探究分析
prometheus
找到 pod 节点, 填入 sum by(pod, container) (container_memory_rss{image!=””,pod=”beetle-prod-arms-deploy-7f77b76876-lz844”}) / sum by(pod, container) (container_spec_memory_limit_bytes{image!=””,namespace=~”prod”}) * 100
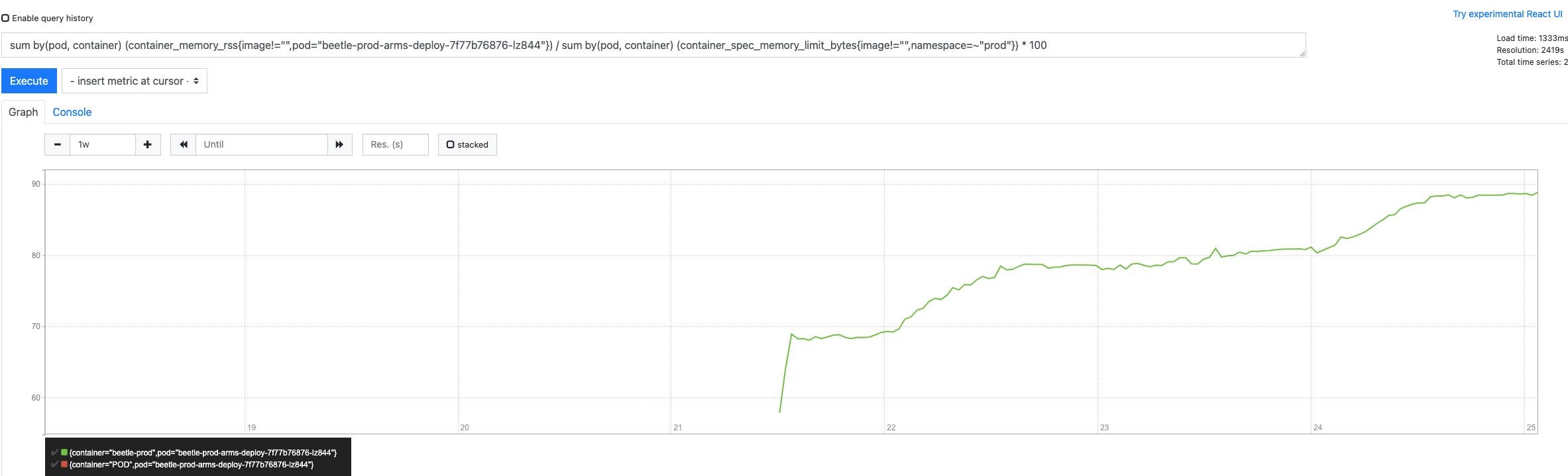
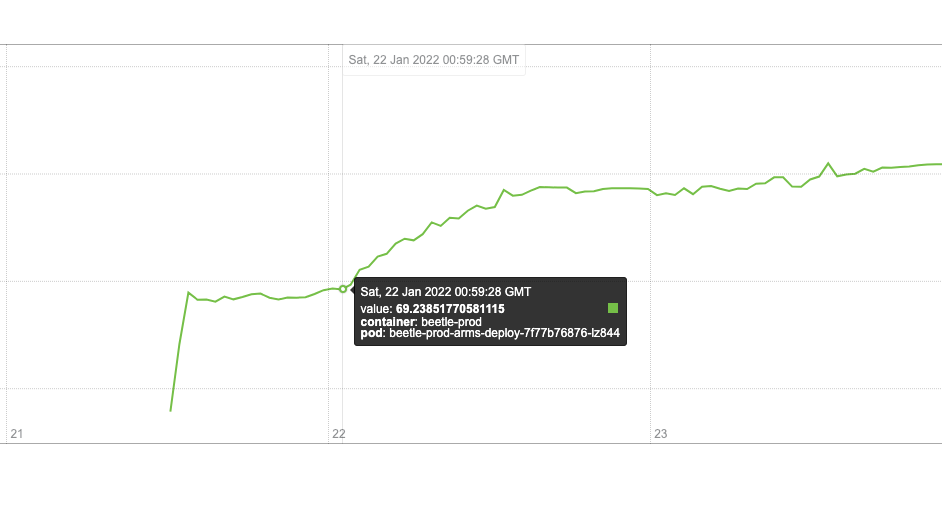
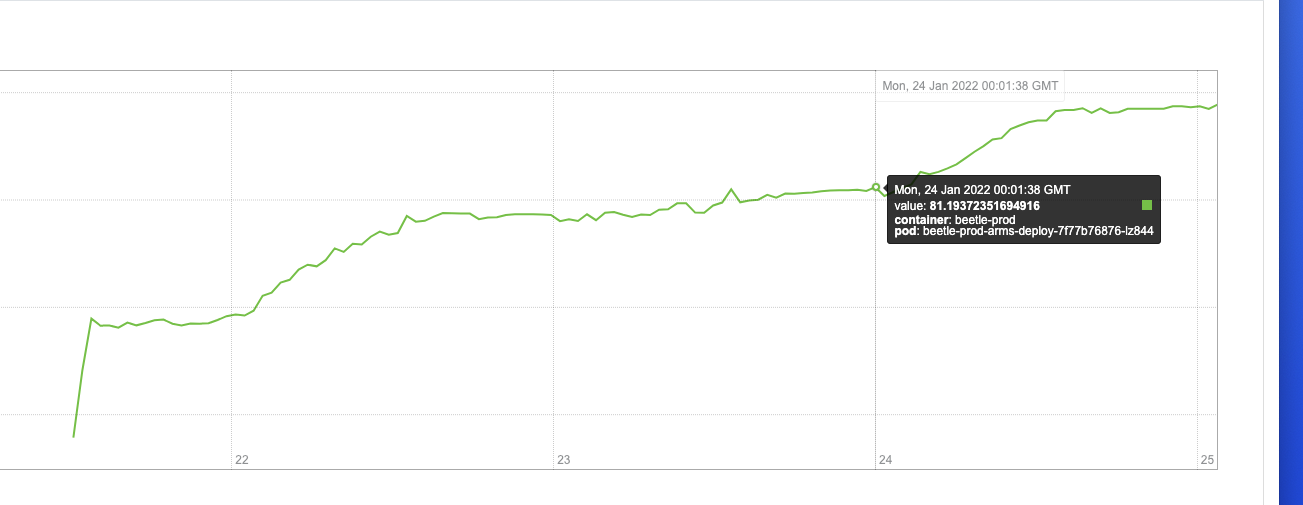
通过曲线图观察,找到两个时间节点,在这两个时间之后内存的使用率是成明显陡坡上升趋势的
接口调用
