本文是 Goole DeepMind 发表在 ICLR 2016 上的一篇文章。由于 DQN 只能处理离散、低维的动作空间,作者在确定性策略梯度算法 DPG 和 Actor-Critic 算法 的基础上提出了基于策略梯度的深度确定性策略梯度算法 DDPG(Deep Deterministic Policy Gradient)。
摘要
我们将 Deep Q-Learning 成功的基础思想应用于连续动作领域,提出了一种基于确定性策略梯度的 actor-critic、model-free 算法,该算法可以在连续的动作空间中运行。 使用相同的学习算法,网络架构和超参数,我们的算法可以有力地解决20多个模拟物理任务,包括推车摆动、灵巧操纵、腿式运动和汽车驾驶等经典问题。 我们的算法能够找到性能与规划算法相比有竞争力的策略,并且可以完全访问域及其衍生物的动态。 我们进一步证明,对于许多任务,该算法可以“端到端”地学习策略:直接从原始像素输入。
背景
DQN 只能处理离散的、低维的动作空间。DQN不能直接处理连续的原因是它依赖于在每一次最优迭代中寻找动作值函数的最大值(表现为在 Q 神经网络中输出每个动作的值函数),针对连续动作空间 DQN 没有办法输出每个动作的动作值函数。
解决上述连续动作空间问题的一个简单方法是将动作空间离散化,但是动作空间是随着动作的自由度呈指数增长的(论文中举了一个机械臂的例子,自由度是指机械臂的关节,即使将每个关节的动作离散化 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图1](/uploads/projects/crazyalltnt@rl-paper/c2abd27ed47b592151106e1c84bfaf39.svg) 、自由度为
、自由度为 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图2](/uploads/projects/crazyalltnt@rl-paper/4c2a995db346e13f014257b06e3db43f.svg) ,
,![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图3](/uploads/projects/crazyalltnt@rl-paper/df59c3accb6c74ef6e2f65a4d4ae22cb.svg) 这个数字也是很大的),所以针对大部分任务来说这个方法是不现实的。
这个数字也是很大的),所以针对大部分任务来说这个方法是不现实的。
David Sliver 在 2014 年提出 DPG(Deterministic Policy Gradient)。在这篇论文中提出了确定性的策略搜索,而之前的研究普遍是认为策略动作满足某个分布(比较常用的是高斯分布)。相关概念:确定性策略是指某个状态执行的动作是一定的;随机性策略是指在某个状态得到的是执行动作的概率,可能执行不同的动作。将策略变为确定性的之后,动作-状态值函数 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图4](/uploads/projects/crazyalltnt@rl-paper/cca7c32e81534fd603a53fe43b643540.svg) 的 Bellman 方程由
的 Bellman 方程由![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图5](/uploads/projects/crazyalltnt@rl-paper/6e2155e084e8689ec93fc703b467c307.svg)
变为![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图6](/uploads/projects/crazyalltnt@rl-paper/6f49ddf4d21ade3cea40ea96dea61295.svg)
因为是确定型策略,所以不用再针对策略 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图7](/uploads/projects/crazyalltnt@rl-paper/97b88fe375f2280ca7da8d89c300259b.svg) 求期望;于是内部期望的求解就被避免,外部期望只需根据环境求期望即可。也就是说动作-状态值函数
求期望;于是内部期望的求解就被避免,外部期望只需根据环境求期望即可。也就是说动作-状态值函数 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图8](/uploads/projects/crazyalltnt@rl-paper/ca6dee2fa998e9511e51b1afc45bae40.svg) 只和环境有关系,也就意味着外面可以使用 off-policy 来更新值函数,比如使用 Q-learning 方法等。
只和环境有关系,也就意味着外面可以使用 off-policy 来更新值函数,比如使用 Q-learning 方法等。
Q-learning 是一种常用的 off-policy 算法,它使用贪婪策略。我们考虑由 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图9](/uploads/projects/crazyalltnt@rl-paper/ef744ea8de6dd5b9b077ed84b432120e.svg) 参数化的函数近似,通过使损失函数最小化来对其进行优化:
参数化的函数近似,通过使损失函数最小化来对其进行优化:![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图10](/uploads/projects/crazyalltnt@rl-paper/c9abaf6c4436a1b5cc59d387ca0208d2.svg)
其中:![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图11](/uploads/projects/crazyalltnt@rl-paper/c251ca2d09d023c78c007e86a3fca9be.svg)
