引用 https://lotabout.me/2017/understand-python-asyncio/
协程 coroutine 几乎是python里最为复杂的特性之一了。这篇文章我们来说一说 asyncio 的内部实现机制,借此来理解一门语言要支持协程需要做的工具。
本文需要提交了解 python 的 yield from 语法,不了解的话, 可以看看之前关于 Generator 的文章 ;另外,最好对 future/promise的概念有一定了解。文中不会介绍如何使用 asyncio及协程,并且文中给出的代码不一定能实现运行(不然代码里太大)
多线程与协程
cpu的执行是顺序的,线程是操作系统提供的一种机制,允许我们在操作系统的层面上实现“并行”。而协程则可以认为是应用程序提供的一种机制(用户或者库来完成),允许我们在应用程序的层面(用户空间)层面上实现“并行”
由于本质上程序是顺序执行的,要实现这种并行的假象,我们需要一种机制,来暂停当前的执行流,并在之后恢复之前的执行流。
这在OS及多线程/多进程中称为“上下文切换(context switch)”。其中“上下文”记录了某个线程执行的状态,包括线程里用到的各个变量,线程的调用栈等。而“切换”指的就是保存某个线程当前的运行状态,之后再从之前的状态中恢复。只不过线程相关的工作是由OS来完成,而协程则是由应用程序自己来完成。
与线程不同的是,协程完成的功能通常较小,所以会有需求将不同的协程串起来,我们暂时称它为协程链(coroutine chain)。
那么,与线程类似,要实现一个协程的库,我们需要这几样东西:
- 事件循环 event loop。 一一方面,它类似于 cpu,顺序执行协程的代码;另一方面,它相当于OS,完成协程的调用,即一个协程“暂停”时,决定接下来执行哪个协程。
- 上下文的表示。在python中, 我们使用python本身支持的生成器 Generator 来代表基本的上下文,但协程链是如何工作的呢?
- 上下文的切换。最基础的切换也是通过 python 生成器的 yield 加强版本语法来完成的。但我们还要考虑协程链的情况。
event loop
首先,因为协程是一种能暂停的函数,那么它暂停是为了什么?
一般是等待某个事件,比如说
- 某个连接建立了;
- 某个socket接收到数据了;
- 某个计时器归零了等。
而这些事件应用程序只能通过轮询的方式得知是否完成,但是OS(所有现代OS)可以提供一些中断的方式通知应用程序,如 select, epoll, kqueue 等。
那么有了OS的支持,我们就可以手写这样的循环(伪代码)
while True:happend = pool_events(events_to_listen, timeout)proces_events(happend)
第一个问题是:如何沆我们想监听的事件? 很简单,把事件加到 events_to_listen 里就可以了。
第二个问题,可以监听什么事件? 由于 process_events 需要OS的支持,那么我们想监听的事件是需要 OS支持才行的,一般操作系统支持网络io的文件描述符 fle descriptor
接下来,当事件发生时,我们要指定做一些事,一般称为回调 callback。也就是说我们需要告诉 event loop 一个 事件:回调 的对应关系。现在我们把 event loop用类表示:
class EventLoop:def __init__(self):self.events_to_listen = []self.callbacks = {}self.timeout = Nonedef register_event(self, event, callback):self.events_to_listen.append(event)self.callbacks[event] = callbackdef unregister_event(self, event):self.events_to_listen.remove(event)del self.callbacks[event]def _process_events(self, events):for e in events:self.callbacks[e](e)def start_loop(self):while True:events_happend = poll_events(self.eents_to_listen, tiemout)self._process_events(events_happend)loop = EventLoop()loop.register_event(fd, callback)loop.start_loop()
register_event 用于注册 事件:回调 在关系, start_loop 用于开启事件循环。
现在,你不是想说,之前提到过事件也包括“某个计时器归零了”,但 poll_events 只支持网络io的文件描述符,计时器又要如何实现呢?
一般 poll_events 函数是支持timeout参数表示等待的时间,因此,可以修改 start_loop
def call_later(self, delay, callback):self.call_at(now() + delay, callback)def call_at(self, when, callback):self.timeout_callbacks[when] = callbackdef start_loop(self):while True:timeout = min(self.timeout_callbacks.keys()) - now()events_happend = poll_events(self.events_to_listen, timeout)if not empty(events_happend):self._process_events(events_happend)self._process_timeout_events()def _process_timeout_events(self):time_now = now()for time, callback in self.timeout_callbacks.iteritems():if time < time_now:callback()del self.timeout_callbacks[time]
这里 poll_events 之前,会云计算所有计时器事件最小需要等待的时间,这个时间内即使没有事件发生, poll_events 也会即同,便触发计时事件。 _process_timeout_events 函数的作用是对比当前的时间与计时器的目标执行时间,中如果目标执行时间已经到达,则执行相应的回调函数。
于是一个简单的event_loop就完成了。 可以看到,它是导上不操作的基础:
允许等待某个事件的发生并执行相应的操作。同时,它还是个简单的调试器,能顺序地捃地发生事件的回调函数。
callback vs promise vs await
好了,现在我们有了 eventloop,它允许我们为事件注册回调函数。现在假设我们要顺序调用几个api,用阻塞式编程如下:
result1 = api1()result2 = api2(result1)result3 = api3(result2)...
