本文是 ICML 2016 的最佳论文之一,出自 Google DeepMind。作者提出了一种新的网络架构,包含两个部分:一个用于估计 state-value 函数,一个用于估计状态相关的 action-advantage 函数。只要稍稍修改 DQN 中神经网络的结构, 就能大幅提升学习效果,加速收敛,这种新方法叫做 Dueling DQN。
摘要
近年来,在强化学习中使用深度学习的表示已经取得了许多成功。 尽管如此,许多这些应用仍使用常规体系结构,例如卷积网络,LSTM 或自动编码器。 在本文中,我们提出了一种新的神经网络体系结构,用于基于优势学习的无模型强化学习。 我们的 Dueling 架构表示两个独立的估计器:一个用于状态值函数,一个用于状态相关的动作优势函数。 这种分解的主要好处是可以在不对基础增强学习算法进行任何更改的情况下,将跨动作的学习普遍化。 我们的结果表明,在存在许多具有相似价值的操作的情况下,此体系结构可以更好地评估策略。 而且,Dueling 架构使我们的 RL 智能体能够胜过van Hasselt等人的最新 Double DQN 方法。(2015年)的 57 场 Atari 游戏中有 46 场。
背景
自从 DQN 的论文在 nature 发布之后,对 DQN 的研究的热潮一直在持续发酵,就其原因一方面在于它是把 deep learning 和 reinforcement learning 结合起来,开了从感知到决策的 end to end 的先河。另外一方面,DQN 还是有很多问题有待解决,比如在复杂的游戏中的表现、解决连续的动作空间等问题。这篇论文也是 DQN 算法的一个延续。
这篇作者结合 DQN 的特点,对网络结构进行创新。在很多应用场景,存在很多的状态不同的动作对应 Q 值几乎是一样的,如在 Atari 游戏 Enduro 中,如下图所示,由于前方没有车,所以不同的动作对 Q 值没有影响,在训练 DQN 时,当执行一个动作后我们会修正该动作对应的 Q 值,而其他的动作对应的 Q 值如何变化我们是不关心的, 但是若我们把 ![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图1](/uploads/projects/crazyalltnt@rl-paper/ca5aa2140b0f8d56bce976d7ed1cac7e.svg) 值分成
值分成 ![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图2](/uploads/projects/crazyalltnt@rl-paper/2c459c0b9dcf8be556c4c81061f88149.svg) 和
和 ![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图3](/uploads/projects/crazyalltnt@rl-paper/634f47da1760a0015e712544c3ffee96.svg) 来看待,同时训练了 V 和 A,那么对 V 部分的训练同样适用于别的动作,比如下图这个例子,我们随便执行一个动作,修正的 V 值同样也适用于别的动作,所以这样收敛更快。而下图的实验也证明了这一点,V 的输出注意力集中在远处的道路与当前的得分,因为这与该状态的得分有关,而 A 没有什么特别关注的地方,因为前方没有车,所以当前执行什么动作是不影响未来得分的。
来看待,同时训练了 V 和 A,那么对 V 部分的训练同样适用于别的动作,比如下图这个例子,我们随便执行一个动作,修正的 V 值同样也适用于别的动作,所以这样收敛更快。而下图的实验也证明了这一点,V 的输出注意力集中在远处的道路与当前的得分,因为这与该状态的得分有关,而 A 没有什么特别关注的地方,因为前方没有车,所以当前执行什么动作是不影响未来得分的。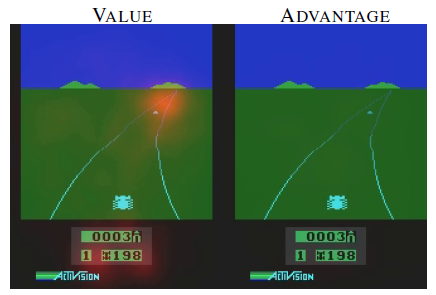
优势函数定义:![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图5](/uploads/projects/crazyalltnt@rl-paper/e83cc91c42b33ab61ebd215ab94f14c8.svg)
从上面这个公式来看 advantage 函数的意义:
