1、暴力匹配
思想:逐一匹配
时间复杂度:
实现:
# -----------------------------------------# https://www.geeksforgeeks.org/naive-algorithm-for-pattern-searching/?ref=lbpdef find_brute_force(pat, txt):"""在txt中找到pat的匹配项,并返回txt匹配时第一个索引"""m, n = len(pat), len(txt)for begin in range(n - m + 1):match = 0while match < m:if txt[begin + match] != pat[match]:breakmatch += 1if match == m:print("Pattern found at index ", begin)txt = "AABAACAADAABAAABAA"pat = "AABA"find_brute_force(pat, txt)
优化匹配:
思想:当部分匹配时,则跳过部分匹配项
# -----------------------------------------# https://www.geeksforgeeks.org/optimized-naive-algorithm-for-pattern-searching/def opt_brute_force(pat, txt):m, n = len(pat), len(txt)begin = 0while begin <= n - m:for match in range(m):if txt[begin + match] != pat[match]:breakmatch += 1if match == m:print("Pattern found at index ", begin)begin += melif match == 0:begin += 1else:begin += matchopt_brute_force(pat, txt)
2、KMP算法
为了解决匹配字符串中含重复字符。
思想:当检测到不匹配时(在一些匹配之后),已经知道下一个窗口文本中的一些字符。利用这个信息来避免匹配无论如何都会匹配的字符。
时间复杂度:KMP匹配算法利用模式的退化特性(模式中相同的子模式出现多次),其将最坏情况复杂度提高到O(n)。
实现:
# -----------------------------------------# 参考:https://www.geeksforgeeks.org/kmp-algorithm-for-pattern-searching/?ref=lbpdef kmp(pat, txt):"""KMP算法对pat[]进行预处理,构造一个大小为m(与模式大小相同)的辅助lps[],用于匹配时跳过字符。Name LPS表示最长的合适前缀,也是后缀。正确的前缀是不允许带有整个字符串的前缀。"""m, n = len(pat), len(txt)# create lps[] that will hold the longest prefix suffix values for patternlps = [0] * m # lps[] that tells us the count of characters to be skipped.match = 0 # index for pat[]# Preprocess the pattern (calculate lps[] array)computeLPS(pat, m, lps)begin = 0 # index for txt[]while begin < n:if pat[match] == txt[begin]:begin += 1match += 1if match == m:print("Pattern found at index ", begin - match)match = lps[match - 1]# mismatch after j matcheselif begin < n and pat[match] != txt[begin]:# Do not match lps[0..lps[j-1]] characters,# they will match anywayif match != 0:match = lps[match - 1]else:begin += 1def computeLPS(pat, m, lps):"""Lps记录pat中每个字符在前面匹配的字符的位置;Lps [i]也可以定义为最长前缀,同时也是合适的后缀。需要正确地使用,以确保不考虑整个子字符串。"""prev = 0 # length of the previous longest prefix suffixlps[0] = 0 # lps[0] is always 0next = 1# the loop calculates lps[begin] for begin=1 to m-1while next < m:if pat[next] == pat[prev]:prev += 1lps[next] = prevnext += 1else:# This is tricky. Consider the example.# AAACAAAA and i = 7. The idea is similar# to search step.if prev != 0:prev = lps[prev - 1]# Also, note that we do not increment begin hereelse:lps[next] = 0next += 1txt = "ABABDABACDABABCABAB"pat = "ABABCABAB"kmp(pat, txt)
3、RK算法
思想:不直接逐位对比模式串pat和text是否相等,而是利用哈希算法,计算模式串和子串的哈希值,如果哈希值不相等,那么很明显字符串也不相等,如果相等,由于哈希算法可能会存在哈希冲突的可能,因此需要再使用朴素/暴力算法判断其是否真正相等。
时间复杂度: Rabin Karp算法的核心是,将哈希函数使用滚动哈希来计算,这样计算哈希的复杂度是O(1),整体的复杂度就变成了O(m)了。
哈希:不直接对比字符串的每个字符,而是比较其所代表的数字是否相等即可。
对于一个只有数字的字符串 要转换成十进制的数字,公式如下:
要转换成十进制的数字,公式如下:
在此基础上,往外延伸,如果对于一个只有小写英文字符的字符串来说,是不是可以当成26进制,然后计算出一个字符串所代表的数字:
比如对于一个字符串”abcd”,要计算一个长度为2的子串的子串的哈希,先计算”ab”的:
再计算”bc”的:
看一下这里的规律,在计算hash2时,完全可以复用hash1的值, 。
。
已知前一个子串的哈希值,计算后一个哈希值的过程,如下:
如果字符串过长,最后计算哈希可能会溢出。为了解决这个问题,在Rabin-Karp算法中,求哈希时,使用取余。
# https://www.geeksforgeeks.org/rabin-karp-algorithm-for-pattern-searching/?ref=lbp# d is the number of characters in the input alphabetd = 256# pat -> pattern# txt -> text# q -> A prime numberdef search(pat, txt, q):M = len(pat)N = len(txt)i = 0j = 0p = 0 # hash value for patternt = 0 # hash value for txth = 1# The value of h would be "pow(d, M-1)%q"for i in xrange(M-1):h = (h*d)%q# Calculate the