如何这几个api都是异步的,用 eventloop + callback 怎么实现?
# Implementation for apidef api1(callback):def callback_for_api1():result1 = some_calculation_1()event_loop.unregister_event(event1)return callback(result1)event_loop.register_event(event1, callback_for_api1)def api2(result, callback):def callback_for_api2():result2 = some_calculation_2(result)event_loop.unregister_event(event2)return callback(result2)event_loop.register_event(event2, callback_for_api2)...# Our codeglobal resultdef api1_callback(result1):def api2_callback(result2):def api3_callback(result3):global resultresult = some_calculation(result3)return api3(result2, api3_callback)return api2(result1, api2_callback)api1(api1_callback)
这里 api1 api2 的实现由于需要用 event loop 来注册注销某些事件,所以显得特别复杂,这里我们可以先忽略它们的实现,但是看最后一段“用户代码”是不是极其复杂?随着操作的复杂性增加,回调函数的嵌套会越变越深。如果你熟悉Javascript,你应该听过“callback hell”的大名。回调函数的方式为什么不好?最重要的就是它违反了我们写代码的直觉,我们都习惯顺序执行的代码。
例如上例中,我们期待的是 api1 先执行,我们再用它的结果做点什么,但采用回调的方式,我们就需要在写 api1 的回调时,就去思考我们想用它的结果做些什么操作。在这个例子里,我们需要调用 api2 及 api3,这些嵌套的思考又得一遍遍重复下去。最终代码非常难以理解。
因此 Javascript 提出了 Promise ,
所谓的 promise 像是一个占位符,它表示一个运算现在还未完成,但我保证它会做完的;你可以指定它完成的时候做些其它的事。
下面我们尝试用这个思路去做一些改进(Python 没有原生的 promise 支持):
class Promise():def __init__(self):passdef then(self, callback_that_return_promise):self._then = callback_that_return_promisedef set_result(self, result):return self._then(result)# Implementation for apidef api1():promise = Promise()def callback_for_api1():promise.set_result(some_calculation_1())event_loop.unregister_event(event1)event_loop.register_event(event1, callback_for_api1)return promisedef api2(result):promise = Promise()def callback_for_api2():promise.set_result((some_calculation_2(result))event_loop.unregister_event(event2)return callback(result2)return promise...# Our codeglobal resultpromise = api1().then(lambda result1: return api2(result1)).then(lambda result2: return api3(result3)).then(lambda result3: global result; result = result3)promise.wait_till_complete()
这里我们简单实现了一个我们自己的 Promise 类,当它的 set_result 方法被调用时,Promise 会去执行之前用 .then 注册的回调函数,该回调函数将执行另一些操作并返回一个新的 Promise。也因此,我们可以不断地调用 then 将不同的 Promise 组合起来。可以看到,现在我们的代码就是线性的了!