首先 beetle 只有 dubbo 接口的调用, 所以观察一下 dubbo 的调用情况,主要是 macan 和 blazer 调用比较多,白天的6点前的调用量会达到峰值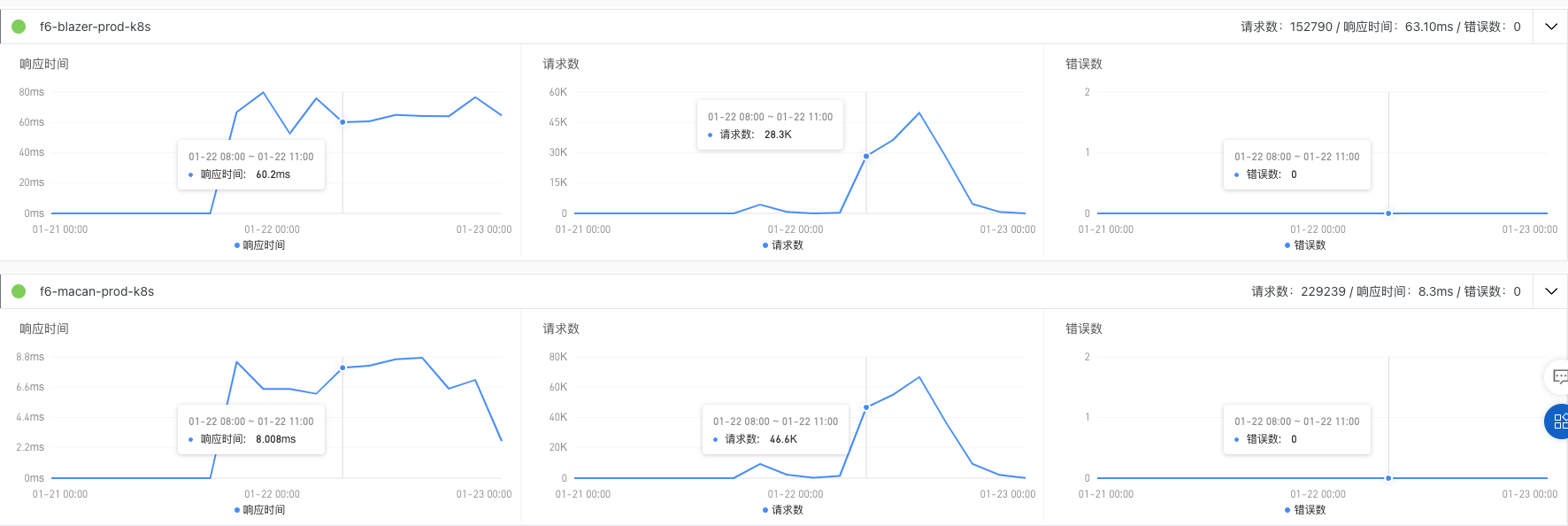
主要接口调用详情分析
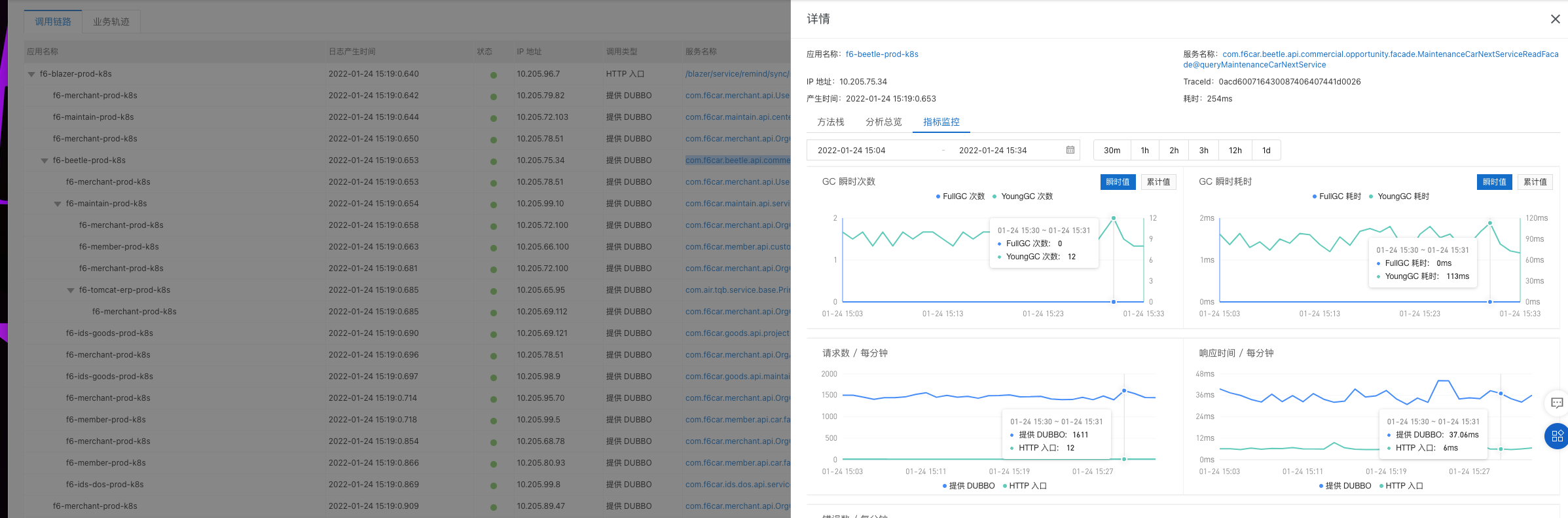
工单调用查询下次服务日
导购适配查询接口, 也有多次的 YoungGC ,但是频次和调用次数均少于查询下次服务日查询接口
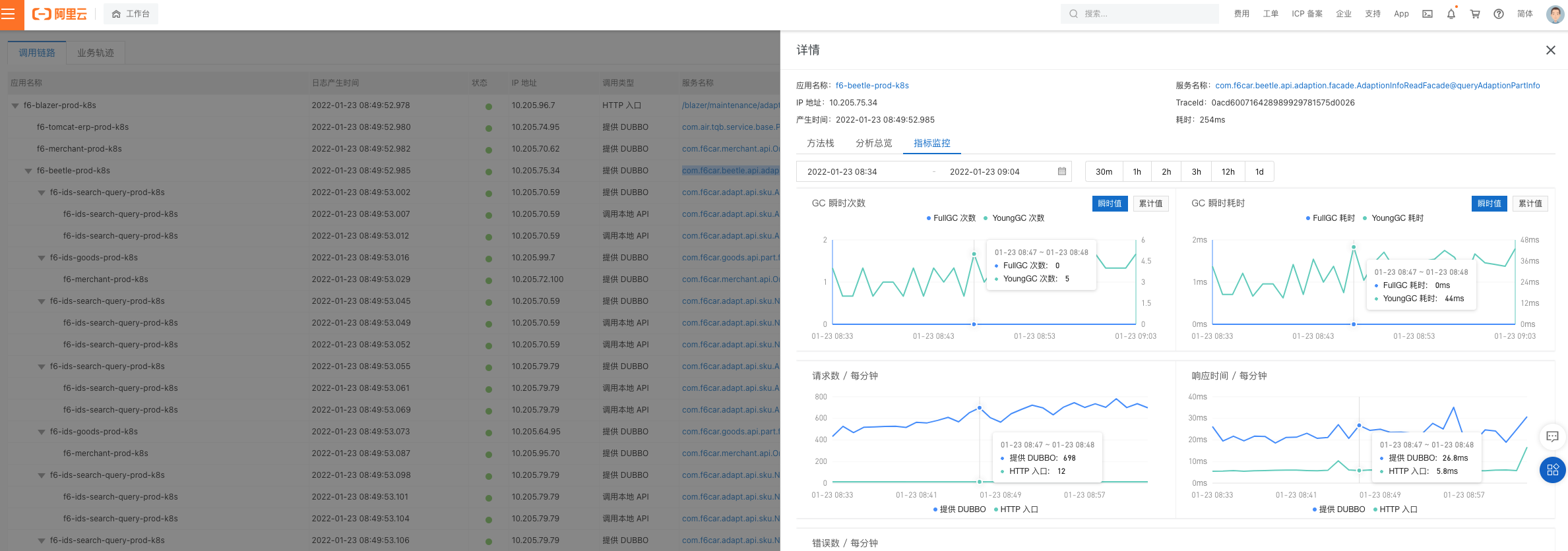
综合整体服务一直爬坡的上升趋势判断 应该是工单调用查询下次服务日接口导致的
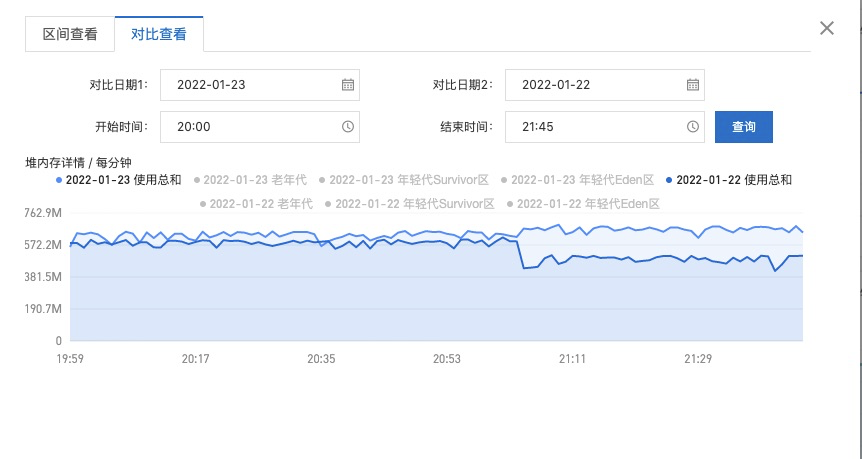
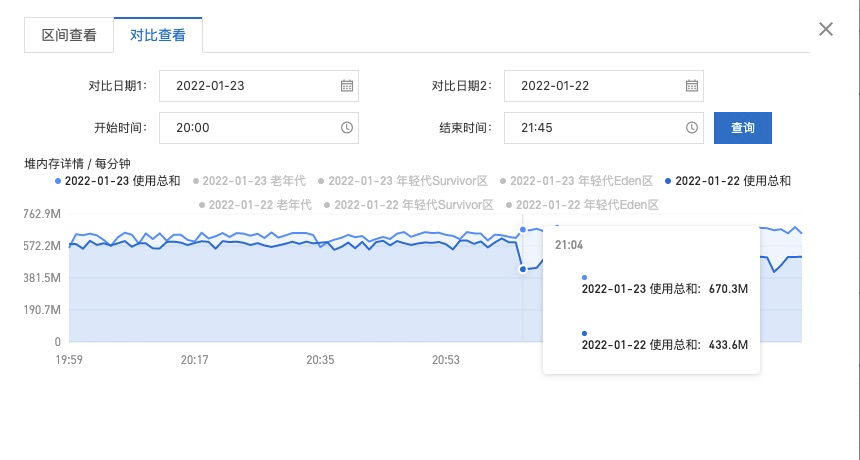
堆内存详情对比
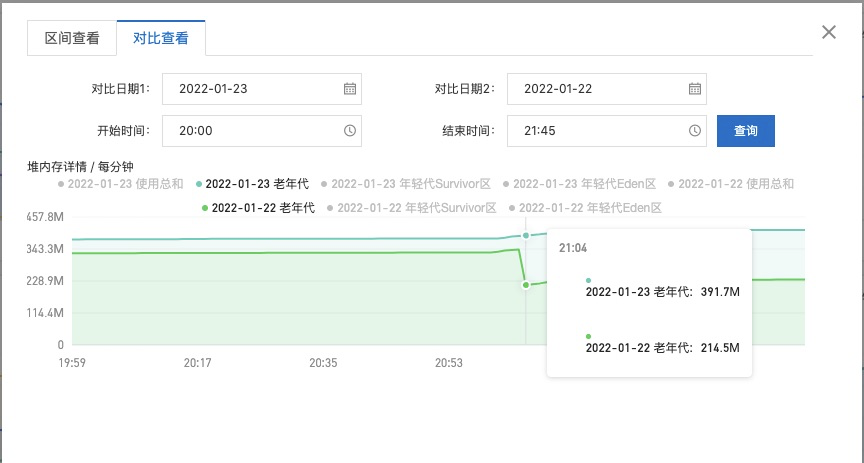