hash value of pattern and first window# of textfor i in xrange(M):p = (d*p + ord(pat[i]))%qt = (d*t + ord(txt[i]))%q# Slide the pattern over text one by onefor i in xrange(N-M+1):# Check the hash values of current window of text and# pattern if the hash values match then only check# for characters on by oneif p==t:# Check for characters one by onefor j in xrange(M):if txt[i+j] != pat[j]:breakelse: j+=1# if p == t and pat[0...M-1] = txt[i, i+1, ...i+M-1]if j==M:print "Pattern found at index " + str(i)# Calculate hash value for next window of text: Remove# leading digit, add trailing digitif i < N-M:t = (d*(t-ord(txt[i])*h) + ord(txt[i+M]))%q# We might get negative values of t, converting it to# positiveif t < 0:t = t+q# Driver Codetxt = "GEEKS FOR GEEKS"pat = "GEEK"# A prime numberq = 101# Function Callsearch(pat,txt,q)
4、BM算法
BM算法定义了两个规则:
坏字符规则:当文本串中的某个字符跟模式串的某个字符不匹配时,称文本串中的这个失配字符为坏字符,此时模式串需要向右移动,移动的位数 = 坏字符在模式串中的位置 - 坏字符在模式串中最右出现的位置。此外,如果”坏字符”不包含在模式串之中,则最右出现位置为-1。
好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。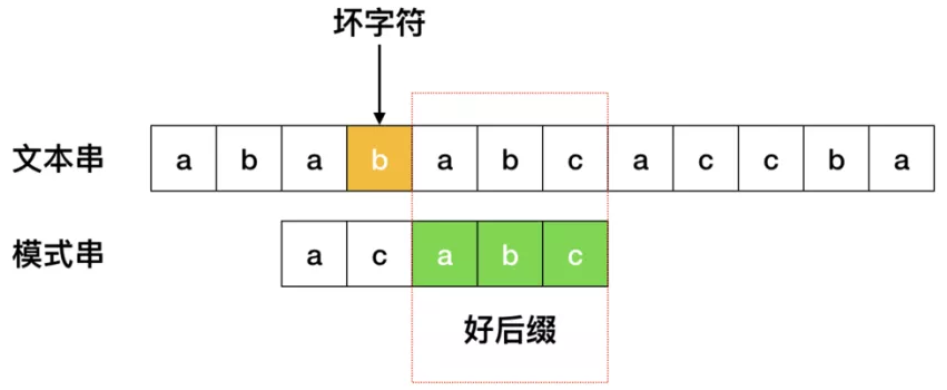
Boyer–Moore 算法在预处理时,将为两种不同的启发法结果创建不同的数组,分别称为 Bad-Character-Shift(or The Occurrence Shift)和 Good-Suffix-Shift(or Matching Shift)。
当进行字符匹配时,如果发现模式 P 中的字符与文本 T 中的字符不匹配时,将比较两种不同启发法所建议的移动位移长度,选择最大的一个值来对模式 P 的比较位置进行滑动。
4.1 坏字符规则
思想:
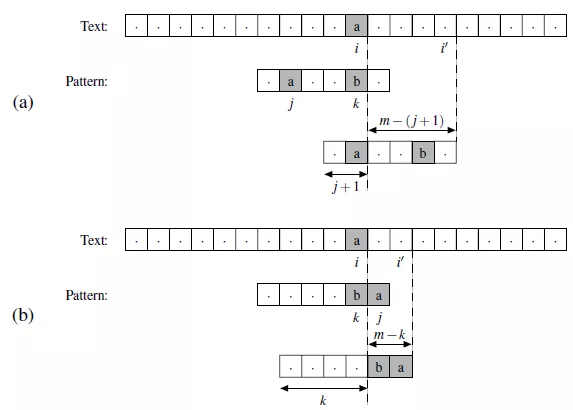
- 当T中的坏字符出现在 P的左侧时,位移为 m-(j+1),i表示坏字符在T中的索引,j表示坏字符在P中的索引,m表示P的长度,n表示T的长度
- 当T中的坏字符出现在 P的右侧时,位移为 m-k
- 当T中的坏字符不出现在 P中时,位移为 m。也就是将模式整体移过坏字符。
时间复杂度:在最坏的情况下,坏字符启发式可能需要 时间。最坏的情况是文本和模式中的所有字符都相同。例如:txt[] = “ AAAAAAAAAAAAAAAAAA “, pat[] = “ AAAAA “。
时间。最坏的情况是文本和模式中的所有字符都相同。例如:txt[] = “ AAAAAAAAAAAAAAAAAA “, pat[] = “ AAAAA “。
最好的情况下可能取 。最好的情况发生在所有的文字和图案都不同的时候。
。最好的情况发生在所有的文字和图案都不同的时候。
