本文是 Google DeepMind 于 2015 年 12 月提出的一篇解决 Q 值“过高估计(overestimate)”的文章,发表在顶级会议 AAAI 上,作者 Hado van Hasselt 在其 2010 年发表的 Double Q-learning 算法工作的基础上结合了 DQN 的思想,提出了本文的 state-of-the-art 的 Double DQN 算法。给出了过估计的通用原因解释和解决方法的数学证明,最后在 Atari 游戏上有超高的分数实验表现。
摘要
众所周知,流行的 Q-learning 算法在某些情况下会高估动作值。 这种高估在实践中是否常见,是否损害性能以及是否可以普遍防止,这在以前是未知的。 在本文中,我们肯定地回答所有这些问题。 特别是,我们首先表明,将 Q-learning 与深度神经网络相结合的最新 DQN 算法在 Atari 2600 域中的某些游戏中遭受了高估。 然后,我们证明了在表格式设置中引入的 Double Q-learning 算法背后的思想可以推广到大规模函数逼近。 我们提出了一种针对 DQN 算法的特殊适应方法,并表明重新生成算法不仅减少了假设的观察到的过高估计,而且还导致了几款游戏的更好性能。
背景
过估计问题现象
Q-learning 算法在低维状态下的成功以及 DQN 和 target DQN 的效果已经很好了,但是人们发现了一个问题就是之前的 Q-learning、DQN 算法都会过高估计(overestimate)Q 值。
:::info
本质上这个 overestimate 来源于下面这个公式:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图1](/uploads/projects/crazyalltnt@rl-paper/9b9ef23266439dcafe7cc942bf3729db.svg)
这个公式很好理解,对一系列数先求最大值再求平均,通常比先求平均再求最大值要大(或相等)。不理解的同学自己举个栗子。
在 dqn 里面,公式里面的 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图2](/uploads/projects/crazyalltnt@rl-paper/d40c45951cd92a8f5d22aa03b99de244.svg) 就相当于同一个
就相当于同一个 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图3](/uploads/projects/crazyalltnt@rl-paper/556c731a337673debd426507711482e0.svg) 在不同 sample data 下的 Q-value。 dqn 用 Bellman equation 去估计 Q-value:
在不同 sample data 下的 Q-value。 dqn 用 Bellman equation 去估计 Q-value:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图4](/uploads/projects/crazyalltnt@rl-paper/4eb31b234c60a3217ae4a45d1e2327d5.svg)
对于某个 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图5](/uploads/projects/crazyalltnt@rl-paper/76514a0b109d6c3fb9bc6c26635554c6.svg) ,在 sample 一些
,在 sample 一些 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图6](/uploads/projects/crazyalltnt@rl-paper/a69736d95cea18236e62d026fd5d3fa0.svg) 之后,用 gradient descent 去拟合 Q-function 的效果就相当于用
之后,用 gradient descent 去拟合 Q-function 的效果就相当于用 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图7](/uploads/projects/crazyalltnt@rl-paper/500f84cc4f928d7fd0b3c0a7aac3d492.svg) 的平均值去拟合 Q-function。这样就产生了类似于第一个公式的效应。
:::
的平均值去拟合 Q-function。这样就产生了类似于第一个公式的效应。
:::
一开始人们只是发现了这个事情但是并不知道这是否真的存在,以及就算存在会不会影响学习的性能,DeepMind 在 paper Deep Reinforcement Learning with Double Q-learning 中对这几个问题给了肯定的回答,并给出了一种简单有效的解决方案。
Deep Q Networks
