方式,相比于基本运算,速度也会快很多。
关于内部封装的获取生命周期状态、获取线程池线程数量的计算方法如以下代码所示:private static int runStateOf(int c) { return c & ~CAPACITY; } //计算当前运行状态private static int workerCountOf(int c) { return c & CAPACITY; } //计算当前线程数量private static int ctlOf(int rs, int wc) { return rs | wc; } //通过状态和线程数生成ctl
ThreadPoolExecutor 的运行状态有 5 种,分别为:

其生命周期转换如下入所示: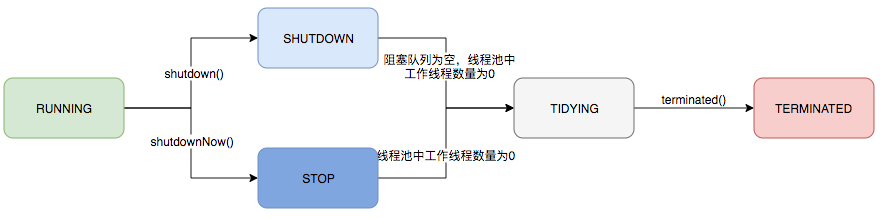
图 3 线程池生命周期2.3 任务执行机制
2.3.1 任务调度
任务调度是线程池的主要入口,当用户提交了一个任务,接下来这个任务将如何执行都是由这个阶段决定的。了解这部分就相当于了解了线程池的核心运行机制。
首先,所有任务的调度都是由 execute 方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。其执行过程如下: 首先检测线程池运行状态,如果不是 RUNNING,则直接拒绝,线程池要保证在 RUNNING 的状态下执行任务。
- 如果 workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
- 如果 workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果 workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果 workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满,则根据拒绝策略来处理该任务,默认的处理方式是直接抛异常。