实现:
def find_boyer_moore(T, P):n, m = len(T), len(P)if m == 0: return 0 # 当查找的字符串为空时,返回0last = {} # 记录P中每个字母最后出现的位置for k in range(m):last[P[k]] = k# 第一次比较时,将P与T对其i = m - 1 # 第一次T被比较的位置,从后往前比较k = m - 1 # 第一次P被比较的位置,从后往前比较while i < n: # 当T中被比较的位置小于T的长度时if T[i] == P[k]: # 当字符匹配时if k == 0:print("pattern occurs at shift = %d" % i) # 当匹配到第一个字符且相等时,打印T的索引if i + m < n:shift = last.get(T[i + m], -1)if shift == -1:i += 2*m-1else:i += 2*m - shift-1k = m - 1else: # 当P有多个字符时i -= 1 # 向前一位比较k -= 1 # 向前一位比较else:j = last.get(T[i], -1) # 当两者不匹配时,在P中找到T[i]最后出现的位置i += m - min(k, j + 1) # T[i]移动m-min(k,j+1)位,移动位数取决于j大于还是小于ik = m - 1 # 重新匹配T = "ABAAAABAACD"P = "ABA"find_boyer_moore(T, P)
4.2 好后缀规则
思想:
- 如果模式串中存在已经匹配成功的好后缀,则把目标串与好后缀对齐,然后从模式串的最尾元素开始往前匹配。
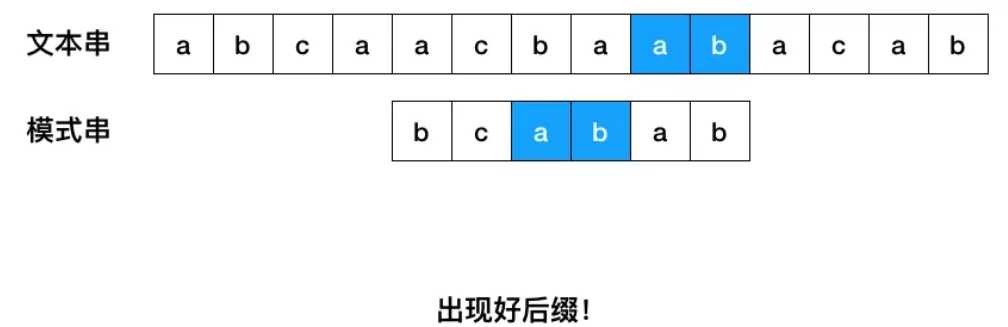
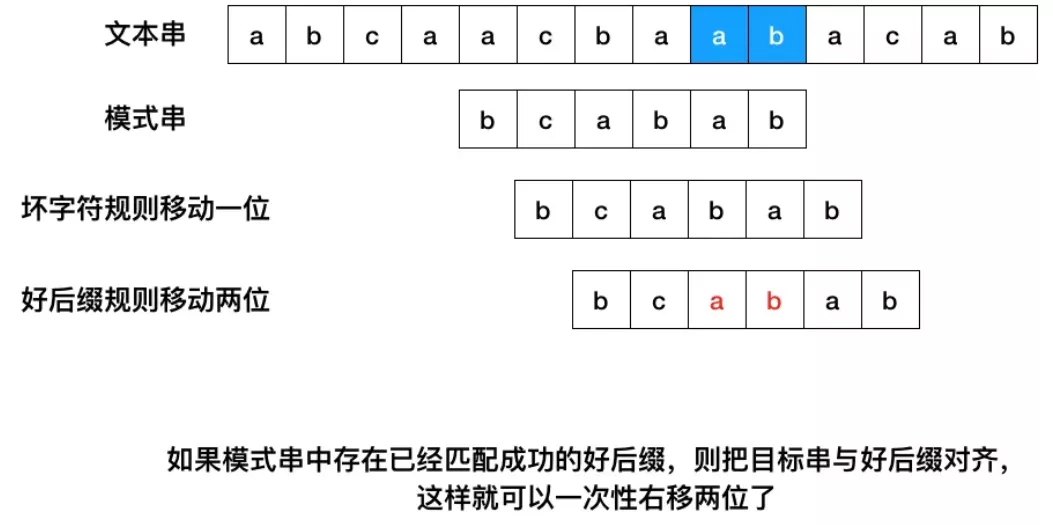
- 如果无法找到匹配好的后缀,找一个匹配的最长的前缀,让目标串与最长的前缀对齐(如果这个前缀存在的话)。模式串[m-s,m] = 模式串[0,s]
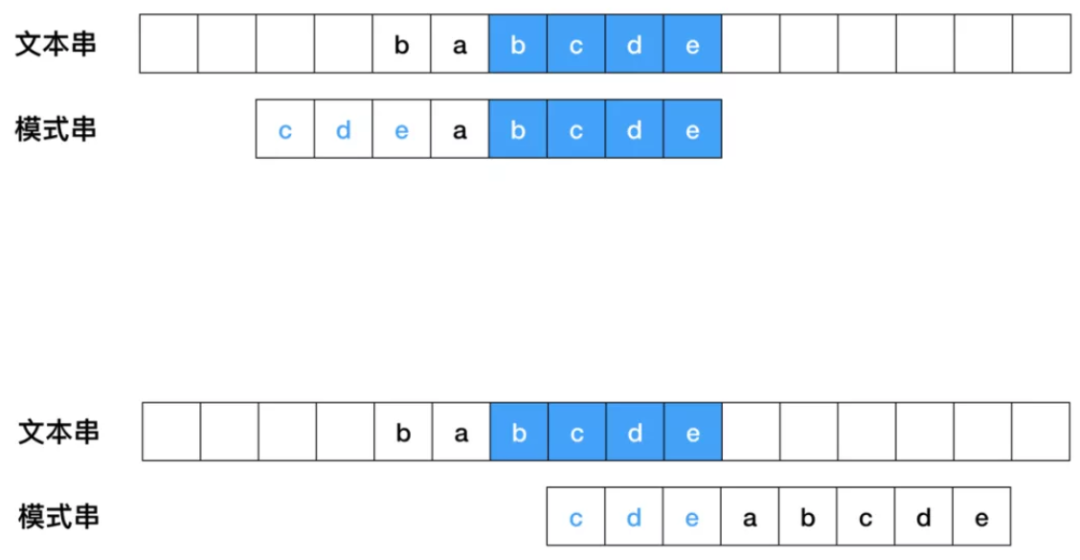
- 如果完全不存在和好后缀匹配的子串,则右移整个模式串。
实现:
"""好后缀的处理:1 首先引入边界的(border)的概念。边界是一个子字符串,它既是正确的后缀也是正确的前缀。例如,在字符串 “ccacc” 中,“c” 是一个边界,“cc” 是一个边界,因为它出现在字符串的两端,而 “cca” 不是一个边界。边界数组 bpos 用于记录 P 中索引为i包含的边界的起始索引。P的长度m,当索引为 m 时,bpos[m]表示的索引为 m+1,表示空字符移位位置由不能向左扩展的边界获得。考虑模式P = ABBABAB,m = 7:- 从位置 i = 5开始的后缀AB的最宽边界从位置 7 开始的,因此 bpos[5] = 7。- 在位置 i = 2 时,后缀是 BABAB。这个后缀的最宽边界是从位置4开始的BAB,因此 j = bpos[2] = 4。可以通过下面的例子来理解 bpos[i] = j2 对于后缀的最长字串处理对于每个后缀,确定该后缀所包含的整个模式的最宽边界。在下面的预处理算法中,这个值 bpos[0]最初存储在数组移位的所有空闲项中。但当模式的后缀比 bpos[0]短时,算法继续使用下一个更宽的模式边界,即 bpos[j]。"""