转载自 http://miks.top/2018/01/25/%E7%B3%BB%E7%BB%9F%E7%BA%A7I-O%E5%8F%8ALinux-I-O%E6%A8%A1%E5%BC%8F%E8%A7%A3%E9%87%8A/
UNIX I/O
Linux中,所有的输入和输出都被当作对相应的文件的读和写来执行。这种将设备映射为文件的方式,允许Linux内核引出一个简单、低级的应用接口,称为Unix I/O:
- 打开文件:当应用程序通过要求内核打开相应的文件,来宣告它想要访问一个I/O设备时,内核会返回一个非负整数,叫做描述符(后面用fd代替),它在后续对此文件的所有操作中标识这个文件。
- Linux shell创建每个进程开始时都有三个打开的文件,标准输入(fd为0),标准输出(fd为1),标准错误(fd为2)。
- 改变当前的文件位置:对于每个打开的文件,内核保持一个文件位置k,初始为0,这个文件位置是从文件开头起始的字节偏移量,应用程序能够通过执行seek操作,显式地设置文件的当前位置k。
- 读写文件:一个读操作就是从文件复制n > 0个字节到内存,从当前文件位置k开始,然后将k增加到k + n。给定一个大小为m字节的文件,当k >= m时执行读操作会触发一个称为end-of-file(EOF)的条件。类似的,写操作就是从内存复制n>0个字节到一个文件,从当前文件位置k开始,然后更新k。
- 关闭文件: 当应用完成了对文件的访问之后,它就通知内核,关闭这个文件。作为响应,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池。
共享文件
可以用许多不同的方式来共享Linux文件,但是内核用三个相关的数据结构来表示打开的文件。
- 描述符表:每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。每个打开的描述符表项指向文件表中的一个表项。
- 文件表:打开文件的集合是由一张文件表来表示的,所有的进程共享这张表。每个文件表的表项组成(针对我们的目的)包括当前的文件位置、引用计数,以及一个指向v-node表中对应表项的指针。内核会在引用计数为零时,删除对应表项。
- v-node表:同文件表一样,所有的进程共享这张v-node表。每个表项包含stat结构中的大多数信息(文件的元数据,比如大小,创建时间)。
标准 I/O
C语言定义了一组高级输入输出函数,称为标准I/O库,为程序员提供了Unix I/O的较高级别的替代。这个库提供了打开和关闭文件的函数(fopen和fclose)、读和写字节的函数(fread和fwrite)、读和写字符串的函数(fgets和fputs),以及复杂的格式化的I/O函数(scanf和printf)。标准的I/O库将一个打开的文件模型化为一个流。对程序员而言,一个流就是一个指向FILE类型的结构的指针。
类型为FILE的流是对文件描述符和流缓冲区的抽象。
流缓冲区的目的是:使开销较高的Linux I/O系统调用的数量尽可能的小。例如,假设我们有一个程序,它反复调用标准I/O的getc函数,每次调用返回文件的下个字符。当第一次调用getc时,库通过调用一次read函数来填满流缓冲区,然后将缓冲区中的第一个字节返回给应用程序。只要缓冲区还有未读的字节,接下来对getc的调用就能直接从流缓冲区得到服务。
虽然以上是通过C语言的标准I/O函数来讲解的,但是从概念上理解,与别的编程语言也是相通的。
I/O的模式
理解了I/O的基本概念后,接下来我们来谈论关于I/O不同模式的概念,优缺点以及它们彼此间的相同与不同点。
阻塞I/O(Blocking I/O):
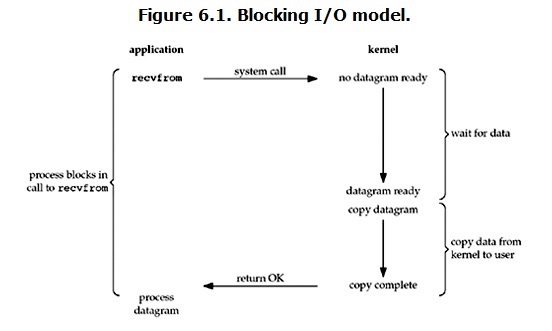
默认情况下,所有Linux中套接字都是阻塞的。
怎么理解?先理解这么个流程,一个输入操作通常包括两个不同阶段:
(1)等待数据准备好;
(2)从内核向进程复制数据。