然而故事还没有结束,人们依旧不满于 Promise 的写法和用法,又提出了 async/await 的写法。在 Python 中,上面的代码用 async/await 重写如下
result1 = await api1()result2 = await api2(result1)result3 = await api3(result2)
是不是简单明了?它的效果和我们前几个例子是等价的,但它的写法与我们初开始的阻塞版本几乎一致。这样能把异步与同步的编码在结构上尽量统一起来。
这里我不禁想问,为什么大家没有一开始就想到 async/await 的方式呢?我的一个假设是 async/await 是需要语言本身的支持的,而写编译器/解释器的专家不一定有编写应用的丰富经验,是很可能从一开始就拒绝这样的修改的。因此程序员们只能自己用库的形式添加支持了。当然这纯粹是猜测,只想感叹下不同领域的隔阂。
总而言之,有了 event loop 我们就能通过回调函数来完成异步编程,但这种方式非常不友好,因此人们又提出了类似 Promise 的思想,让我们能顺序编写异步代码,最后通过语言对 async/await 的语法支持,异步与同步代码的结构就几乎达到统一。这种统一有很重要的意义,它使我们能以同步的思维去理解异步的代码而不受回调方式的代码结构的影响。
而这一切都是为了将不同的异步函数“链接”起来,只不过是 async/await 的方式最为方便。对比线程,操作系统是没有提供方式将不同的线程链接起来的,因此这种将不同的协程链接起来的工具是协程比线程好的一个方面
上下文切换(恢复控制流)
前面提到过,如果某个协程在等待某些资源,我们需要暂停它的执行,在 event loop 中注册这个事件,以便当事件发生的时候,能再次唤醒该协程的执行。
这里举一个 Python 官方文档 的例子:
import asyncioasync def compute(x, y):print("Compute %s + %s ..." % (x, y))await asyncio.sleep(1.0)return x + yasync def print_sum(x, y):result = await compute(x, y)print("%s + %s = %s" % (x, y, result))loop = asyncio.get_event_loop()loop.run_until_complete(print_sum(1, 2))loop.close()
上面代码的执行流程是
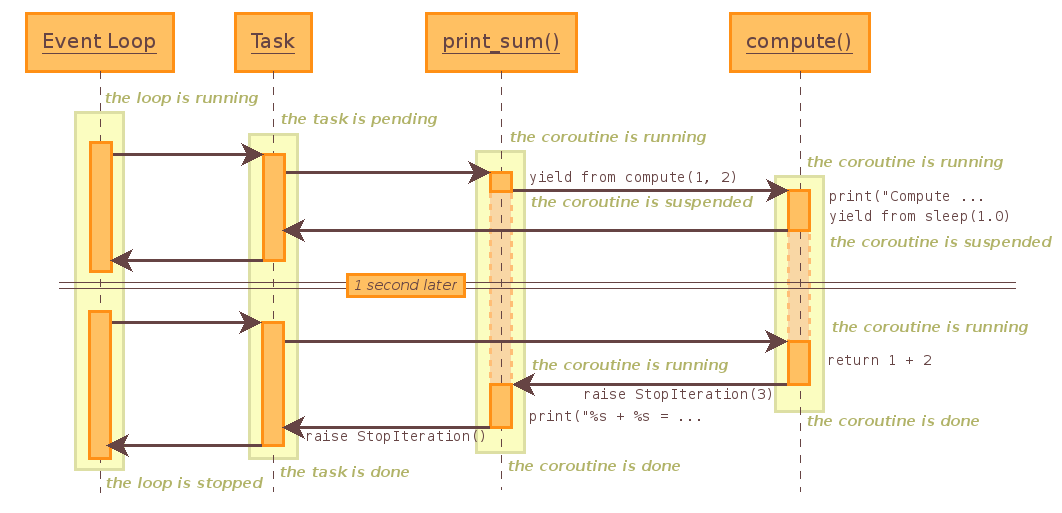
这里有两个问题:
- 谁向 event loop 注册了事件(及回调)?
- 程序从哪里恢复执行?
程序从 print_sum 开始执行,执行到 asyncio.sleep 时需要暂停,那么肯定是在 sleep 中向 event loop 注册了计时器事件。那们问题来了,当程序恢复执行时,它应该从哪里恢复呢?
从上面的流程图中,可以看见它是从 print_sum 开始恢复,但这样的话,sleep 注册事件时就需要知道是谁(即 print_sum)调用了它,这样才能在 callback 中指定从 print_sum 开始恢复执行!
但如果不是从 print_sum 恢复执行,那么一样的,从 sleep 恢复执行后,sleep 需要知道接下来返回到什么位置(即 compute 函数中的 await 位置), asyncio 又是如何做到这点的?
那么事实(代码实现)是怎样的呢?
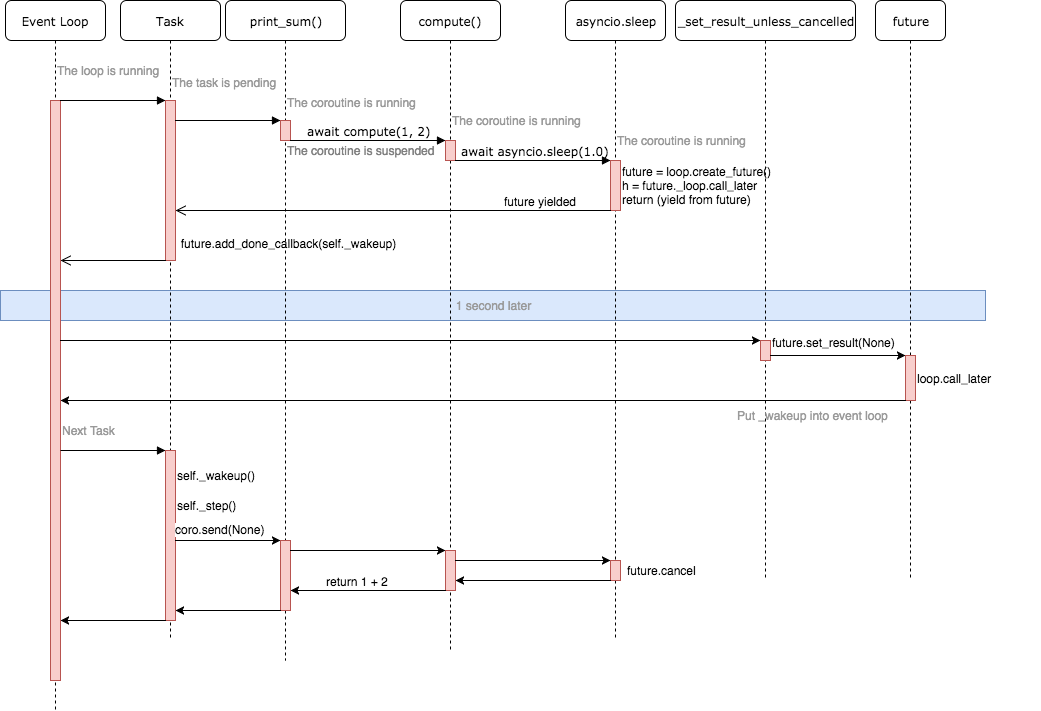
当我们把一个协程用 loop.run_until_complete (或其它相似方法)执行时, event loop 会把它包裹成一个 Task 。当协程开始执行或被唤醒时,Task 的 _step 方法会被调用,这里 它会调用 coro.send(None) 来执行/唤醒它包裹着的协程。
if exc is None:# We use the `send` method directly, because coroutines# don't have `__iter__` and `__next__` methods.result = coro.send(None)else:result = coro.throw(exc)
注意到这里将 coro.send 的结果赋值给了 result,那么它会返回什么呢?在我们这个例子中,协程链的最末尾是 asyncio.sleep,我们看看 它的实现:
