原文链接:https://blog.csdn.net/lvqinglou/article/details/120223089
Mysql Innodb 数据写入总览
Innodb 结构图
以下内容参考自 Mysql 官方文档
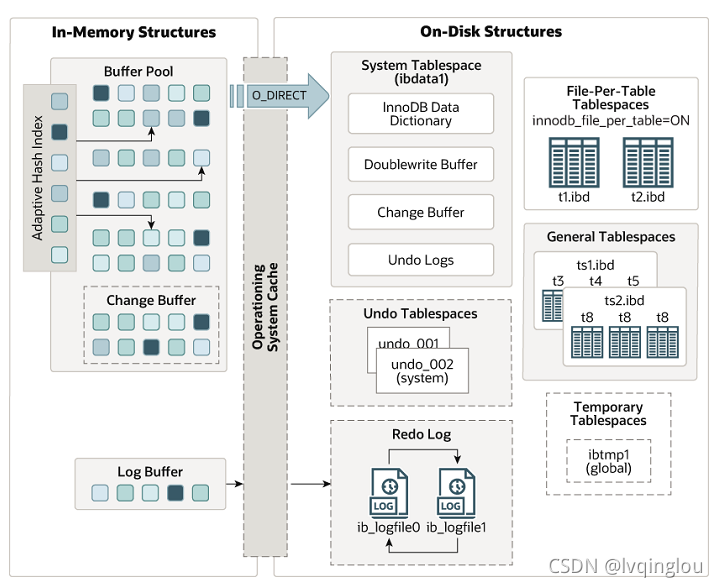
Innodb 数据写入过程(开启 binlog)

由于 innodb 需要事务性的保证(redo log、undo log), 所以写入流程会复杂一些。
首先,在数据要被写入或者修改时,一定要先查找到该数据所位于的 page(Mysql 操控数据的最小单位),如果 page 没有位于 buffer pool,会发生缺页中断,加载磁盘上的 page 到 buffer pool 中。
查找到 page 以后,先要保存当前数据到 undo log 日志中(为了事务回滚后,数据也能回滚)。
之后会直接修改 page 上的数据(buffer pool 中的脏页达到一定比例时,会进行刷盘操作),并记录在 redo log buffer 中记录 redo log 日志(用于事务的持久化)。
如果数据库同时开启了 binlog,也会触发一个 rego log 和 binlog 的二阶段提交过程。
以上是正常流程,Mysql 对于索引上的写操作进行了额外优化,详情见 change buffer
Innodb 相关组件介绍
redolog
redolog 日志是 Innodb 用于保障事务中持久性的基石。
为了提升数据的写入速度,Mysql 只是简单的在 Page buffer(内存中)修改了数据,并没有进行刷盘操作,在某些情况下,数据会发生丢失的可能。所以为了避免数据丢失,Mysql 使用了 WAL 机制,在事务数据写入内存后,会紧接着写入 redo 日志,这样在意外宕机的情况下,Mysql 仍能根据 redo 日志恢复出完整数据。
redo 默认是先写入 log buffer 中的,所以会存在 redo 丢失的可能,Mysql 提供了 innodb_flush_log_at_trx_commit 参数用于控制刷盘时机。
innodb_flush_log_at_trx_commit = 0 :只写 log buffer,redo log buffer 每隔 1S 会刷到磁盘上。
innodb_flush_log_at_trx_commit = 1 :每次事务提交前都会添加到 redo log 日志并刷到磁盘上。
innodb_flush_log_at_trx_commit = 2 :每次事务提交前只会写入 redo log 日志但不会刷盘,会等待每秒一次的刷盘操作。
刷盘是个昂贵操作,但是为了保障数据不丢失,一般都会设置成 1,所以 Mysql 写入性能并不是很强。
redolog、binlog 双写一致性
有关双写一致性参考于官方文档
binlog 是在 Mysql 层面上的日志,而 redolog 只是 Innodb 为了持久性而设计的日志,一般情况下,为了做数据同步用,binlog 都会是开启状态,Innodb 采用了两阶段提交方式来保障 redolog 和 binlog 的一致性。
- 先写 redolog 日志,生成事务标记 xid,并设置状态为 prepare 状态
- 写入 binlog 日志
- 进行事务提交,更改 xid 的 redolog 变成 commit 状态
3.1. 假设事务提交失败了,但是 binlog 写入成功了,Mysql 会从 binlog 日志中获取最后一条 xid,并将该 xid 对应的 redolog 改为提交状态并用于恢复数据。