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图12](/uploads/projects/crazyalltnt@rl-paper/461152e2816e333b69babace9727b1a5.svg)
DDPG 算法
使用神经网络进行强化学习时的一个挑战是,大多数优化算法都假定样本是独立且均匀分布的,显然,当在环境中通过顺序探索生成样本时,该假设不再成立。DDPG 算法借鉴了 DQN 算法的 memory replay 和 target network 机制,其中 memory replay 机制可以减少样本相关性,target network 机制可以使参数更新时 Q 目标值固定,让训练过程保持稳定和收敛趋势。由于在连续动作空间无法简单、快速地实现 Q-learning 的贪婪策略,所以使用的是基于确定动作策略的 actor-critic 算法框架。并且在 actor 部分采用 DPG 的确定性策略方式。
DDPG有 4 个网络,分别是 actor 当前网络、actor 目标网络、critic 当前网络、critic 目标网络:
- actor当前网络:负责策略网络参数θθ的迭代更新,负责根据当前状态
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图13](/uploads/projects/crazyalltnt@rl-paper/e6a7941a477a836213f7f4954ae6b533.svg) 选择当前动作
选择当前动作 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图14](/uploads/projects/crazyalltnt@rl-paper/07b9dfceec657fff61a9b7cb748f48cd.svg) ,用于和环境交互生成
,用于和环境交互生成![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图15](/uploads/projects/crazyalltnt@rl-paper/c633977d4f85df73f5d8233c5c37e45c.svg) 和
和![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图16](/uploads/projects/crazyalltnt@rl-paper/8e4797d48240b52820ab684c09685684.svg) 。
。 - actor 目标网络:负责根据经验回放池中采样的下一状态
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图17](/uploads/projects/crazyalltnt@rl-paper/9a39a3309ade5120e2fa2a8d85119feb.svg) 选择最优下一动作
选择最优下一动作 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图18](/uploads/projects/crazyalltnt@rl-paper/c3eeecc9963381e501fc36efe1f1d835.svg) 。网络参数
。网络参数 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图19](/uploads/projects/crazyalltnt@rl-paper/bcf033f520954820253514564b426c9a.svg) 定期从
定期从 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图20](/uploads/projects/crazyalltnt@rl-paper/367725ebd74d0c87953ffcb40b453510.svg) 复制。
复制。 - critic 当前网络:负责价值网络参数
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图21](/uploads/projects/crazyalltnt@rl-paper/e22985b34b2da4d5a9fe80a384cbf3a1.svg) 的迭代更新,负责计算负责计算当前 Q 值
的迭代更新,负责计算负责计算当前 Q 值 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图22](/uploads/projects/crazyalltnt@rl-paper/577a43234722d502e596f7630f17d52b.svg) 。目标 Q 值
。目标 Q 值 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图23](/uploads/projects/crazyalltnt@rl-paper/ef5d7d1c5ca6b4f701f8c6ad30e0c29c.svg)
- critic 目标网络:负责计算目标 Q 值中的
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图24](/uploads/projects/crazyalltnt@rl-paper/1c8a77f9a1fa26a64252656b5eb7bc97.svg) 部分。网络参数
部分。网络参数 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图25](/uploads/projects/crazyalltnt@rl-paper/a2c48892300855ae462189914ce73d70.svg) 定期从
定期从 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图26](/uploads/projects/crazyalltnt@rl-paper/c4330c6dec366db5448c596502a978a3.svg) 复制。