@coroutinedef sleep(delay, result=None, *, loop=None):"""Coroutine that completes after a given time (in seconds)."""if delay == 0:yieldreturn resultif loop is None:loop = events.get_event_loop()future = loop.create_future()h = future._loop.call_later(delay,futures._set_result_unless_cancelled,future, result)try:return (yield from future)finally:h.cancel()
这里它创建了一个 future 并为它注册了事件(call_later),最终调用了 yield from future 返回。它代表什么呢?我们已经假设你明白 yield from 的使用方法,这代表 Python 会首先调用 future.__iter__ 函数,我们来看看它长什么样:
def __iter__(self):if not self.done():self._asyncio_future_blocking = Trueyield self # This tells Task to wait for completion.assert self.done(), "yield from wasn't used with future"return self.result() # May raise too.if compat.PY35:__await__ = __iter__ # make compatible with 'await' expression
注意这里的 yield self!也就是说 future 在第一次执行到这里时,会暂停执行并返回它自己,由于 coroutine 中使用的都是 yield from/await (它们在接收的参数上有区别,但在本文的讨论中没有区别),因此这个值会一直向上传递,到 Task._step 函数的 result = coro.send(None) 这里,那我们来看看 Task 对 result 做了什么,重要的是这一句:
| result.add_done_callback(self._wakeup) |
|---|
也就是说 task(print_sum) 得到了最内层暂停的 sleep 生成的 future 并为该 future 注册了一个回调,使得在 future.set_result 被调用时,task._wakeup 会被调用。这部分的逻辑可以看这里。
我们再回过头来看看 future.set_result 会在什么时候被调用,在 asyncio.sleep 函数里,我们为 event loop 注册了一个回调函数:
| h = future._loop.call_later(delay, futures._set_result_unless_cancelled, future, result) |
|---|
那么这个 _set_result_unless_cancelled 是这样的:
| def _set_result_unless_cancelled(fut, result): “””Helper setting the result only if the future was not cancelled.””” if fut.cancelled(): return fut.set_result(result) |
|---|
小结
那么 asyncio 做为一个库,做了什么,没做什么?
- 控制流的暂停与恢复,这是通过 Python 内部的 Generator(生成器)相关的功能实现的。
- 协程链,即把不同协程链链接在一起的机制。依旧是通过 Python 的内置支持,即 async/await,或者说是生成器的 yield from。
- Event Loop,这个是 asyncio 实现的。它决定了我们能对什么事件进行异步操作, 目前只支持定时器与网络 IO 的异步。
- 协程链的控制流恢复,即内部的协程暂停了,恢复时却需要从最外层的协程开始恢 复。这是 asyncio 实现的内容。
- 其它的库支持,这里指的是像
asyncio.sleep()这种协程链的最内层的协程,因此 我们一般不希望自己去调用 event loop 注册/注销事件。
因此,如果没有 asyncio,我们要实现相应的功能,主要的内容就是 Event Loop 及控制流的恢复,最后再加上一些好用的协程函数。
扩展阅读
- asyncio internals 关于 asyncio 内部的一些机制。

若有收获,就点个赞吧
0 人点赞
