ZooKeeper 是一个分布式服务框架,主要是用来解决分布式应用中遇到的一些数据管理问题如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
我们可以简单把 ZooKeeper 理解为分布式家庭的大管家,那么管家团队是如何选出 Leader 的呢?好奇吗,接下来带领大家一探究竟。
讲解 ZooKeeper 选举过程前先来介绍一下人类的选举。
我们每个人或多或少都经历过几次选举,在投票的过程中可能会遇到这样几种情况:
情况 1:自己与几个候选人都比较熟,你会将票投给你认为能力比较强的人;
人类选举的基本原理

熟人选举
情况 2:自己也是候选人,并且与其他几个候选人都不熟,这个时候你肯定想着要去拉票,因为觉得自己才是最厉害的人呀,所有人都应该把票投给我。但是遗憾的是在拉票的过程中,你发现别人比你强,你开始自卑了,最终还是把票投给了自己认为最强的人。
自己参与选举
所有人都投完票之后,最后从投票箱中进行统计,获得票数最多的人当选。
思维导图
在整个投票过程中我们可以提炼出四个最核心的概念:
从人类选举的原理我们来简单推导一下 ZooKeeper 的选举原理。
注意如果 ZooKeeper 是单机部署是不需要选举的,集群模式下才需要选举。
ZooKeeper 的选举原理和人类选举的逻辑类似,套用一下人类选举的四个基本概念详细解释一下 ZooKeeper。
如何衡量 ZooKeeper 节点个人能力?答案是靠数据是否够新,如果节点的数据越新就代表这个节点的个人能力越强,是不是感觉很奇怪,就是这么定的!
在 ZooKeeper 中通常是以事务 id(后面简称 zxid)来标识数据的新旧程度(版本),节点最新的 zxid 越大代表这个节点的数据越新,也就代表这个节点能力越强。
zxid 的全称是 ZooKeeper Transaction Id,即 ZooKeeper 事务 id。
在集群选举开始时,节点首先认为自己是最强的(即数据是最新的),然后在选票上写上自己的名字(包括 zxid 和 sid),zxid 是事务 id,sid 唯一标识自己。
紧接着会将选票传递给其他节点,同时自己也会接收其他节点传过来的选票。每个节点接收到选票后会做比较,这个人是不是比我强(zxid 比我大),如果比较强,那我就需要改票,明明别人比我强,我也不能厚着脸皮对吧。
与人类选举投票箱稍微有点不一样,ZooKeeper 集群会在每个节点的内存中维护一个投票箱。节点会将自己的选票以及其他节点的选票都放在这个投票箱中。由于选票是互相传阅的,所以最终每个节点投票箱中的选票会是一样的。
在投票的过程中会去统计是否有超过一半的选票和自己选择的是同一个节点,即都认为某个节点是最强的。一旦集群中有超过半数的节点都认为某个节点最强,那该节点就是领导者了,投票也宣告结束。
当 ZooKeeper 集群中的一台服务器出现以下两种情况之一时,需要进入 Leader 选举。
假设一个 ZooKeeper 集群中有 5 台服务器,id 从 1 到 5 编号,并且它们都是最新启动的,没有历史数据。
集群刚启动选举过程
假设服务器依次启动,我们来分析一下选举过程:
1、服务器 1 启动
发起一次选举,服务器 1 投自己一票,此时服务器 1 票数一票,不够半数以上(3 票),选举无法完成。
投票结果:服务器 1 为 1 票。
服务器 1 状态保持为 LOOKING。
2、服务器 2 启动
发起一次选举,服务器 1 和 2 分别投自己一票,此时服务器 1 发现服务器 2 的 id 比自己大,更改选票投给服务器 2。
投票结果:服务器 1 为 0 票,服务器 2 为 2 票。
服务器 1,2 状态保持 LOOKING。
3、服务器 3 启动
发起一次选举,服务器 1、2、3 先投自己一票,然后因为服务器 3 的 id 最大,两者更改选票投给为服务器 3;
投票结果:服务器 1 为 0 票,服务器 2 为 0 票,服务器 3 为 3 票。此时服务器 3 的票数已经超过半数(3 票),服务器 3 当选 Leader。
服务器 1,2 更改状态为 FOLLOWING,服务器 3 更改状态为 LEADING。
4、服务器 4 启动
发起一次选举,此时服务器 1,2,3 已经不是 LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器 3 为 3 票,服务器 4 为 1 票。此时服务器 4 服从多数,更改选票信息为服务器 3。
服务器 4 并更改状态为 FOLLOWING。
5、服务器 5 启动
与服务器 4 一样投票给 3,此时服务器 3 一共 5 票,服务器 5 为 0 票。
服务器 5 并更改状态为 FOLLOWING。
最终的结果:
服务器 3 是 Leader,状态为 LEADING;其余服务器是 Follower,状态为 FOLLOWING。
在 ZooKeeper 运行期间 Leader 和 非 Leader 各司其职,当有非 Leader 服务器宕机或加入不会影响 Leader,但是一旦 Leader 服务器挂了,那么整个 ZooKeeper 集群将暂停对外服务,会触发新一轮的选举。
初始状态下服务器 3 当选为 Leader,假设现在服务器 3 故障宕机了,此时每个服务器上 zxid 可能都不一样,server1 为 99,server2 为 102,server4 为 100,server5 为 101。
集群 Leader 节点故障
运行期选举与初始状态投票过程基本类似,大致可以分为以下几个步骤:
话不多说先来一张图:
【6】
运行器 Leader 故障后选举流程
敲黑板了,这些概念是面试必考的。
原文链接:https://mp.weixin.qq.com/s/TNF7FZJMJd4YEAN2AvWsCw