复制。
DDPG 从当前网络到目标网络的复制和我们之前讲到了 DQN 不一样。回想 DQN,我们是直接把将当前 Q 网络的参数复制到目标 Q 网络,即 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图27](/uploads/projects/crazyalltnt@rl-paper/9e2aa4096c3f976db5d7b24fbc78db53.svg) ,DDPG 这里没有使用这种硬更新,而是使用了软更新,即每次参数只更新一点点,即:
,DDPG 这里没有使用这种硬更新,而是使用了软更新,即每次参数只更新一点点,即:![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图28](/uploads/projects/crazyalltnt@rl-paper/58c1a5c6d36c6ad24f9ddff8f0a4a7c0.svg) 。这意味着目标值被限制为缓慢变化,大大提高了学习的稳定性。这种简单的变化使学习动作价值函数的相对不稳定的问题更接近监督学习的情况,这是一个存在稳健解决方案的问题。
。这意味着目标值被限制为缓慢变化,大大提高了学习的稳定性。这种简单的变化使学习动作价值函数的相对不稳定的问题更接近监督学习的情况,这是一个存在稳健解决方案的问题。
从低维特征向量观测中学习时,观测的不同组成部分可能具有不同的物理单位(例如,位置与速度),并且范围可能会随环境而变化。这可能会使网络难以有效学习,并且可能使得难以找到具有不同状态价值规模的环境中普遍存在的超参数。解决此问题的一种方法是手动缩放特征,使它们在不同环境和单位中处于相似范围内。作者通过使用批量归一化(batch normalization)技术,将小批量样本中的每个维度归一化以具有单位均值和方差。此外,它保持均值和方差的运行平均值,以在测试期间用于归一化(在文中的情况下,在探索或评估期间)。
在连续动作空间中学习的一个主要挑战是探索。 DDPG 等 off-policy 算法的一个优点是我们可以独立于学习算法来处理探索问题。本文通过将从噪声过程 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图29](/uploads/projects/crazyalltnt@rl-paper/0335cf2791355afe05d35d1f8651998a.svg) 采样的噪声添加到 actor 策略 来构建探索策略
采样的噪声添加到 actor 策略 来构建探索策略 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图30](/uploads/projects/crazyalltnt@rl-paper/2a51920aae257a7e7c79a9d38111076c.svg) :
:![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图31](/uploads/projects/crazyalltnt@rl-paper/20e0a4a6a3edcc3d90c2d13ae6fecbc2.svg)
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图32](/uploads/projects/crazyalltnt@rl-paper/7dd4ebf8d42d32a2cda0e25f6d021177.svg) 可以被选择以适应环境,本文使用 Ornstein-Uhlenbeck 过程来生成时间相关的探索,以提高惯性物理控制问题中的探索效率。
可以被选择以适应环境,本文使用 Ornstein-Uhlenbeck 过程来生成时间相关的探索,以提高惯性物理控制问题中的探索效率。
算法完整流程如下: :::info
:::info
- 随机初始化 critic 网络
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图34](/uploads/projects/crazyalltnt@rl-paper/fcf7a865ade81e35a770e2a4ae5d68af.svg) 和 actor 网络
和 actor 网络 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图35](/uploads/projects/crazyalltnt@rl-paper/47b3bce634a620573deda565503c8fcb.svg) 权重参数
权重参数 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图36](/uploads/projects/crazyalltnt@rl-paper/020d783b5f58ee0bed8705bac04a43a9.svg) 和
和 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图37](/uploads/projects/crazyalltnt@rl-paper/43346b1423698f5963389739888cf522.svg)
- 初始化 target 网络
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图38](/uploads/projects/crazyalltnt@rl-paper/270ce05ce6636b908bba802d8547bd04.svg) 和
和 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图39](/uploads/projects/crazyalltnt@rl-paper/7d5ad61c74d29cd3f04c34badac68e35.svg) 参数
参数 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图40](/uploads/projects/crazyalltnt@rl-paper/71ea30aee73d180234f91fef1bd605e3.svg) 和