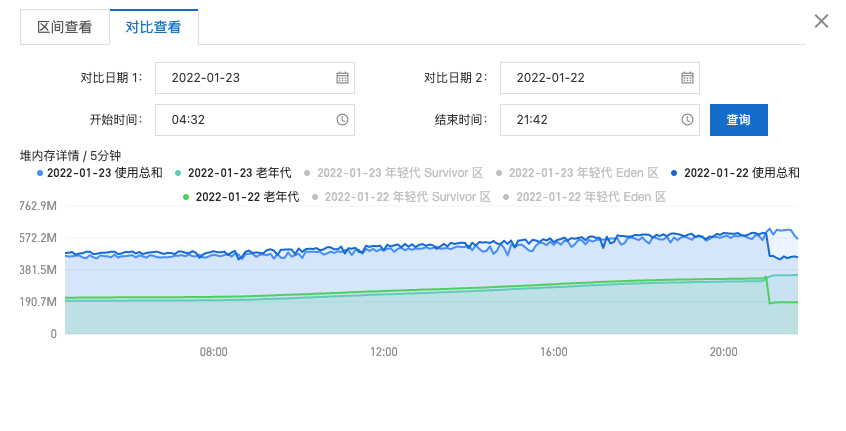
总结
- 通过曲线图陡坡和白天接口的调用量分析,晚上JOB是比较占用内存的
- 对比22号和23号的堆内存使用情况分析,22 号晚上JOB直接导致了一次FullGC清理缓存
- 后续老年代内存和使用总和就一直缓慢增加中,白天的工单查询下次服务日和晚上的定时提醒的JOB,应该是导致 rss 偏高的主要原因
代码梳理
定时提醒JOB接口分析
remindRuleEngineerReadFacade.queryBaseRemindRulePageInfo
- 规则对象字段全量返回了
- 查询的 bo 转换了 response 对象
一页1000条
carAnnualCheckRemindBillEngineerReadFacade.pagingCarAnnualCheckRemindBill查询提醒单对象全量返回了,
- 查询的 bo 转换了 response 对象
