Flask教程(二十)flask-apscheduler
与 flask 集成时, 多 work 管理问题
2020-10-08
文章目录
软硬件环境
- windows 10 64bit
- anaconda3 with python 3.7
- pycharm 2020.1.2
- flask 1.1.2
- flask-apscheduler 1.11.0
视频看这里
此处是youtube的播放链接,需要科学上网。喜欢我的视频,请记得订阅我的频道,打开旁边的小铃铛,点赞并分享,感谢您的支持。
前言
前文 Python实用模块之apscheduler 已经介绍过的基本使用了。flask - apscheduler 将apscheduler移植到了flask应用中,使得在flask中可以非常方便的使用定时任务了,除此之外,它还有如下几个特性
- 根据
Flask配置加载调度器配置 - 根据
Flask配置加载任务调度器 - 允许指定服务器运行任务
- 提供
RESTful API管理任务,也就是远程管理任务 - 为
RESTful API提供认证
使用示例
在使用之前,我们需要安装这个模块,使用pip
pip install flask-apscheduler
flask-apscheduler的相关配置,我们会将它和其它扩展一起,放在应用的配置里,下面先来看个间隔定时任务
from flask import Flaskfrom flask_apscheduler import APSchedulerclass Config(object):JOBS = [{'id': 'job1','func': 'run:add','args': (1, 2),'trigger': 'interval','seconds': 3}]SCHEDULER_API_ENABLED = Truedef add(a, b):print(a+b)if __name__ == '__main__':app = Flask(__name__)app.config.from_object(Config())scheduler = APScheduler()scheduler.init_app(app)scheduler.start()app.run()
在Config类里,有一个列表JOBS,每个元素是一项任务,上面的示例代码中只有一个任务,是一个interval任务,每3秒执行一次,具体执行的任务方法是add,接收2个参数。func后面的值格式是 模块名:方法名
在flask app实例化后,运行之前,我们进行flask-apscheduler的初始化,这一步必不可少
scheduler = APScheduler()scheduler.init_app(app)scheduler.start()
执行上面的工程,我们可以得到
(FlaskTutorial) D:\xugaoxiang\FlaskTutorial\Flask-20-apscheduler>python run.py* Serving Flask app "run" (lazy loading)* Environment: productionWARNING: This is a development server. Do not use it in a production deployment.Use a production WSGI server instead.* Debug mode: off* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)333
上边我们设置了SCHEDULER_API_ENABLED = True,可以通过访问 http://127.0.0.1:5000/scheduler ,其中scheduler是默认的RESTful API前缀
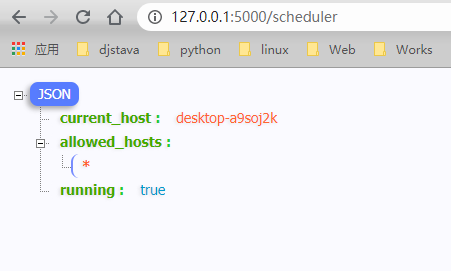
通过查看源码文件scheduler.py,我们可以看到flask-apscheduler为我们提供了哪些RESTful API
def _load_api(self):"""Add the routes for the scheduler API."""self._add_url_route('get_scheduler_info', '', api.get_scheduler_info, 'GET')self._add_url_route('add_job', '/jobs', api.add_job, 'POST')self._add_url_route('get_job', '/jobs/<job_id>', api.get_job, 'GET')self._add_url_route('get_jobs', '/jobs', api.get_jobs, 'GET')self._add_url_route('delete_job', '/jobs/<job_id>', api.delete_job, 'DELETE')self._add_url_route('update_job', '/jobs/<job_id>', api.update_job, 'PATCH')self._add_url_route('pause_job', '/jobs/<job_id>/pause', api.pause_job, 'POST')self._add_url_route('resume_job', '/jobs/<job_id>/resume', api.resume_job, 'POST')self._add_url_route('run_job', '/jobs/<job_id>/run', api.run_job, 'POST')
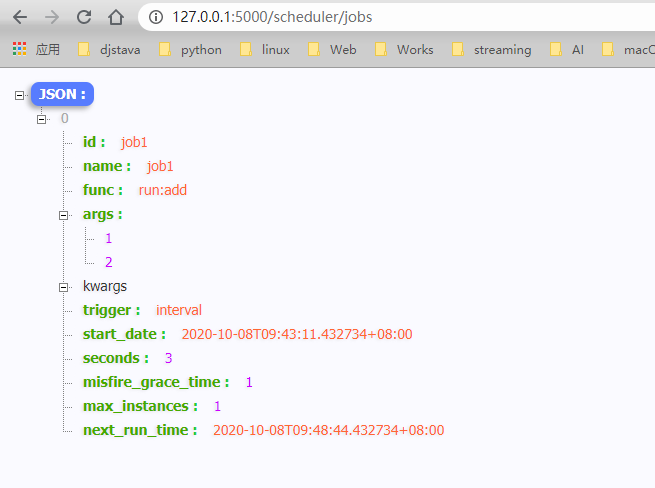
它们的使用方法是这样的,比如我要查看当前应用中的所有任务,可以访问使用GET方法访问 http://127.0.0.1:5000/scheduler/jobs
如果不习惯使用配置的话,还可以使用装饰器的方式,来看下面的示例