Q-learning 拿到状态对应的所有动作 Q 值之后是直接选取 Q 值最大的那个动作,这会导致更加倾向于估计的值比真实的值要高。为了能够使得标准的 Q-learning 学习去大规模的问题,将其参数化 Q 值函数表示为:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图8](/uploads/projects/crazyalltnt@rl-paper/7cabb7fe57922ba105f9d3c1fd0cfb9e.svg)
其中 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图9](/uploads/projects/crazyalltnt@rl-paper/3d3485b8452c9e935bcca10f87c597a8.svg) 表示为:
表示为:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图10](/uploads/projects/crazyalltnt@rl-paper/5ad1b45e8c8383b7a2af07462c6b6b51.svg)
其实我们发现这个更新过程和梯度下降大同小异,此处均以更新参数 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图11](/uploads/projects/crazyalltnt@rl-paper/187d595907a8d806b847c48b6d620d72.svg) 进行学习。
进行学习。
DQN 算法非常重要的两个元素是“经验回放”和“目标网络”,通常情况下,DQN 算法更新是利用目标网络的参数 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图12](/uploads/projects/crazyalltnt@rl-paper/13421a19142d89a9451d3b06479e6685.svg) ,它每个
,它每个 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图13](/uploads/projects/crazyalltnt@rl-paper/585fb1838da19171952f4c7e4164cbf6.svg) 步更新一次,其数学表示为:
步更新一次,其数学表示为:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图14](/uploads/projects/crazyalltnt@rl-paper/77982530d036163a36687515b6319745.svg)
上述的标准的 Q-learning 和 DQN 中均使用了 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图15](/uploads/projects/crazyalltnt@rl-paper/5737aa366a2c75d3e90dcee8646e4986.svg) 操作,使得选择和评估一个动作值都会过高估计。
操作,使得选择和评估一个动作值都会过高估计。
Double Q-learning
DeepMind 并不是第一个发现这个问题的,早在 2010 年,Hasselt 就针对过高估计 Q 值的问题提出了 Double Q-learning,他们就是尝试通过将选择动作和评估动作分割开来避免过高估计的问题。
在原始的 Double Q-learning 算法里面,有两个价值函数,一个用来选择动作(当前状态的策略),一个用来评估当前状态的价值。这两个价值函数的参数分别记做 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图16](/uploads/projects/crazyalltnt@rl-paper/6637729702ffaf6571f64d3c6a08cc40.svg) 和
和 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图17](/uploads/projects/crazyalltnt@rl-paper/fe00c1794624326da1ade6786be972ea.svg) 。算法的思路如下:
。算法的思路如下:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图18](/uploads/projects/crazyalltnt@rl-paper/3dedd18fedde7541b9413774e25f73aa.svg)
通过对原始的 Q-learning 算法的改进,Double Q-learning 的误差表示为:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图19](/uploads/projects/crazyalltnt@rl-paper/137155bccbdc867d4bc48397b881adf0.svg)
此处意味着我们仍然使用贪心策略去学习估计 Q 值,而使用第二组权重参数 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图20](/uploads/projects/crazyalltnt@rl-paper/c85877a8caa9cb650f191ebb6996bb85.svg) 去评估其策略。