- 值函数
![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图6](/uploads/projects/crazyalltnt@rl-paper/fd9cb6bb95dab7f943ca5f9d4818ac32.svg) 这个价值函数表明了某个状态的好坏程度。
这个价值函数表明了某个状态的好坏程度。 - 状态-动作值函数
![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图7](/uploads/projects/crazyalltnt@rl-paper/0ad0f089c4b277bb1d3336b44e4f463a.svg) 表明了这个状态下确定的某个动作的价值。
表明了这个状态下确定的某个动作的价值。 - 优势函数
![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图8](/uploads/projects/crazyalltnt@rl-paper/d6ae94ac701b3936bc9e3cf6e8af2acd.svg) 表明在这个状态下各个动作的相对好坏程度或重要程度;也就是说,不仅要知道动作是否好,还要知道动作好的程度。
表明在这个状态下各个动作的相对好坏程度或重要程度;也就是说,不仅要知道动作是否好,还要知道动作好的程度。
方法
图的第一部分就是传统的 DQN 算法的网络图。下面的图就是 Dueling DQN 的图。DQN 的输出就是 Q 函数的值(当然是动作空间的维度),它的前一层是全联接层。
而DuelingDQN 改变主要是这里,把全联接改成两条流,一条输出标量的关于状态的价值,另外一条输出关于动作的 Advantage 价值函数的值,就是绿色部分前面的两条流。最后这两个控制流通过一个特殊的聚合神经网络层(a special aggregating layer)得到 Q 函数的估计值。(因为输出是 Q 函数,所以能够和其他优化强化学习的训练方法相结合。)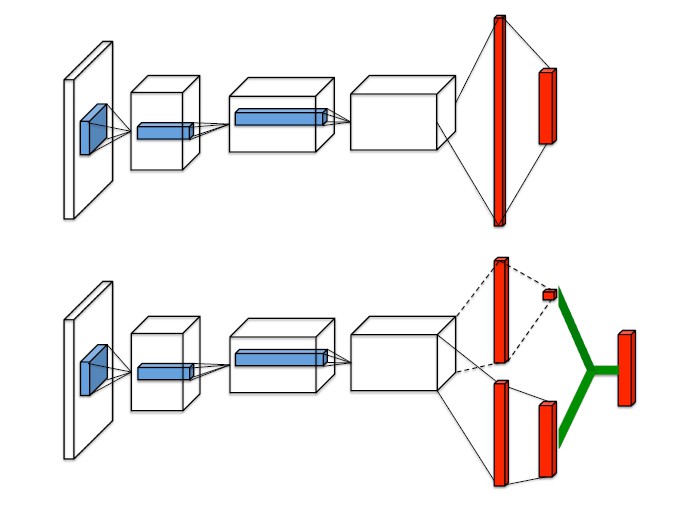
两个控制流分别输出 ![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图10](/uploads/projects/crazyalltnt@rl-paper/7dd428cf4ad9545a6ddef78bb9b4c8c2.svg) 和
和 ![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图11](/uploads/projects/crazyalltnt@rl-paper/2f273e59a375862718c74cf0cd54c5dd.svg) 。其中 θ 是卷积层的参数,α 、β 分别是两个控制流层的参数。然后 aggregating moudule(负责将两个控制流合并成 Q 函数的模块)定义为:
。其中 θ 是卷积层的参数,α 、β 分别是两个控制流层的参数。然后 aggregating moudule(负责将两个控制流合并成 Q 函数的模块)定义为:![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图12](/uploads/projects/crazyalltnt@rl-paper/61b8bae2af6e1d162897f0369912c4ab.svg)
此时出现一个 unidentifiable 问题:给定一个 Q,是无法得到唯一的 V 和 A 的。比如,V 和 A 分别加上和减去一个值能够得到同样的 Q,但反过来显然无法由 Q 得到唯一的 V 和 A。
文中讨论了两种组合方式
- 解决方法:
强制令所选择贪婪动作的优势函数为 0:![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图13](/uploads/projects/crazyalltnt@rl-paper/4e86633e219c797fc775f3c1b5abf807.svg)
则我们能得到唯一的值函数:![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图14](/uploads/projects/crazyalltnt@rl-paper/5dcbfe2d44e6f0a3b6ac5f67ecaf495c.svg)