from flask import Flaskfrom flask_apscheduler import APSchedulerclass Config(object):SCHEDULER_API_ENABLED = Truescheduler = APScheduler()@scheduler.task('interval', id='do_job_1', seconds=30)def job1():print('Job 1 executed')# cron examples@scheduler.task('cron', id='do_job_2', minute='*')def job2():print('Job 2 executed')@scheduler.task('cron', id='do_job_3', week='*', day_of_week='sun')def job3():print('Job 3 executed')if __name__ == '__main__':app = Flask(__name__)app.config.from_object(Config())scheduler.init_app(app)scheduler.start()app.run()
最后再来看个复杂点的配置
class Config(object):JOBS = [{'id': 'job1','func': 'run:job1','args': (1, 2),'trigger': 'interval','seconds': 10}]SCHEDULER_JOBSTORES = {'default': SQLAlchemyJobStore(url='sqlite://')}SCHEDULER_EXECUTORS = {'default': {'type': 'threadpool', 'max_workers': 20}}SCHEDULER_JOB_DEFAULTS = {'coalesce': False,'max_instances': 3}SCHEDULER_API_ENABLED = True
其中SCHEDULER_JOBSTORES指的就是作业存储器,我们把它存储到sqlite中。SCHEDULER_EXECUTORS指的是执行器的配置,使用的类型是threadpool线程池,且设置最大线程数为20。SCHEDULER_JOB_DEFAULTS是任务的一些配置,其中
- coalesce指的是当由于某种原因导致某个任务积攒了好多次没有实际运行(比如说系统挂了2分钟后恢复,比如
supervisor的进程监控工具,有一个任务是每分钟跑一次的,按道理说这2分钟内本来是计划要运行2次的,但实际没有执行),如果coalesce为True,下次这个任务被执行时,只会执行1次,也就是最后这次,如果为False,那么会执行2次 - max_instance就是说同一个任务同一时间最多有几个实例在跑
SCHEDULER_API_ENABLED指定是否开启API
除了上面的常用配置之外,还有一些
SCHEDULER_TIMEZONE # 配置时区SCHEDULER_API_PREFIX # 配置API路由前缀SCHEDULER_ENDPOINT_PREFIX # 配置API路由后缀SCHEDULER_ALLOWED_HOSTS # 配置访问白名单SCHEDULER_AUTH # 配置认证中心
在服务器上部署flask应用的时候,经常需要设置时区,否则会报错
class Config(object):SCHEDULER_TIMEZONE = 'Asia/Shanghai'
配置RESTful API路由的前缀和后缀
class Config(object):SCHEDULER_API_PREFIX ='/xugaoxiang'
那么访问所有任务的路由就会由原来的 http://127.0.0.1:5000/scheduler/jobs 变成 http://127.0.0.1:5000/xugaoxiang/jobs
如果需要设定只允许某些主机访问的话,可以设置白名单,如果是允许全部的话,也可以写上*
class Config(object):SCHEDULER_ALLOWED_HOSTS = ['xugaoxiang.com']
如果要添加认证的话,可以这样实现
from flask import Flaskfrom flask_apscheduler import APSchedulerfrom flask_apscheduler.auth import HTTPBasicAuthclass Config(object):JOBS = [{'id': 'job1','func': 'run2:add','args': (1, 2),'trigger': 'interval','seconds': 3}]SCHEDULER_API_ENABLED = TrueSCHEDULER_AUTH = HTTPBasicAuth()def add(a, b):print(a+b)if __name__ == '__main__':app = Flask(__name__)app.config.from_object(Config())scheduler = APScheduler()# it is also possible to set the authentication directly# scheduler.auth = HTTPBasicAuth()scheduler.init_app(app)scheduler.start()@scheduler.authenticatedef authenticate(auth):return auth['username'] == 'guest' and auth['password'] == 'guest'app.run()
在访问scheduler之前,先做一次认证,如果满足条件,如上面通过http请求传递过来的参数username=guest且password=guest,就可以继续访问,否则拒绝访问。
源码下载
https://github.com/xugaoxiang/FlaskTutorial
Flask教程专题
更多Flask教程,请移步
https://xugaoxiang.com/category/python/flask/
参考资料

若有收获,就点个赞吧
0 人点赞