去评估其策略。
Q-learning 和 Double Q-learning 这两个公式只有最后一点点不同。在 Q-learning 中,我们按照当前网络的参数 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图21](/uploads/projects/crazyalltnt@rl-paper/f22dc662474752ecbaa58fd9f0e9bd16.svg) 来选择下一个动作并且用一样的参数来评估对应动作的 Q 值,但是在 Double Q-learning 中,我们用
来选择下一个动作并且用一样的参数来评估对应动作的 Q 值,但是在 Double Q-learning 中,我们用 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图22](/uploads/projects/crazyalltnt@rl-paper/823d8b2a64aa5f4d2cc96f7e8c2593ba.svg) 来决定下一个动作,但是用
来决定下一个动作,但是用 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图23](/uploads/projects/crazyalltnt@rl-paper/22bc41e4ef8bc27e84d897cacc2c748e.svg) 来估计这个动作的价值。在 Double Q-learning 中,这两组参数
来估计这个动作的价值。在 Double Q-learning 中,这两组参数 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图24](/uploads/projects/crazyalltnt@rl-paper/39df966f95d83f84e8d27a7f1234dd18.svg) 和
和 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图25](/uploads/projects/crazyalltnt@rl-paper/e3412896cadf55adaee0c7823430d4dd.svg) 通过定期的交换位置来对称的更新。
通过定期的交换位置来对称的更新。
估值误差导致过优化
证明
早在 1993 年,Thrun 和 Schwartz 就发现了 Q 值过高估计的问题了,但是他们认为出现这个现象的原因是不足够灵活的函数近似。2010 年 Hasselt 认为出现这个现象的原因是环境的噪声(noise)。为了弄清楚这个现象的具体原因,DeepMind 在这篇 paper 中给出了严格的证明,并且给出了一个定理(证明见论文的附录):
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图26](/uploads/projects/crazyalltnt@rl-paper/74d2a2865f7512282fc612be8ce046ba.png)
这个定理证明了任何类型的估值误差(estimation error)都会导致 Q 值增大,无论是环境噪声(environmental noise)、函数近似误差(function approximation)、非稳定性(non-stationarity)或是其他的任何原因造成的估值误差。
从定理的结论可以很容易发现学习到的估值会随着状态s对应动作数量的增大而降低下边界。![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图27](/uploads/projects/crazyalltnt@rl-paper/29fb93f4f570df0d17bac2a77ef8b4da.svg)
实验数据
下面这部分通过实验来直观的看出 Q-learning 的方式的估值真的会比真实值要大,并且 Double Q-learning 的估值就会好很多。
DeepMind 首先给出了一个有真实 Q 值的环境:假设 Q 值为 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图28](/uploads/projects/crazyalltnt@rl-paper/3ccf1af98e8bba97bc4a4a2309316f7a.svg) 以及
以及 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图29](/uploads/projects/crazyalltnt@rl-paper/36f1912c5d8f484f58abe8f07b9f3fa9.svg) ,然后尝试用 6 阶和 9 阶多项式拟合这两条曲线,一共进行了三组实验,参见下面表格:
,然后尝试用 6 阶和 9 阶多项式拟合这两条曲线,一共进行了三组实验,参见下面表格:
这个试验中设定有十个 action(分别记做 a1,a2,…,a10 ),并且 Q 值只与 state 有关。所以对于每个 state,每个 action 都应该有相同的 true value,他们的值可以通过目标 Q 值那一栏的公式计算出来。此外这个实验还有一个人为的设定是每个 action 都有两个相邻的 state 不采样,比如说 a1 不采样 -5 和 -4(这里把 -4 和 -5 看作是 state 的编号), a2 不采样 -4 和 -3 等。这样我们可以整理出一张参与采样的 action 与对应 state 的表格:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图31](/uploads/projects/crazyalltnt@rl-paper/f495079f7853f00c1e91c8ec28feeb38.png)
浅蓝色代表对应的格子有学习得到的估值,灰色代表这部分不采样,也没有对应的估值(类似于监督学习这部分没有对应的标记,所以无法学习到东西)。
这样实验过后得到的结果用下图展示:
从这里面可以看出很多东西:
- 最左边三幅图(对应 action2 那一列学到的估值)中紫色的线代表真实值(也就是目标 Q 值,通过 s 不同取值计算得出),绿色的线是通过 Q-learning 学习后得到的估值,其中绿点标记的是采样点,也就是说是通过这几个点的真实值进行学习的。结果显示前面两组的估值不准确,原因是我们有十一个值(
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图33](/uploads/projects/crazyalltnt@rl-paper/e3b816798b016b91bbaf0706f941afaf.svg) ),用 6 阶多项式没有办法完美拟合这些点。对于第三组实验,虽然能看出在采样的这十一个点中,我们的多项式拟合已经足够准确了,但是对于其他没有采样的点我们的误差甚至比六阶多项式对应的点还要大。
),用 6 阶多项式没有办法完美拟合这些点。对于第三组实验,虽然能看出在采样的这十一个点中,我们的多项式拟合已经足够准确了,但是对于其他没有采样的点我们的误差甚至比六阶多项式对应的点还要大。 - 中间的三张图画出了这十个动作学到的估值曲线(对应图中绿色的线条),并且用黑色虚线标记了这十根线中每个位置的最大值。结果可以发现这根黑色虚线几乎在所有的位置都比真实值要高。
- 右边的三幅图显示了中间图中黑色虚线和左边图中紫线的差值,并且将 Double Q-learning 实验的结果用同样的方式进行比较,结果发现 Double Q-learning 的方式实作的结果更加接近0。这证明了 Double Q-learning 确实能降低 Q-Learning 中过高估计的问题。
- 前面提到过有人认为过高估计的一个原因是不够灵活的 value function,但是从这个实验结果中可以看出,虽然说在采样的点上,value function 越灵活,Q 值越接近于真实值,但是对于没有采样的点,灵活的 value function 会导致更差的结果,在 RL 领域中,大家经常使用的是比较灵活的 value function,所以这一点的影响比较严重。
- 虽然有人认为对于一个 state,如果这个 state 对应的 action 的估值都均匀的升高了,还是不影响我们的决策啊,反正估值最高的那个动作还是最高,我们选择的动作依然是正确的。但是这个实验也证明了:不同状态,不同动作,相应的估值过高估计的程度也是不一样的,因此上面这种说法也并不正确。
Double DQN
通过以上的证明和拟合曲线实验表明,过高估计不仅真实存在,而且对实验的结果有很大的影响,为了解决问这个问题,在 Double Q-learning 的基础上作者提出了本文的 Double DQN 算法。下面给出 Double DQN 的 target 公式,并且与前面出现过的 Q-learning 和 Double Q-learning 公式进行对比:
- Q-learning:
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图34](/uploads/projects/crazyalltnt@rl-paper/41f136abd81f580487df4f39a56557d8.svg)
- Double Q-Learning:
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图35](/uploads/projects/crazyalltnt@rl-paper/8ad6f14e80b69a4ca4d907546b35e868.svg)
- Double DQN:
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图36](/uploads/projects/crazyalltnt@rl-paper/56b9ef150472f709633fcf79f23b4fb4.svg)
Double DQN 和 Double Q-learning 的 target 公式只有最后一个 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图37](/uploads/projects/crazyalltnt@rl-paper/c9b8ab7b3160968f5a7099f89b806bfd.svg) 的上标不一样。不过这只是公式层面上的不同,之所以标记成不一样的上标是因为他们的更新第二个网络的方式不同:
的上标不一样。不过这只是公式层面上的不同,之所以标记成不一样的上标是因为他们的更新第二个网络的方式不同:
- 在 Double Q-learning 中,这两组参数
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图38](/uploads/projects/crazyalltnt@rl-paper/c56ad760fa7ad2d07abfa8bdab9e4298.svg) 和
和 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图39](/uploads/projects/crazyalltnt@rl-paper/df929774eb8150c6356d240a7f0effa7.svg) 通过定期的交换位置来对称的更新。
通过定期的交换位置来对称的更新。 - 在 Double DQN 中,目标网络的参数
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图40](/uploads/projects/crazyalltnt@rl-paper/5550fb3eff846864f39a64f4a9fa8e8a.svg) 更新方式是与原有的 DQN 保持一致,只是多了另外一个网络的参数,这个网络更新方式是定期的将前面一个网络的参数同步过来。(从原有的交换位置对称更新,变成了定期将一边的参数复制到另一边进行同步)
更新方式是与原有的 DQN 保持一致,只是多了另外一个网络的参数,这个网络更新方式是定期的将前面一个网络的参数同步过来。(从原有的交换位置对称更新,变成了定期将一边的参数复制到另一边进行同步)
Double DQN 的算法流程,和 DQN 的区别仅仅在步骤 4.b.vi 中目标 Q 值的计算。在 Double DQN 这里,不再是直接在目标 Q 网络里面找各个动作中最大 Q 值,而是先在当前 Q 网络中先找出最大 Q 值对应的动作, 然后利用这个选择出来的动作在目标网络里面去计算目标 Q 值。即:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图41](/uploads/projects/crazyalltnt@rl-paper/f2ef246d515e6f3370fe86b7c11e636e.svg) :::info
:::info
- 初始化 replay memory D,用来存储 N 个训练的样本
- 随机初始化 action-value function 的
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图42](/uploads/projects/crazyalltnt@rl-paper/0d1593e165c085cdeec998e1fa92fbf9.svg) 卷积神经网络参数
卷积神经网络参数 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图43](/uploads/projects/crazyalltnt@rl-paper/2629d9896551d3fbe47c1e08422e812c.svg)
- 初始化目标 action-value function 的卷积神经网络
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图44](/uploads/projects/crazyalltnt@rl-paper/b12b50fc8cb4f999904bbe9f847f8b01.svg) ,其参数
,其参数 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图45](/uploads/projects/crazyalltnt@rl-paper/c6dd9f529a34ecb0fb66dd55137a8f23.svg) 等于 Q 的参数
等于 Q 的参数 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图46](/uploads/projects/crazyalltnt@rl-paper/279996d494fa61bb0ae7ab4ff9b1884d.svg)
- 训练分成 M 个episode(即 M 场游戏),每个 episode 训练 T 次。
- 每一次新的 episode 都要初始化 state,并且做图像预处理,得到 4 84 84 的视频帧
- 重复 T 个状态序列:
- 以 ε 概率随机选择动作否则选择
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图47](/uploads/projects/crazyalltnt@rl-paper/3c5531e8130499a8fb6969682adee928.svg) 值最大的动作
值最大的动作 - 执行动作