def good_suffix(shift, bpos, pat, m):"""模式串中存在已经匹配成功的好后缀"""# m is the length of patterni = mj = m + 1bpos[i] = jwhile i > 0:"""if character at position i-1 is not equivalent to character at j-1,then continue searching to right of the pattern for border"""while j <= m and pat[i - 1] != pat[j - 1]:"""the character preceding the occurrence of t in pattern P is differentthan the mismatching character in P,we stop skipping the occurrencesand shift the pattern from i to j"""if shift[j] == 0: shift[j] = j - i# update the position of next borderj = bpos[j]"""p[i-1] matched with p[j-1], border is found.store the beginning position of border. """i -= 1j -= 1bpos[i] = jdef sub_suffix(shift, bpos, pat, m):"""无法找到匹配好的后缀,找一个匹配的最长的前缀"""j = bpos[0]for i in range(m + 1):''' set the border position of the first characterof the pattern to all indices in array shifthaving shift[i] = 0 '''if shift[i] == 0:shift[i] = j''' suffix becomes shorter than bpos[0],use the position of next widest borderas value of j '''if i == j:j = bpos[j]'''Search for a pattern in given text usingBoyer Moore algorithm with Good suffix rule '''def search(text, pat):# s is shift of the pattern with respect to texts = 0m = len(pat)n = len(text)bpos = [0] * (m + 1)# initialize all occurrence of shift to 0shift = [0] * (m + 1)# do preprocessinggood_suffix(shift, bpos, pat, m)sub_suffix(shift, bpos, pat, m)while s <= n - m:j = m - 1''' Keep reducing index j of pattern while characters ofpattern and text are matching at this shift s'''while j >= 0 and pat[j] == text[s + j]:j -= 1''' If the pattern is present at the current shift,then index j will become -1 after the above loop '''if j < 0:print("pattern occurs at shift = %d" % s)s += shift[0]else:'''pat[i] != pat[s+j] so shift the patternshift[j+1] times '''s += shift[j + 1]text = "ABAAAABAACD"pat = "ABA"search(text, pat)
5、总结
- 从前往后遍历,从前往后比较 BF、KMP,RK
- 从前往后遍历,从后往前比较 BM
- KMP解决pattern里有重复字串问题
- BM解决pattern和文本存在相同字串问题

若有收获,就点个赞吧
0 人点赞
