虽然将深度学习和增强学习结合的想法在几年前就有人尝试,但真正成功的开端就是 DeepMind 在 NIPS 2013 上发表的 Playing Atari with Deep Reinforcement Learning 一文,在该文中第一次提出 Deep Reinforcement Learning 这个名称,并且提出 DQN(Deep Q-Network)算法,实现从纯图像输入完全通过学习来玩 Atari 游戏的成果。之后 DeepMind 在 Nature 上发表了改进版的 DQN 文章 Human-level Control through Deep Reinforcement Learning,引起了广泛的关注,Deep Reinfocement Learning 从此成为深度学习领域的前沿研究方向。
摘要
我们第一个提出了“利用强化学习从高维输入中直接学习控制策略”的深度学习模型。该模型是一个卷积神经网络,经过 Q-learning 训练,输入为原始像素,输出为“用来估计未来 reward”的值函数。我们将我们的方法应用于游戏环境下的 7 款 atari 2600 游戏,没有调整过架构或学习算法。我们发现它在 6 个游戏中超越了所有以前的方法,并且在 3 个游戏中超过了人类专家。
背景
《打砖块(Breakout)》 游戏环境的状态可由拍子的位置、球的位置和方向以及每个砖块的存在与否来定义。但这种直观的表征是这个游戏独有的,并不适合所有游戏。我们需要一个适合所有游戏的表征,屏幕图像是一个明显的选择,它们毫无疑问包含了游戏状况中除了球的速度和方向以外的所有相关信息,两个连续的屏幕图像就能覆盖这些例外。
当前深度学习的方式核心在于采用大量的数据集,然后使用 SGD 进行权值的更新。所以,这里的目标就是将增强学习的算法连接到深度神经网络中,然后能直接输入 RGB 的原始图像,并使用 SGD 进行处理。
相关工作
自此之前强化学习最著名的案例也许是 TD-gammon,它可能是最早的应用神经网络的强化学习项目。这是一个完全通过强化学习和自我游戏来学习的游戏程序,它达到了一个超越人类级别的水平。TD-gammon 使用了一种类似 Q-learning 的无模型强化学习算法,并使用一个带有一个隐藏层的多层感知器来逼近 value 函数。
然而,早期 TD-gammon 的尝试将同样的方法应用到国际象棋、围棋和西洋跳棋上都不太成功。这导致人们普遍认为 TD-gammon 方法是一种只适用于西洋双陆棋的特殊情况,可能是因为骰子滚动的随机性有助于探索状态空间,并使 value 函数特别平滑。
此外,结合无模型强化学习算法,例如具有非线性函数逼近器的 Q-learning 或者 off-policy 学习可能导致 Q-network 发散。随后,强化学习的大部分工作都集中在“具有更好的收敛性保证的线性函数逼近器”上。最近,人们又开始研究将深度学习与强化学习相结合。深度神经网络被用于评估环境 ε ;利用有限玻尔兹曼机对 value 函数或者策略进行估计;此外,用梯度时间差分方法部分解决了 Q-learning 中的发散问题。当用非线性函数近似器对策略进行评估时,这些方法被证明是收敛的。
方法机制
预处理和模型体系结构
DeepMind 在游戏屏幕上应用相同的预处理——以最近四张屏幕照片为例,将它们的尺寸从 210160 下采样调整到 11084,由于使用 Imagenet classification with deep convolutional neural networks 的 2D 卷积的 GPU 实现要求平方输入,通过简单剪裁调整到 84*84,并将它们灰度从 128 色调调整为 256 阶灰度,会得到 256^84844 ≈ 10^67970 种可能的游戏状态。这意味着我们想象的 Q 函数表有 10^67970 行——超过已知宇宙中原子的总数!
