所有的 Java 开发人员可能都会遇到这样的困惑:我该为堆内存设置多大空间?OutOfMemoryError 的异常到底涉及到运行时数据的哪块区域?我该怎么解决线上内存溢出的问题?
某东 618 活动,我下单了三本书,其中一本便是《深入理解 Java 虚拟机(第 2 版)》,连续看了 2 天,收获颇丰,有一种相见恨晚的感觉。接下来会刷第二遍、第三遍,推荐给还没入手的 Java 程序员,特别是搞后端开发的,建议只字不差地阅读,定有收获。
结合书本和 Google,我头脑中有了 JVM 内存结构和 Java 内存模型的概念,不如把它们总结下,这些知识点也是面试中经常考察的点。
JVM 内存结构
《深入理解 Java 虚拟机(第 2 版)》中的描述是下面这个样子的: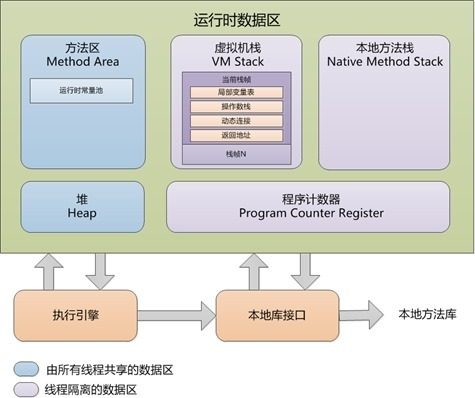
JVM 的内存结构大概分为:
- 堆(Heap):线程共享。所有的对象实例以及数组都要在堆上分配。回收器主要管理的对象。
- 方法区(Method Area):线程共享。存储类信息、常量、静态变量、即时编译器编译后的代码。
- 方法栈(JVM Stack):线程私有。存储局部变量表、操作栈、动态链接、方法出口,对象指针。
- 本地方法栈(Native Method Stack):线程私有。为虚拟机使用到的 Native 方法服务。如 Java 使用 c 或者 c++ 编写的接口服务时,代码在此区运行。
- 程序计数器(Program Counter Register):线程私有。有些文章也翻译成 PC 寄存器(PC Register),同一个东西。它可以看作是当前线程所执行的字节码的行号指示器。指向下一条要执行的指令。
先看一张图,这张图能很清晰的说明 JVM 内存结构的布局和相应的控制参数: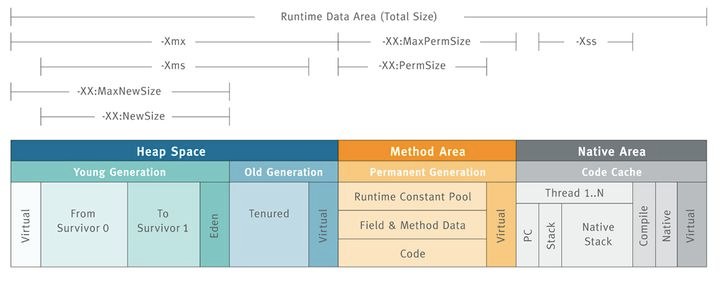
(图片来源于网络)
堆
堆的作用是存放对象实例和数组。从结构上来分,可以分为新生代和老年代。而新生代又可以分为 Eden 空间、From Survivor 空间(s0)、To Survivor 空间(s1)。 所有新生成的对象首先都是放在新生代的。需要注意,Survivor 的两个区是对称的,没先后关系,所以同一个区中可能同时存在从 Eden 复制过来的对象,和从前一个 Survivor 复制过来的对象,而复制到老年代的只有从第一个 Survivor 区过来的对象。而且,Survivor 区总有一个是空的。
- 控制参数
-Xms 设置堆的最小空间大小。-Xmx 设置堆的最大空间大小。-XX:NewSize 设置新生代最小空间大小。-XX:MaxNewSize 设置新生代最小空间大小。
- 垃圾回收
此区域是垃圾回收的主要操作区域。
- 异常情况
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出 OutOfMemoryError 异常
方法区
方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
很多人愿意把方法区称为 “永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为 HotSpot 虚拟机的设计团队选择把 GC 分代收集扩展至方法区,或者说使用永久代来实现方法区而已。对于其他虚拟机(如 BEA JRockit、IBM J9 等)来说是不存在永久代的概念的。在 Java8 中永生代彻底消失了。
- 控制参数
-XX:PermSize 设置最小空间 -XX:MaxPermSize 设置最大空间。
- 垃圾回收
对此区域会涉及但是很少进行垃圾回收。这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说这个区域的回收 “成绩” 比较难以令人满意。
- 异常情况
根据 Java 虚拟机规范的规定, 当方法区无法满足内存分配需求时,将抛出 OutOfMemoryError。
