VDN是一种基于值函数的考虑协作任务的多智能体强化学习算法,即所有的智能体共享同一个奖励值(或者叫团队奖励)。
作为 QMIX 前身,对 VDN 算法的剖析应该有助于我们更加充分地理解QMIX算法。这样,我们也能够对这两种算法的优势和弊端有着更加全面的认识。
摘要
我们研究了在单一联合奖励信号下的协作多智能体强化学习问题。这类学习问题很困难,因为组合的动作和观测空间通常很大。在完全集中和分散的方法中,我们发现了虚假奖励的问题和一种现象,我们称之为“懒惰智能体”问题,它是由部分可观测性引起的。我们通过一个新的价值分解网络架构来训练单个智能体来解决这些问题,该架构学会了将团队价值函数分解成智能体的价值函数。我们在一系列部分可观察的多智能体领域中进行了实验评估,结果表明,学习这种价值分解可以得到更好的结果,特别是在与权重共享、角色信息和信息通道相结合的情况下。
背景
在合作式多智能体强化学习问题中,每个智能体基于自己的局部观测做出反应来选择动作,来最大化团队奖励。对于一些简单的合作式多智能体问题,可以用中心式(centralized)的方法来解决,将状态空间和动作空间做一个拼接,从而将问题转换成一个单智能体的问题。这会使得某些智能体在其中滥竽充数。
另一种极端方式式训练独立的智能体,每个智能体各玩各的,也不做通信,也不做配合,直接暴力出奇迹。这种方式对于每个智能体来说,其它智能体都是环境的一部分,那么这个环境是一个非平稳态的(non-stationary),理论上的收敛性是没法证明的。还有一些工作在对每个智能体都基于其观测设计一个奖励函数,而不是都用一个团队的团队奖励,这种方式的难点在于奖励函数的设计,因为设计的不好很容易使其陷入局部最优。
算法
VDN中提出一种通过反向传播将团队的奖励信号分解到各个智能体上的这样一种方式。其网络结构如下图所示: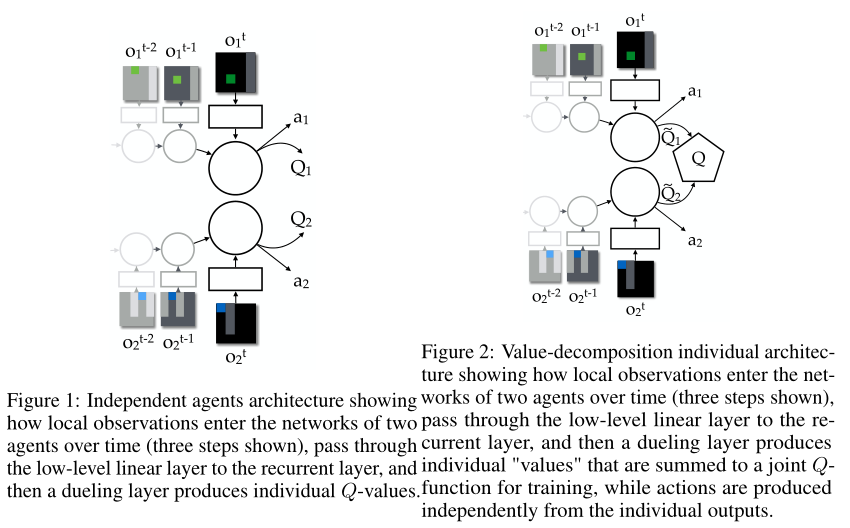
先看上图中的图 1,画的是两个独立的智能体,因为对每个智能体来说,观测都是部分可观测的,所以 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图2](/uploads/projects/crazyalltnt@rl-paper/471a28897468c3d10bdcdb9141fc04b3.svg) 函数是被定义成基于观测历史数据所得到的
函数是被定义成基于观测历史数据所得到的 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图3](/uploads/projects/crazyalltnt@rl-paper/eabe29e9c510b6d91002541e01667bb6.svg) ,实际操作的时候直接用 RNN 来做就可以。图 2 说的就是联合动作值函数由各个智能体的值函数累加得到的:
,实际操作的时候直接用 RNN 来做就可以。图 2 说的就是联合动作值函数由各个智能体的值函数累加得到的:![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图4](/uploads/projects/crazyalltnt@rl-paper/ae8a50f856d1f4fe997669c8310e14a0.svg)
其中 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图5](/uploads/projects/crazyalltnt@rl-paper/7cadca30f235c226ace9ee82e1d662b0.svg) 表示
表示 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图6](/uploads/projects/crazyalltnt@rl-paper/2a6ef716581a49a94b5b693fe2f18785.svg) 个智能体,
个智能体,![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图7](/uploads/projects/crazyalltnt@rl-paper/62527502ef292f0493211180666a0299.svg) 由每个智能体的局部观测信息得到,
由每个智能体的局部观测信息得到,![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图8](/uploads/projects/crazyalltnt@rl-paper/583c6bf234309517aac81c4cfcfe8775.svg) 是通过联合奖励信号反向传播到各个智能体的