和 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图41](/uploads/projects/crazyalltnt@rl-paper/2d03fd1fe9f1d27c4627ac3e66a5f579.svg)
- 初始化经验回放池
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图42](/uploads/projects/crazyalltnt@rl-paper/b80a770263f8e9e5a58081c9dad05b92.svg)
- 训练分成 M 个episode(即 M 场游戏),每个 episode 训练 T 次。
- 每一次新的 episode 都要初始化随机过程
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图43](/uploads/projects/crazyalltnt@rl-paper/f3acd9573157a1d1aae829038ce8ab77.svg) 作为动作探索空间
作为动作探索空间 - 初始化观测状态
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图44](/uploads/projects/crazyalltnt@rl-paper/774791253aef617c5ca883a9d14c5ff7.svg)
- 重复 T 个状态序列:
- 根基当前策略和探索噪声选择动作
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图45](/uploads/projects/crazyalltnt@rl-paper/d2c1cd6787f7316b29fe2e270c7292ae.svg)
- 执行动作
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图46](/uploads/projects/crazyalltnt@rl-paper/78dde9a9f887a6ff72f647e768dada33.svg) 并观察奖励
并观察奖励 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图47](/uploads/projects/crazyalltnt@rl-paper/1acb2a60e20bfffb087e6a406e9d734a.svg) 和新状态
和新状态 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图48](/uploads/projects/crazyalltnt@rl-paper/47204996ba1b9dc7bc0b3048eac6aef2.svg)
- 存储经验转移序列元组
![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图49](/uploads/projects/crazyalltnt@rl-paper/a240f1990c21ac1a2dbb38f822dc17ec.svg) 到经验池
到经验池 ![📝[DDPG]CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING - 图50](/uploads/projects/crazyalltnt@rl-paper/499b592b26abcc86f9225ca2002e88eb.svg)
- 从经验池随机采样 minibatch 的序列样本
- 为每一 minibatch 数据计算目标值
- 通过最小化 loss 更新 critic
- 使用策略梯度更新 actor 策略
- 每 C 步更新一次 target 网络
:::
实验结果
使用 MuJoCo 作为环境引擎,在所有任务中,使用低维状态描述(例如关节角度和位置)和环境的高维渲染进行实验。与 DQN 一样,为了使问题在高维环境中几乎完全可观察,作者使用了动作重复,即一个动作做N遍,然后把所有过程图片抽出来喂给网络可以简化问题,加速了训练过程。对于智能体的每个时间步,我们将模拟步进 3 个环境时间步,重复智能体的动作并每次渲染。因此,报告给智能体的观察包含 9 个特征图(3 个渲染中的每一个的 RGB),这允许智能体使用帧之间的差异来推断速度。帧被下采样到 64x64 像素,8 位 RGB 值被转换为缩放到 [0,1] 的浮点数。
- 根基当前策略和探索噪声选择动作
- 每一次新的 episode 都要初始化随机过程
作者展示了在八种实验环境中测试的结果
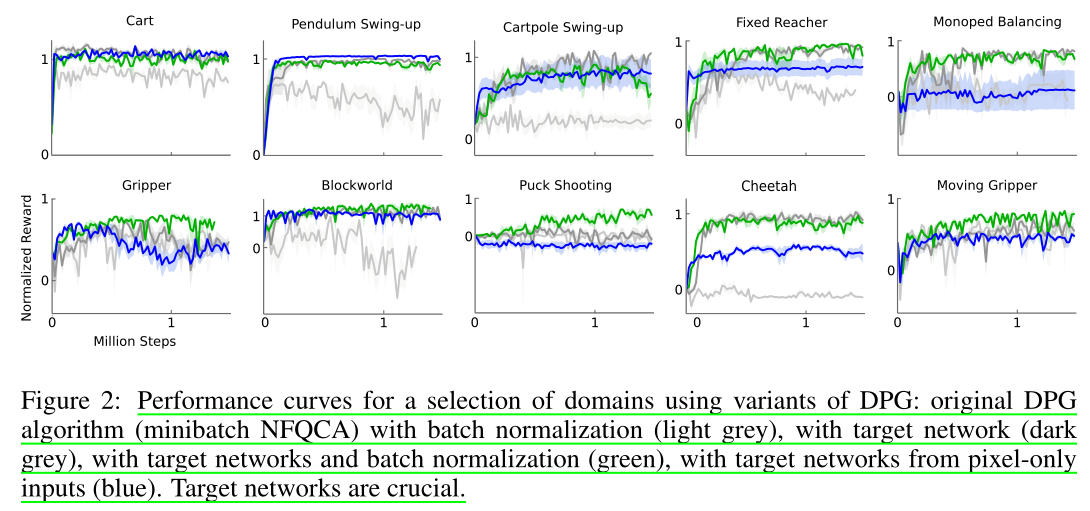
原始 DPG 算法(小批量 NFQCA)分别使用:批量归一化(浅灰色)、目标网络(深灰色)、目标网络和批量归一化(绿色)、输入仅来自像素的目标网络(蓝色)。根据上图可以看出目标网络至关重要。
与大多数强化学习算法一样,非线性函数逼近器的使用无法保证收敛,不过实验结果表明,DDPG 无需在环境之间进行任何修改即可稳定学习,并且所有的实验使用的经验步骤比 DQN 学习在 Atari 域中找到解决方案所使用的步骤要少得多。本文研究的几乎所有问题都在 250 万步(通常要少得多)的经验中得到解决,比 DQN 获得良好 Atari 解决方案所需的步骤少 20 倍。这表明,如果有更多的模拟时间,DDPG 可能解决比这里考虑的更困难的问题。
总结
- DDPG的提出动机其实是为了让DQN可以扩展到连续的动作空间。
- DDPG借鉴了 DQN 的两个技巧:经验回放和固定目标 Q 网络。
- DDPG使用策略网络直接输出确定性动作。
- DDPG使用了Actor-Critic 的架构。
DDPG 结合了深度学习和强化学习最新进展的方法,提出了一种新的算法,即使在使用原始像素进行观察时,该算法也能稳健地解决具有连续动作空间的各种领域中的挑战性问题。最值得注意的是,与大多数无模型强化方法一样,DDPG 需要大量训练集才能找到解决方案。然而,作者认为稳健的无模型方法可能是更大系统的重要组成部分,它可能会克服这些限制。
参考
About

若有收获,就点个赞吧
0 人点赞