- 解决方法的改进:
使用优势函数的平均值代替上述的最优值![📝[DuelingDQN]Dueling Network Architectures for Deep Reinforcement Learning - 图15](/uploads/projects/crazyalltnt@rl-paper/cf04fa08b87d509539ef69802a367439.svg)
这里的 A 其实已经不是理论中的 A 了,每个 A 减去所有 A 的均值才是真正理论中的 A,因为 A 的期望是等于 0 的。采用这种方法,虽然使得值函数 V 和优势函数 A 不再完美的表示值函数和优势函数(在语义上的表示),但是这种操作提高了稳定性。而且,并没有改变值函数 V 和优势函数 A 的本质表示。
由于该论文改了网络结构,在测试时还着重说了下 Gradient Clip 的重要性,对于提升也有比较大的帮助,文中的 gradient clipping norm 为 10。训练的方法和技巧其实是没有什么改变的,可以用 Double DQN,也可以用 Prioritized experience replay。
实验结果
前面已经介绍了一个简单的实验:
这个图展示了两个不同时间步骤的 the value and advantage saliency maps。在一个时间步骤上,the value network steam 注意到 the road,特别是 the horizon,因为这个地方出现了新的车辆。他也注意到 score。 the advantage stream 另一方面不关心视觉输入,因为当没有车辆出现时,你可以随意的选择 action,而对环境几乎没有影响。但是第二个图可以看出,the advantage stram 关注到一辆车的出现,使得做出的选择十分相关。
在实验当中,我们发现这个 dueling architecture 能够更快的做出正确的反应,选择出合适的 action,当策略评价冗余或者相似的 actions 被添加到学习过程中
为了证明 Dueling DQN 的效果,论文还做了另外两个实验。
第一个比较简单,在一个简单的实验环境中执行一个 policy evaluation task。文中是这么解释为什么做这个实验的:as it is devoid of confounding factors such as the choice of exploration strategy, and the interaction between policy improvement and policy evaluation。 这里的策略采用 ε-greedy 根据 Q 选取动作,ε 为 0.001。 使用 TD(0) 更新 Q 值,然后根据 Q 值选择动作,我的理解是这里同样用到了策略评估和策略升级,那么上边那句英文是什么意思呢? 不过不影响对这个实验的理解。
原有环境是5个动作,通过增加静止(no-ops)动作来增加总的动作数目,为了验证之前的思想:很多动作的 Q 值是差不多的,一个一个更新很慢,Dueling 通过更新 V 来同时更新所有动作的 Q 值来加快收敛。 实验结果如下图所示,纵坐标为Q值预测值与真实值的均方差,横坐标为迭代次数,也的确证明了可以加快收敛。
实验二就是在 atari 游戏中中达到了 SOTA 的效果,效果超过了之前的方法。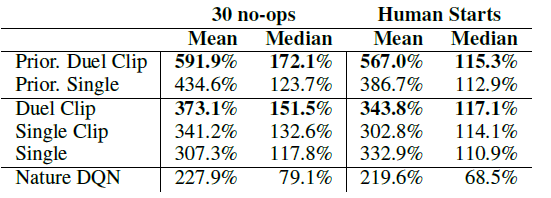
参考
- Dueling Network Architectures for Deep Reinforcement Learning 笔记
- 读论文Dueling Network Architectures for Deep Reinforcement Learning
- DuelingDQN《Dueling Network Architectures for Deep Reinforcement Learning》论文笔记、
- RL论文阅读【三】Dueling Network Architectures for Deep Reinforcement Learning
About

若有收获,就点个赞吧
0 人点赞
