HashMap 是我们常见的一种数据结构,实现 Map 接口,用来存储键值对,允许 null 键 / 值、非同步、不保证有序 (比如插入的顺序)。那 HashMap 中最核心的部分就是哈希函数,又称散列函数。也就是说,哈希函数是通过把 key 的 hash 值映射到数组中的一个位置来进行访问。比如:
存在一组哈希值 10,13,7,5,4,20 存在一个长度为10的数组 arrays 定义一个hash函数 int index = h % arrays.length; 10 % 10 = 0 那么 哈希值为10的对象放在数组索引为0的位置上; 13 % 10 = 3 那么 哈希值为13的对象放在数组索引为3的位置上; …… 20 % 10 = 0 那么 哈希值为13的对象放在数组索引为0的位置上;
存在一组哈希值 10,13,7,5,4,20存在一个长度为10的数组 arrays定义一个hash函数 int index = h % arrays.length;10 % 10 = 0 那么 哈希值为10的对象放在数组索引为0的位置上;13 % 10 = 3 那么 哈希值为13的对象放在数组索引为3的位置上;......20 % 10 = 0 那么 哈希值为13的对象放在数组索引为0的位置上;
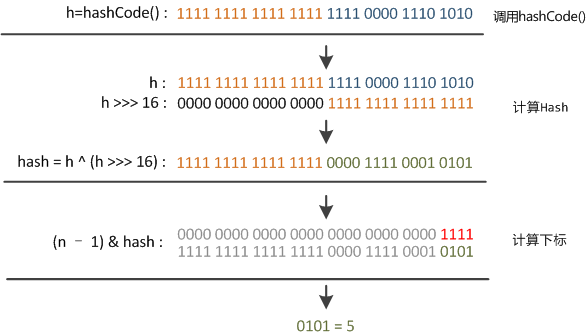
hashCode 右移 16 位,正好是 32bit 的一半。与自己本身做异或操作(相同为 0,不同为 1)。就是为了混合哈希值的高位和地位,增加低位的随机性。并且混合后的值也变相保持了高位的特征。
这时候大家看出了一个问题,哈希值为 10 的对象和哈希值为 20 的对象,放在了一个索引上。发生了碰撞,那么怎么解决这样碰撞呢,有很多种方式,这里不展开叙述。HashMap 中维护了一个链表组成的数组。如果冲突的话就添加到链表中,下面来看下 hashmap 中的 hash 算法,以 Java8 源码为例。
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
其中,key.hashCode()是 Key 自带的 hashCode () 方法,返回一个 int 类型的散列值。我们大家知道,32 位带符号的 int 表值范围从 - 2147483648 到 2147483648。这样只要 hash 函数松散的话,一般是很难发生碰撞的,因为 HashMap 的初始容量只有 16。但是这样的散列值我们是不能直接拿来用的。用之前需要对数组的长度取模运算。得到余数才是索引值。我们来看下 HashMap 中怎么实现的。
int index = hash & (arrays.length-1);
那么这也就明白了为什么 HashMap 的数组长度是 2 的整数幂。比如以初始长度为 16 为例,16-1 = 15,15 的二进制数位 00000000 00000000 00001111。可以看出一个基数二进制最后一位必然位 1,当与一个 hash 值进行与运算时,最后一位可能是 0 也可能是 1。但偶数与一个 hash 值进行与运算最后一位必然为 0,造成有些位置永远映射不上值。
但是这时,又出现了一个问题,即使散列函数很松散,但只取最后几位碰撞也会很严重。这时候 hash 算法的价值就体现出来了,
HashMap 中用到的编码思想确实很值得我们学习。HashMap 在 Java1.8 后又进行了优化,比如引入红黑树的数据结构和扩容的优化等。有机会我们再结合 Java1.8 聊聊,HashMap get () 和 put()实现原理,装载因子,resize () 方法还有红黑树等。
作者:程序猿Jeffrey
链接:https://www.jianshu.com/p/2fee1d246cad
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