方法栈
每个线程会有一个私有的栈。每个线程中方法的调用又会在本栈中创建一个栈帧。在方法栈中会存放编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不等同于对象本身。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
- 控制参数
-Xss 控制每个线程栈的大小。
- 异常情况
在 Java 虚拟机规范中,对这个区域规定了两种异常状况:
- StackOverflowError: 异常线程请求的栈深度大于虚拟机所允许的深度时抛出;
- OutOfMemoryError 异常: 虚拟机栈可以动态扩展,当扩展时无法申请到足够的内存时会抛出。
本地方法栈
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其
区别不过是虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则
是为虚拟机使用到的 Native 方法服务。
- 控制参数
在 Sun JDK 中本地方法栈和方法栈是同一个,因此也可以用 - Xss 控制每个线程的大小。
- 异常情况
与虚拟机栈一样,本地方法栈区域也会抛出 StackOverflowError 和 OutOfMemoryError
异常。
程序计数器
它的作用可以看做是当前线程所执行的字节码的行号指示器。
- 异常情况
此内存区域是唯一一个在 Java 虚拟机规范中没有规定任何 OutOfMemoryError 情况的区域。
常见内存溢出错误
有了对内存结构清晰的认识,就可以帮助我们理解不同的 OutOfMemoryErrors,下面列举一些比较常见的内存溢出错误,通过查看冒号 “:” 后面的提示信息,基本上就能断定是 JVM 运行时数据的哪个区域出现了问题。
Exception in thread “main”: java.lang.OutOfMemoryError: Java heap space
原因:对象不能被分配到堆内存中。
Exception in thread “main”: java.lang.OutOfMemoryError: PermGen space
原因:类或者方法不能被加载到老年代。它可能出现在一个程序加载很多类的时候,比如引用了很多第三方的库。
Exception in thread “main”: java.lang.OutOfMemoryError: Requested array size exceeds VM limit
原因:创建的数组大于堆内存的空间。
Exception in thread “main”: java.lang.OutOfMemoryError: request
原因:分配本地分配失败。JNI、本地库或者 Java 虚拟机都会从本地堆中分配内存空间。
Exception in thread “main”: java.lang.OutOfMemoryError:
原因:同样是本地方法内存分配失败,只不过是 JNI 或者本地方法或者 Java 虚拟机发现。
关于 OutOfMemoryError 的更多信息可以查看:[Troubleshooting Guide for HotSpot VM”, Chapter 3 on “Troubleshooting on memory leaks]
Troubleshooting Memory Leaksdocs.oracle.com/javase/7/docs/webnotes/tsg/TSG-VM/html/memleaks.html
Java 内存模型
由上述对 JVM 内存结构的描述中,我们知道了堆和方法区是线程共享的。而局部变量,方法定义参数和异常处理器参数就不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