一页 1000 条
remindBillWriteService.batchUpdate
批量更新提醒单,入参全部提醒单字段
工单查询下次服务日接口分析
maintainDetailApi.selectMaintainDetailByPkId/maintainDetailApi.selectMaintainBaseByPkId/maintainHistoryApi.getMaintainMergedHistory
�
- 查询工单返回字段很多
改进方案
queryBaseRemindRulePageInfo
- 新增一个接口 pagingBaseRemindRule
- 查询字段精简,ruleType, RemindRuleMsgSettingApiInfo 对象和 List
- couponSetting 返回 couponId 和 couponName
- 查询页条数改成 500
pagingCarAnnualCheckRemindBill/queryServiceRemindBillList
�
- 新增接口 pagingCarAnnualCheckRemindBillForSendMsgJob/pagingServiceRemindBillForSendMsgJob
- 查询字段精简 remindSendMsgBill

- serviceSendMsgBill 新增 lastServiceDate
- 查询页条数改成 500
maintainDetailApi.selectMaintainDetailByPkId/maintainDetailApi.selectMaintainBaseByPkId/maintainHistoryApi.getMaintainMergedHistory
- 给工单提新接口需求,返回 ID/当前里程/下次服务里程/单据日期/单据状态/创建人/创建公司/创建门店

若有收获,就点个赞吧
0 人点赞