Mysql5.7 以后默认开启了两阶段提交并且不可关闭,但是这会带来额外的消耗,因为想要保证强一致性的话,redo 日志会被刷盘两次(prepare 和 commit)
undolog
undolog 会保留每行数据一段时间内所有事务的操作记录,用于进行事务回滚以及帮助 MVCC 进行事务隔离。
由于 undo 链过长会影响性能,所以 Mysql 会定时的获取当前所有 readview 中最老的活跃事务 id,并使用 purge 线程将该事务之前的 undolog 进行回收。
buffer pool
buffer pool 是 Mysql 最核心的一块区域,主要作用就是为了提升 Mysql 的读写性能而存在的。
Mysql 在修改数据时,并不会直接去修改磁盘上的数据(属于随机 IO,性能很差),而是先将磁盘上的 page 加载到 buffer pool 再进行操作,相当于将磁盘的随机 IO 转变成了内存的随机 IO,提升了大量性能。
buffer pool 使用变种 LRU 算法进行 page 的维护和淘汰策略,如下图所示。
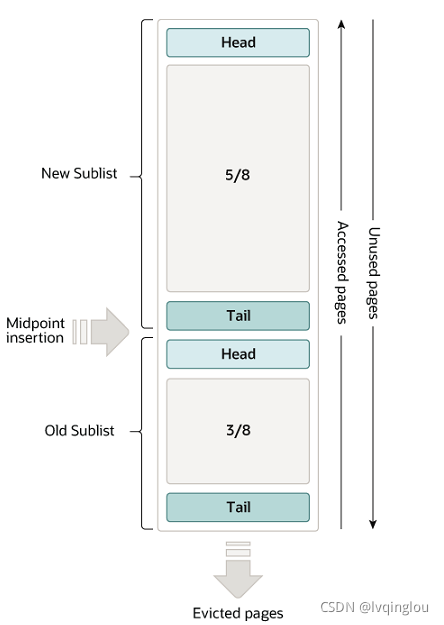
该算法将 buffer pool 按照 5:3 分成了两部分,page 第一次被加载时,会先进入 old sublist 区域的头部。
在 old 区域中的 page 会等待再次读取并且停留时间达到一定目标后,才会进入到 new sublist 区域中。
而 new 区域中的 page 也会随时间推移,而降级到 old 区域中。
当 buffer pool 空间不足时,会先从 old 区域的尾部进行淘汰。
change buffer
如果一条 update 语句是位于普通索引(非唯一索引)上的修改,比方说要修改 page500 上的某条数据,那么该条修改记录会先记录到 change buffer 中,而不是产生缺页中断去磁盘上加载新 page500。如果在之后的过程中,有新的查询需要加载该 page500,当 page500 加载到 buffer pool 时,会与 change buffer 中的相关记录做一次合并操作。
这样可以看出明显能节省一次 IO 过程,有利于写性能的提高。
double write
Mysql 是以 page 为单位从磁盘上获取数据加载到内存或者从内存中写入磁盘的,page 的默认大小为 16KB,而目前并不是所有的磁盘都能支持 16KB 的原子性写入的(很多磁盘的块大小是 4KB),所以会导致一种情况,Mysql 向磁盘中写入一个 page 时,如果发生意外,磁盘上就会存在一个损坏的 page,这将导致 Mysql 在下次重启过程中,无法恢复该页数据,导致数据丢失。
所以 buffer pool 中的脏页在写入磁盘前,会先写入 double write buffer (会持久化到共享表空间),这样在磁盘上的 page 发生缺失时,还可以根据 double write 中的副本页进行恢复。
如果 double write 持久化时 Mysql 挂了,那么 Mysql 会根据脏页前的 page + redo log 进行数据恢复。
在 innodb 中 double write 是默认开启的,如果不在乎数据丢失或者磁盘可以支持 16KB 原子写,可以关闭该功能,用于提高 Mysql 写入性能。
全文完
本文由 简悦 SimpRead 转码,用以提升阅读体验,原文地址

若有收获,就点个赞吧
0 人点赞