Java 线程之间的通信由 Java 内存模型(本文简称为 JMM)控制,JMM 决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM 定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读 / 写共享变量的副本。本地内存是 JMM 的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。Java 内存模型的抽象示意图如下: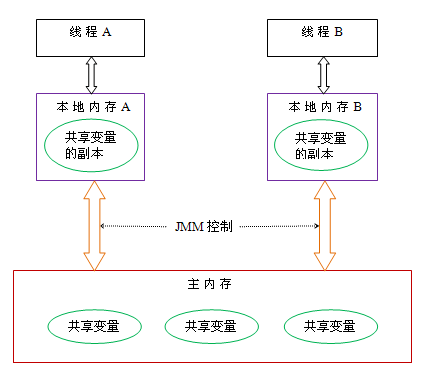
从上图来看,线程 A 与线程 B 之间如要通信的话,必须要经历下面 2 个步骤:
- 首先,线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中去。
- 然后,线程 B 到主内存中去读取线程 A 之前已更新过的共享变量。
下面通过示意图来说明这两个步骤: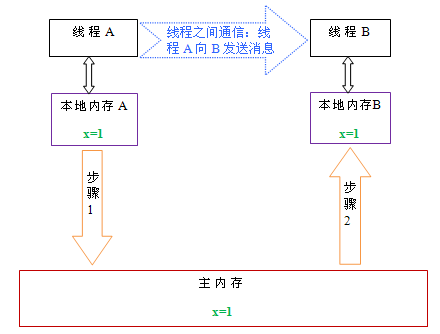
如上图所示,本地内存 A 和 B 有主内存中共享变量 x 的副本。假设初始时,这三个内存中的 x 值都为 0。线程 A 在执行时,把更新后的 x 值(假设值为 1)临时存放在自己的本地内存 A 中。当线程 A 和线程 B 需要通信时,线程 A 首先会把自己本地内存中修改后的 x 值刷新到主内存中,此时主内存中的 x 值变为了 1。随后,线程 B 到主内存中去读取线程 A 更新后的 x 值,此时线程 B 的本地内存的 x 值也变为了 1。
从整体来看,这两个步骤实质上是线程 A 在向线程 B 发送消息,而且这个通信过程必须要经过主内存。JMM 通过控制主内存与每个线程的本地内存之间的交互,来为 java 程序员提供内存可见性保证。
重排序
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。
这里说的重排序可以发生在好几个地方:编译器、运行时、JIT 等,比如编译器会觉得把一个变量的写操作放在最后会更有效率,编译后,这个指令就在最后了(前提是只要不改变程序的语义,编译器、执行器就可以这样自由的随意优化),一旦编译器对某个变量的写操作进行优化(放到最后),那么在执行之前,另一个线程将不会看到这个执行结果。
当然了,写入动作可能被移到后面,那也有可能被挪到了前面,这样的 “优化” 有什么影响呢?这种情况下,其它线程可能会在程序实现 “发生” 之前,看到这个写入动作(这里怎么理解,指令已经执行了,但是在代码层面还没执行到)。通过内存屏障的功能,我们可以禁止一些不必要、或者会带来负面影响的重排序优化,在内存模型的范围内,实现更高的性能,同时保证程序的正确性。
下面我们来看一个重排序的例子:
Class Reordering { int x = 0, y = 0; public void writer() { x = 1; y = 2; } public void reader() { int r1 = y; int r2 = x; } }
假设这段代码有 2 个线程并发执行,线程 A 执行 writer 方法,线程 B 执行 reader 方法,线程 B 看到 y 的值为 2,因为把 y 设置成 2 发生在变量 x 的写入之后(代码层面),所以能断定线程 B 这时看到的 x 就是 1 吗?
当然不行! 因为在 writer 方法中,可能发生了重排序,y 的写入动作可能发在 x 写入之前,这种情况下,线程 B 就有可能看到 x 的值还是 0。
在 Java 内存模型中,描述了在多线程代码中,哪些行为是正确的、合法的,以及多线程之间如何进行通信,代码中变量的读写行为如何反应到内存、CPU 缓存的底层细节。
在 Java 中包含了几个关键字:volatile、final 和 synchronized,帮助程序员把代码中的并发需求描述给编译器。JMM 中定义了它们的行为,确保正确同步的 Java 代码在所有的处理器架构上都能正确执行。
总结

若有收获,就点个赞吧
0 人点赞