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图48](/uploads/projects/crazyalltnt@rl-paper/c8e42a6fd2a3c5e2e2cd9523514c8fc7.svg) 并观察奖励
并观察奖励 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图49](/uploads/projects/crazyalltnt@rl-paper/ce0b8e6388c73610e1bc1a09bd353a6c.svg) 和图像
和图像 ![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图50](/uploads/projects/crazyalltnt@rl-paper/3c7f5b5575c876f499d61855a8438208.svg)
- 更新状态和并预处理
- 存储经验序列元组 <s, a, r, s’> 到经验池 D
- 从经验池随机采样 minibatch 的序列样本
- 为每一 minibatch 数据计算目标值
- 使用梯度下降训练网络
- 每 C 步重置
![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图51](/uploads/projects/crazyalltnt@rl-paper/8a0ce6630e96a9e547d4ef959444c2ba.svg) :::
:::
- 以 ε 概率随机选择动作否则选择
在 Atari 游戏上的实践
跟之前的两篇 paper 一样,提出了一种新的思路就在 Atari 这种理想的 RL 环境中验证一下效果。仍然是所有的游戏都使用同一套超参数,同一套神经网络。有一点不同的是,这次的神经网络架构与之前的略微不同。对比如下图:![📝[DDQN]Deep Reinforcement Learning with Double Q-learning - 图52](/uploads/projects/crazyalltnt@rl-paper/7d107eadd358908beb5c34fa279b5577.png)
这次着重观察了 DQN 和 Double DQN(下面简称 DDQN)在六个游戏中的表现,并且得到了这样的实验结果: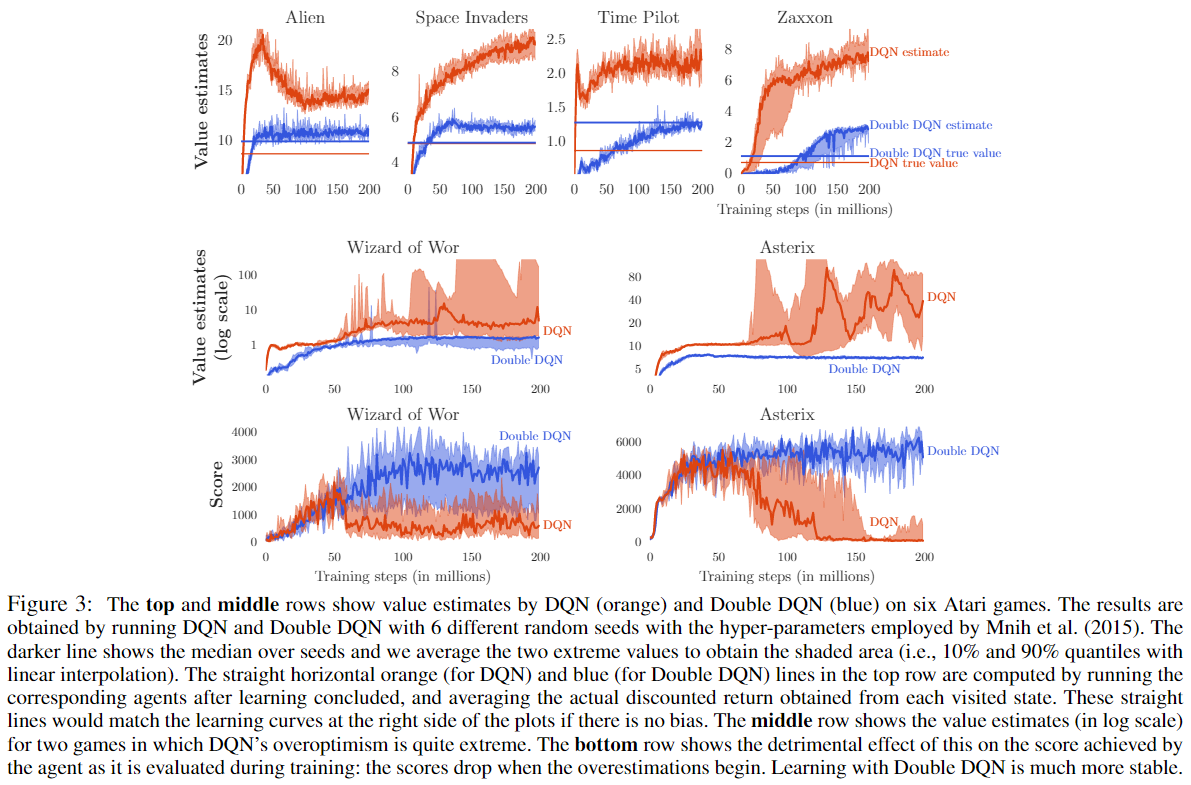
注意到上面四张图中有 true value,但是对于 Atari 游戏来讲,我们很难说某个状态的 Q 值等于多少,于是DeepMind 想到了一个代替方案:拿到已经学好的游戏策略,按照这个策略去跑几次游戏,然后我们就能知道一个游戏中积累的 reward,就能得到平均的 reward 作为 true value 了。
如果没有过高估计的话,收敛之后我们的估值应该跟真实值相同的(每个图的曲线应该跟直线在最右端重合),但是从图中看出,大部分情况下并不是这样,这又一次证明了过高估计确实不容易避免,但是我们可以看出,针对这个问题,DDQN 确实比 DQN 做的要好很多。
除此之外,通过 Wizard of Wor 和 Asterix 这两个游戏可以看出,DQN 的结果比较不稳定。这也进一步证明了过高估计会影响到学习的性能。但是在之前有人认为这些不稳定的问题是 off-policy learning 固有的,于是这篇 paper 中将 DDQN 的结果摆在了一起,DDQN 跟 DQN 一样是 off-policy learning,但是在这两个游戏中表现的更加稳定,因此不稳定的问题的本质原因还是对 Q 值的过高估计。
随后为了验证学到的策略的质量以及算法是否稳定,他们用下面三种方式在不同 Atari 游戏上进行了对比:
- 之前的 DQN
- 完全采用之前 DQN 的超参数(hyper-parameter),只是改成用 DDQN(查看 DDQN 在减小过高估计这一点上比 DQN 的优势)
- 调整第二种方法上的超参数,发挥 DDQN 更大的性能
整体的实验结果不出所料,第三种的结果比前面两种都要好。
更进一步的,他们为了证明算法的稳定性,采用了不同的时间点开始切入学习(比如人们先玩 30 分钟再让 AI 开始学习),发现 DDQN 的结果更加稳定,并且 DDQN 的解并没有利用到环境的相关特性。
总结
总结一下这篇 paper 的内容:
- 他们证明了在很多的问题中,Q-learning 都会导致过高估计的问题。
- 通过在 Atari 游戏中的实验,他们发现这个问题比之前人们预想的都要严重。
- 他们证明了使用 Double Q-learning 能减少这类问题的影响,导致结果更加稳定以及可信。
- 他们提出了 DDQN,可以很方便的在原有 DQN 上进行修改,直接使用现成的深度神经网络架构,并且不需要额外的参数。
- DDQN 在 Atari 2600 领域获得了更好的成果。
参考
- Double DQN原理是什么,怎样实现?(附代码)
- DQN三大改进(一)-Double DQN-Double DQN)
- DeepRL系列(8): Double DQN(DDQN)原理与实现
- [笔记]Deep Reinforcement Learning with Double Q-learning
- 强化学习(十)Double DQN (DDQN)
About

若有收获,就点个赞吧
0 人点赞
