1、什么是 CAS?
CAS:Compare and Swap,即比较再交换。
jdk5 增加了并发包 java.util.concurrent.*, 其下面的类使用 CAS 算法实现了区别于 synchronouse 同步锁的一种乐观锁。JDK 5 之前 Java 语言是靠 synchronized 关键字保证同步的,这是一种独占锁,也是是悲观锁。
2、CAS 算法理解
对 CAS 的理解,CAS 是一种无锁算法,CAS 有 3 个操作数,内存值 V,旧的预期值 A,要修改的新值 B。当且仅当预期值 A 和内存值 V 相同时,将内存值 V 修改为 B,否则什么都不做。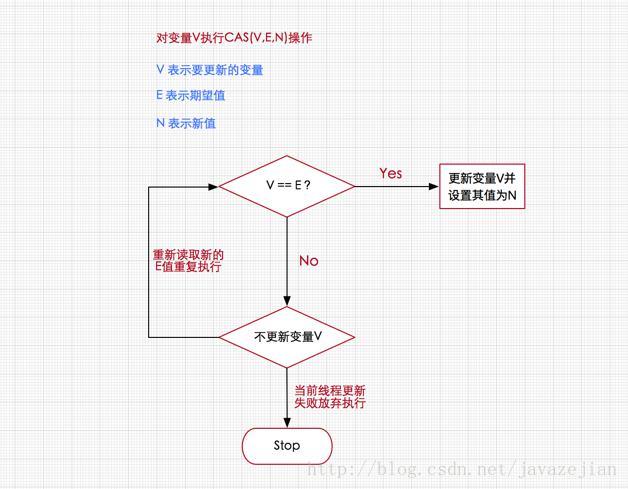
CAS 比较与交换的伪代码可以表示为:
do{ 备份旧数据; 基于旧数据构造新数据; }while(!CAS( 内存地址,备份的旧数据,新数据 ))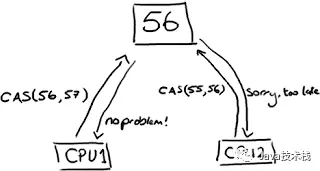
https://upload-images.jianshu…
注:t1,t2 线程是同时更新同一变量 56 的值
因为 t1 和 t2 线程都同时去访问同一变量 56,所以他们会把主内存的值完全拷贝一份到自己的工作内存空间,所以 t1 和 t2 线程的预期值都为 56。
假设 t1 在与 t2 线程竞争中线程 t1 能去更新变量的值,而其他线程都失败。(失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次发起尝试)。t1 线程去更新变量值改为 57,然后写到内存中。此时对于 t2 来说,内存值变为了 57,与预期值 56 不一致,就操作失败了(想改的值不再是原来的值)。
(上图通俗的解释是:CPU 去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值。)
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的 commit-retry 的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
3、CAS 缺点
CAS 虽然很高效的解决原子操作,但是 CAS 仍然存在三大问题。ABA 问题,循环时间长开销大和只能保证一个共享变量的原子操作。
3.1、ABA 问题
因为 CAS 需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是 A,变成了 B,又变成了 A,那么使用 CAS 进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA 问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么 A-B-A 就会变成 1A-2B-3A。
从 Java1.5 开始 JDK 的 atomic 包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。这个类的 compareAndSet 方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
解决方案
CAS 类似于乐观锁,即每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。因此解决方案也可以跟乐观锁一样:
- 使用版本号机制,如手动增加版本号字段
Java 1.5 开始,JDK 的 Atomic 包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。这个类的 compareAndSet 方法的作用是首先检查当前引用是否等于预期引用,并且检查当前的标志是否等于预期标志,如果全部相等,则以原子方式将该应用和该标志的值设置为给定的更新值。
3.2、循环时间长开销大
自旋 CAS 如果长时间不成功,会给 CPU 带来非常大的执行开销。如果 JVM 能支持处理器提供的 pause 指令那么效率会有一定的提升,pause 指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline), 使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起 CPU 流水线被清空(CPU pipeline flush),从而提高 CPU 的执行效率。
解决方案破坏掉 for 死循环,当超过一定时间或者一定次数时,return 退出。JDK8 新增的 LongAddr, 和 ConcurrentHashMap 类似的方法。当多个线程竞争时,将粒度变小,将一个变量拆分为多个变量,达到多个线程访问多个资源的效果,最后再调用 sum 把它合起来。
如果 JVM 能支持处理器提供的 pause 指令,那么效率会有一定的提升。pause 指令有两个作用:第一,它可以延迟流水线执行指令(de-pipeline),使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零;第二,它可以避免在循环的时候因内存顺序冲突(Memory Order Violation)而引起 CPU 流水线被清空,从而提高 CPU 的实行效率。
3.3、只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量 i=2,j=a,合并一下 ij=2a,然后用 CAS 来操作 ij。从 Java1.5 开始 JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作。
解决方案用锁
- 把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量 i=2,j=a, 合并一下 ji=2a, 然后用 CAS 来操作 ij。
- 封装成对象。注:从 Java 1.5 开始,JDK 提供了 AtomicReference 类来保证引用对象之前的原子性,可以把多个变量放在一个对象里来进行 CAS 操作。
3.4、比较花费 CPU 资源,即使没有任何争用也会做一些无用功。
3.5、会增加程序测试的复杂度,稍不注意就会出现问题。
4、CAS 算法在 JDK 中的应用
在原子类变量中,如 java.util.concurrent.atomic 中的 AtomicXXX,都使用了这些底层的 JVM 支持为数字类型的引用类型提供一种高效的 CAS 操作,而在 java.util.concurrent 中的大多数类在实现时都直接或间接的使用了这些原子变量类。
Java 1.7 中 AtomicInteger.incrementAndGet () 的实现源码为:
https://upload-images.jianshu…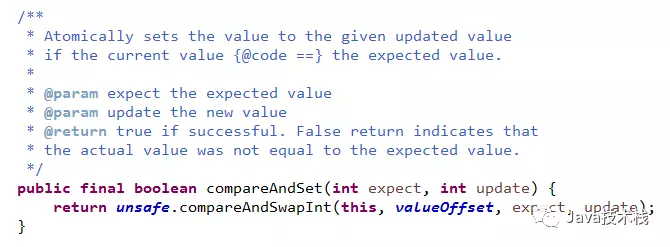
https://upload-images.jianshu…
由此可见,AtomicInteger.incrementAndGet 的实现用了乐观锁技术,调用了类 sun.misc.Unsafe 库里面的 CAS 算法,用 CPU 指令来实现无锁自增。所以,AtomicInteger.incrementAndGet 的自增比用 synchronized 的锁效率倍增。
参考:https://www.jianshu.com/p/21b…
https://blog.csdn.net/yanluan…
https://blog.csdn.net/q287894…
https://segmentfault.com/a/11…

若有收获,就点个赞吧
0 人点赞