- 候选人能力:投票的基本原则是选最强的人。
- 遇强改投:如果后面发现更强的人可以改投票。
- 投票箱:所有人的票都会放在投票箱。
-
ZooKeeper 选举的基本原理
个人能力
遇强改投
投票箱
领导者
什么场景下 ZooKeeper 需要选举?
服务器初始化启动。
-
启动时期的 Leader 选举
运行时期的 Leader 选举
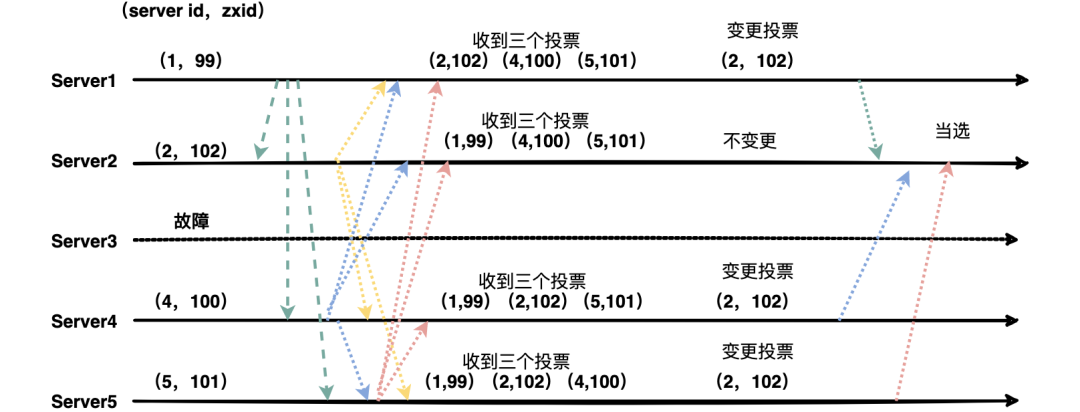
状态变更。Leader 故障后,余下的非 Observer 服务器都会将自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
- 每个 Server 会发出投票。
- 接收来自各个服务器的投票,如果其他服务器的数据比自己的新会改投票。
- 处理和统计投票,每一轮投票结束后都会统计投票,超过半数即可当选。
- 改变服务器的状态,宣布当选。
- 第一次投票,每台机器都会将票投给自己。
接着每台机器都会将自己的投票发给其他机器,如果发现其他机器的 zxid 比自己大,那么就需要改投票重新投一次。比如 server1 收到了三张票,发现 server2 的 xzid 为 102,pk 一下发现自己输了,后面果断改投票选 server2 为老大。
选举机制中涉及到的核心概念
Server id(或 sid):服务器 ID,比如有三台服务器,编号分别是 1,2,3。编号越大在选择算法中的权重越大,比如初始化启动时就是根据服务器 ID 进行比较。
- Zxid:事务 ID,服务器中存放的数据的事务 ID,值越大说明数据越新,在选举算法中数据越新权重越大。
- Epoch:逻辑时钟,也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个数据就会增加。
Server 状态:选举状态
ZooKeeper 选举会发生在服务器初始状态和运行状态下。
- 初始状态下会根据服务器 sid 的编号对比,编号越大权值越大,投票过半数即可选出 Leader。
- Leader 故障会触发新一轮选举,zxid 代表数据越新,权值也就越大。
- 在运行期选举还可能会遇到脑裂的情况,大家可以自行学习。



若有收获,就点个赞吧
0 人点赞