当用户进程调用了recvfrom操作时,kernel就开始准备数据了。这是需要等待的,也就是说数据被拷贝到操作系统内的流缓冲区是需要一个过程的,而此时在用户进程的角度,就是被阻塞了。等到数据被准备好时,将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程此时解除阻塞状态。
非阻塞I/O(Non-blocking I/O):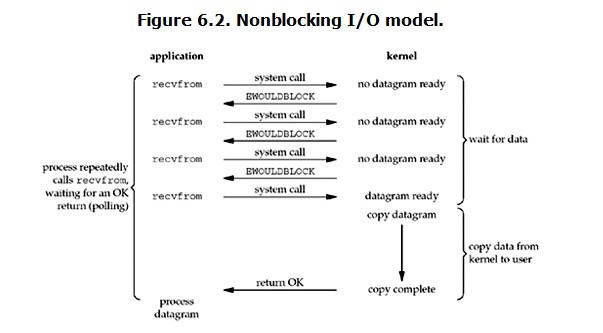
当用户发起非阻塞I/O操作时,如果数据还没有从kernel拷贝到用户内存中,那么kernel会立即返回一个error的信号,而用户进程得到这个信号后,就理解了此时数据还在等待中,之后会立即重新发送一个recvfrom的请求,直到数据被拷贝到用户内存中并且得到一个正确的返回。
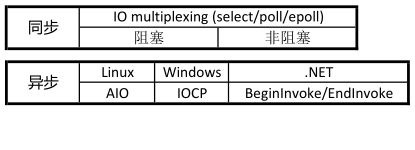
I/O多路复用(I/O multiplexing):
- select
- poll
- epoll
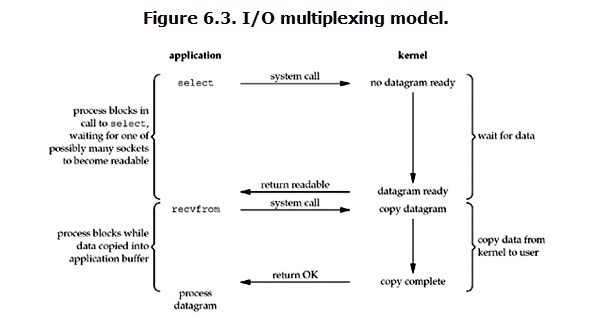
I/O多路复用也是并发的一种手段,基本思想就是使用select函数,要求内核挂起进程,只有在一个或者多个I/O时间发生后,才将控制返回给应用程序,比如:当集合{0,5}中任意描述符准备好读时返回。要注意使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
异步I/O(asynchronous I/O):
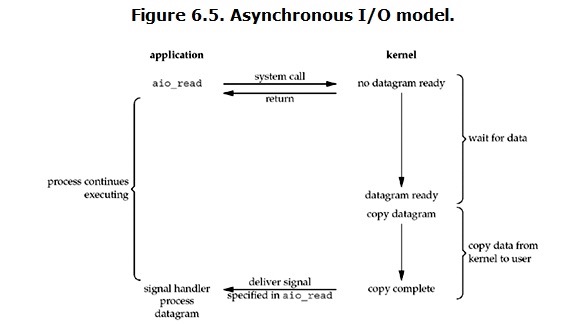
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,
首先它会立刻返回,所以不会对用户进程产生任何block。
然后,kernel会等待数据准备完成,
然后将数据拷贝到用户内存,
当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
阻塞和非阻塞的区别
- 调用阻塞I/O会一直阻塞住对应的进程直到操作完成,
- 非阻塞I/O在kernel还准备数据的情况下会立刻返回。
同步I/O和异步I/O的区别
- 同步I/O:导致请求进程阻塞,直到I/O操作完成。
- 异步I/O:不导致请求进程阻塞。
可能有人看完上图后,会很疑惑为啥非阻塞I/O也属于同步I/O了呢,它不是请求后直接返回了吗,尽管数据未准备好时它得到的error返回,那么也没有被阻塞啊。这里就是概念没有理解透彻导致的思想啦,其实不仅是kernel数据等待会阻塞进程,把kernel中的数据拷贝到用户内存中,也同样是阻塞用户进程的,你可以再仔细看一下上面I/O模式的介绍图,它是在两个过程结束后才返回OK的。所以非阻塞I/O也定义为同步I/O.
而异步I/O则不一样,当进程发起I/O操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说I/O完成。在这整个过程中,进程完全没有被阻塞。而这个过程就如同Python中的async/await一样。
各个I/O模式的对比

通过上面图片,可以发现非阻塞I/O和异步I/O的区别还是很明显的。
在非阻塞I/O中,虽然进程大部分时间都不会被阻塞,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。
而异步I/O则完全不同。它就像是用户进程将整个I/O操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
参考
《深入理解计算机系统》第三版,第十章。
Linux I/O模式
怎样理解阻塞非阻塞与同步异步的区别
最后
本文没有用任何代码,希望先用文字将这些概念梳理清楚。对于I/O复用,以及系统级别的并发,会在后面用实际的代码来提供完整的参考与理解。

若有收获,就点个赞吧
0 人点赞