是通过联合奖励信号反向传播到各个智能体的 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图9](/uploads/projects/crazyalltnt@rl-paper/a36923679519c31f3e78f720571b8aef.svg) 上进行更新的。这样各个智能体通过贪婪策略选取动作的话,也就会使得联合动作值函数最大。
上进行更新的。这样各个智能体通过贪婪策略选取动作的话,也就会使得联合动作值函数最大。
总结
总结来说:值分解网络旨在学习一个联合动作值函数 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图10](/uploads/projects/crazyalltnt@rl-paper/22211c6f98d0260b267597f2d9b012c6.svg) ,其中
,其中 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图11](/uploads/projects/crazyalltnt@rl-paper/6360344656a37464fb8d1131272971da.svg) 是一个联合动作-观测的历史轨迹,
是一个联合动作-观测的历史轨迹,![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图12](/uploads/projects/crazyalltnt@rl-paper/718da83e7b5a7fd7359fa98432205fcc.svg) 是一个联合动作。它是由每个智能体 a 独立计算其值函数
是一个联合动作。它是由每个智能体 a 独立计算其值函数 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图13](/uploads/projects/crazyalltnt@rl-paper/396bd51c6780df39a3272aea3a7b99ec.svg) ,之后累加求和得到的。其关系如下所示:
,之后累加求和得到的。其关系如下所示:![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图14](/uploads/projects/crazyalltnt@rl-paper/71cb6de3afc0853fee4ab71a78fbab13.svg)
严格意义上说 ![📝[VDN]Value-Decomposition Networks For Cooperative Multi-Agent Learning - 图15](/uploads/projects/crazyalltnt@rl-paper/bf009cd067cef36a42e3d1ef113116a2.svg) 称作值函数可能不太准确,因为它并没有严格估计期望回报。
称作值函数可能不太准确,因为它并没有严格估计期望回报。
值分解的独立的智能体网络结构可以参考下图所示: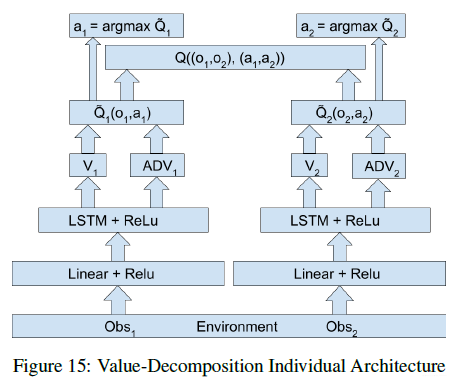
如果在此基础上在加上底层的通信的话可以表示为如下形式(其实就是将各个智能体的观测给到所有的智能体):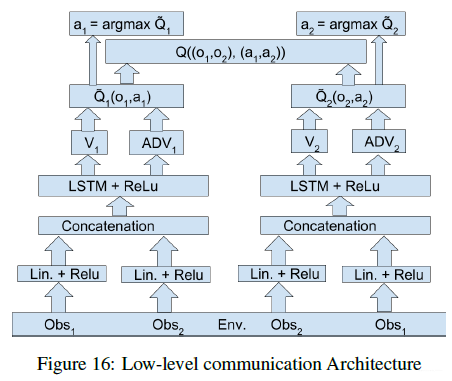
如果是在高层做通信的话可以得到如下形式: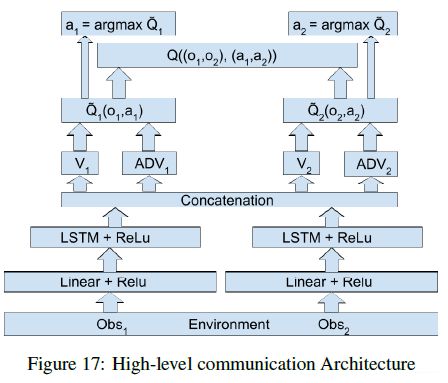
如果是在底层加上高层上都做通信的话可以得到如下形式: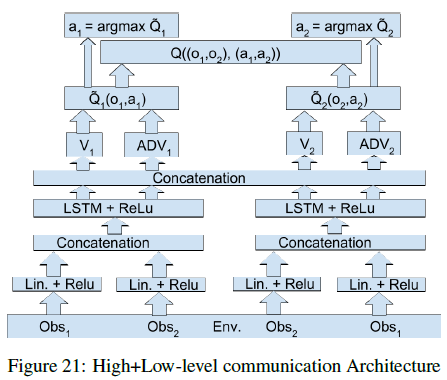
如果是集中式的结构的话,可以表示为如下形式: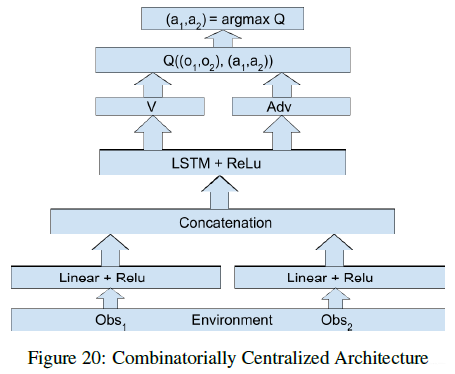
参考
- 多智能体强化学习(一) IQL、VDN、QMIX、QTRAN算法详解
- Qmix相关算法1:VDN笔记
- VDN算法解析: Value-Decomposition Networks For Cooperative Multi-Agent Learning
- Value-Decomposition Networks For Cooperative Multi-Agent Learning
- 阅读VDN:Value-Decomposition Networks For Cooperative Multi-Agent Learning Based On Team Reward
About

若有收获,就点个赞吧
0 人点赞