其执行流程如下图所示: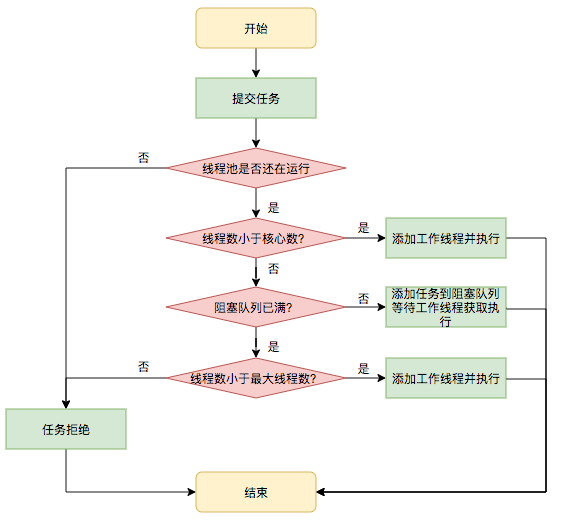
图 4 任务调度流程
2.3.2 任务缓冲
任务缓冲模块是线程池能够管理任务的核心部分。线程池的本质是对任务和线程的管理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才可以做后续的分配工作。线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
阻塞队列 (BlockingQueue) 是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
下图中展示了线程 1 往阻塞队列中添加元素,而线程 2 从阻塞队列中移除元素: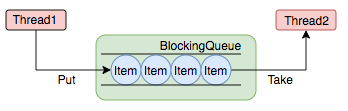
图 5 阻塞队列
使用不同的队列可以实现不一样的任务存取策略。在这里,我们可以再介绍下阻塞队列的成员:
2.3.3 任务申请
由上文的任务分配部分可知,任务的执行有两种可能:一种是任务直接由新创建的线程执行。另一种是线程从任务队列中获取任务然后执行,执行完任务的空闲线程会再次去从队列中申请任务再去执行。第一种情况仅出现在线程初始创建的时候,第二种是线程获取任务绝大多数的情况。
线程需要从任务缓存模块中不断地取任务执行,帮助线程从阻塞队列中获取任务,实现线程管理模块和任务管理模块之间的通信。这部分策略由 getTask 方法实现,其执行流程如下图所示: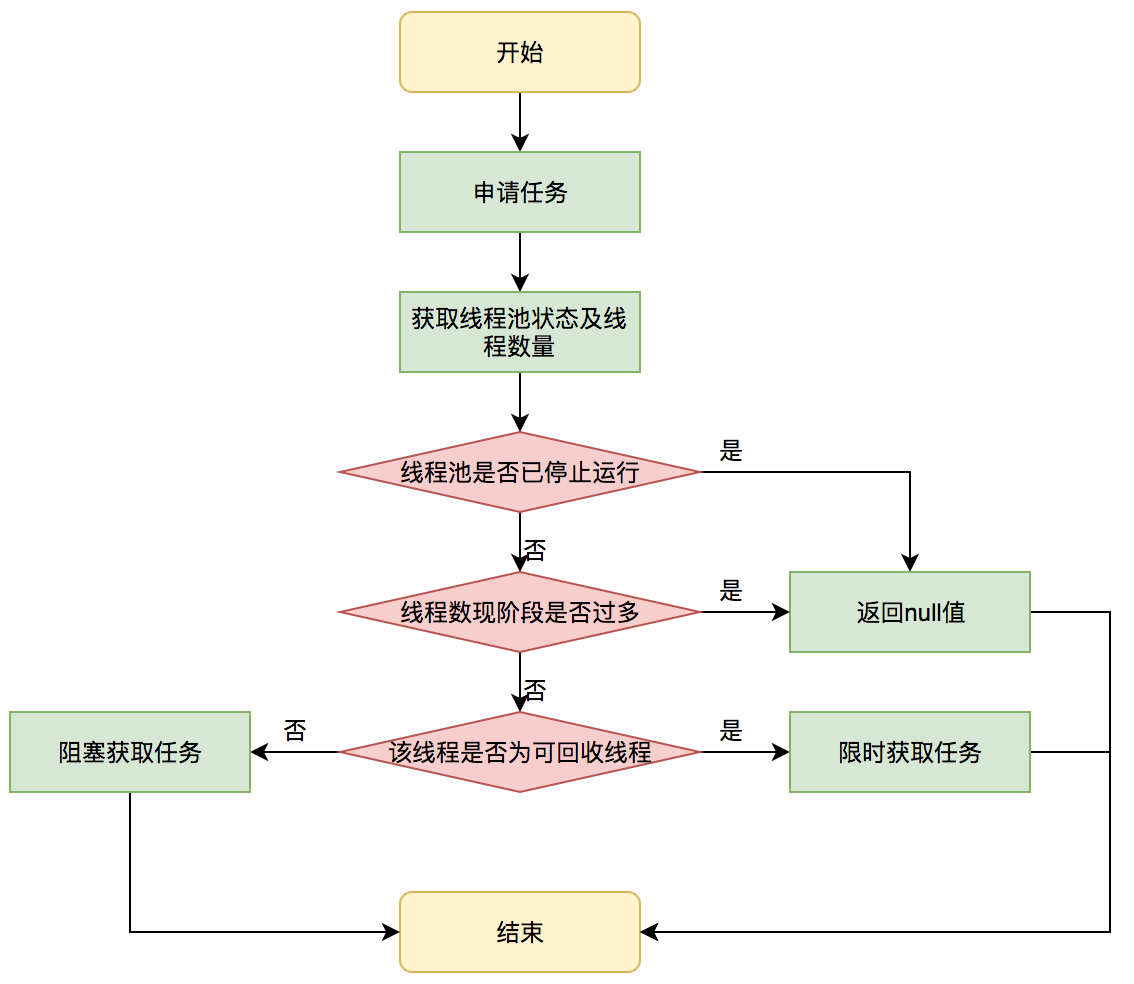

若有收获,就点个赞吧
0 人点赞