有人可能会说很多像素组合(即状态)根本不可能出现,我们也许可以用一个只包含可访问状态的稀疏的表格来表示它。即便如此,其中大部分状态都是极少能出现的,要让 Q-函数表收敛,那得需要整个宇宙寿命那么长的时间。理想情况下,我们也喜欢对我们从未遇见过的状态所对应的 Q 值做出很好的猜测。
这就到了深度学习的用武之地。神经网络在高度结构化数据的特征提取方面表现格外优异。我们可以使用神经网络表示我们的 Q 函数,并将状态(四个游戏屏幕)和动作作为输入,将对应的 Q 值作为输出。或者我们也可使用唯一的游戏屏幕作为输入,并为每一个可能的动作输出 Q 值。这种方法有自己的优势:如果我们想执行 Q 值更新或选取对应最高 Q 值的动作,我们只需对网络进行一次彻底的前向通过,就能立即获得所有可能的动作的 Q 值。
![📝[DQN]Playing Atari with Deep Reinforcement Learning - 图2](/uploads/projects/crazyalltnt@rl-paper/f13a0c010b840ac158b4274d2e10f714.webp)
左图:深度 Q 网络基本形式;右图:优化过的深度 Q 网络架构,在 DeepMind 论文中使用过
DeepMind 使用的网络架构如下:![📝[DQN]Playing Atari with Deep Reinforcement Learning - 图3](/uploads/projects/crazyalltnt@rl-paper/8b3a8aacbe4378d2024eb02f04813bf8.webp)
这是一个经典的带有三个卷积层的卷积神经网络,后面跟随着两个全连接层。熟悉对象识别网络的人可能注意到这里并没有池化层(pooling layer)。但如果真正仔细想想,池化层让你获得了平移不变性(translation invariance)——网络变得对图像中的物体的位置不敏感。这对于 ImageNet 这样的分类任务是有意义的,但游戏中球的位置对确定潜在的奖励是至关重要的,而且我们并不希望丢弃这个信息!
这个网络的输入是 4 个 84*84 的灰度游戏屏幕。这个网络的输出是是每一个可能动作的 Q 值(Atari 中有 18 个动作)。Q 值可以是任何真实值,这使其成为了一个回归( regression )任务,可以使用简单的平方误差损失进行优化。
经验回放(Experience Replay)
现在,我们有一个使用 Q 学习估计每个状态的未来奖励和使用一个卷积神经网络逼近 Q 函数的想法了。但事实证明,使用非线性函数的 Q 值逼近不是很稳定。事实上你不得不使用很多技巧才能使其收敛。而且也需要很长的处理时间——在单个 GPU 上需要几乎一周的时间。
最重要的技巧是经验回放。在游戏过程中,所有经验 < s, a, r, s’> 都被存储在回放存储器中。当训练网络时,使用的是来自回放存储器的随机微批数据(minibatches),而不是使用最近的变换。这打破了后续训练样本的相似性,否则其就可能使网络发展为局部最小。经验回放也会使训练任务更近似于通常的监督式学习,从而简化了算法的调式和测试。我们实际上可以从人类玩的游戏中学习到所有这些经验,然后在这些经验之上训练网络。
探索-利用(Exploration-Exploitation)
Q-学习试图解决信用分配问题(Credit Assignment Problem)——它能在时间中反向传播奖励,直到其到达导致了实际所获奖励的关键决策点。但我们还没触及到探索-利用困境呢……
首先观察,当 Q 函数表或 Q 网络随机初始化时,那么其预测一开始也是随机的。如果我们选择一个有最高 Q 值的动作,那么该动作就将是随机的且该代理会执行粗糙的「探索(exploration)」。当 Q 函数收敛时,它返回更稳定的 Q 值,探索的量也会减少。所以我们可以说,Q 学习将探索整合为了算法的一部分。但这种探索是「贪心的(greedy)」,它会中止于其所找到的第一个有效的策略。
针对上述问题的一个简单而有效的解决方法是 ε-贪心探索(ε-greedy exploration)——其以概率 ε 选择了一个随机动作,否则就将使用带有最高 Q 值的「贪心的」动作。在 DeepMind 的系统中,他们实际上随时间将 ε 从 1 降至了 0.1——一开始系统采取完全随机的行动以最大化地探索状态空间,然后再稳定在一个固定的探索率上。
Deep Q-learning
 :::info
:::info
- 初始化经验回放池 D 容量为 N
- 使用随机权重初始化动作-价值函数 Q
- 重复游戏片段 M(M 场游戏)
- 初始化状态并做图像预处理,得到大小为 84844 的图像帧
- 重复 T 个状态序列:
- 以 ε 概率随机选择动作否则选择 Q 值最大的动作
- 执行动作
![📝[DQN]Playing Atari with Deep Reinforcement Learning - 图5](/uploads/projects/crazyalltnt@rl-paper/d0160604fb8badd59e98de6687baa3e9.svg) 并观察奖励
并观察奖励 ![📝[DQN]Playing Atari with Deep Reinforcement Learning - 图6](/uploads/projects/crazyalltnt@rl-paper/0889f29256e67c2c3e8f0f9f4b2567fe.svg) 和图像
和图像 ![📝[DQN]Playing Atari with Deep Reinforcement Learning - 图7](/uploads/projects/crazyalltnt@rl-paper/9d2b002873bfb69baf4e2e262f4a2cfc.svg)
- 更新状态和并预处理
- 存储经验序列元组 <s, a, r, s’> 到经验池 D
- 从经验池随机采样 minibatch 的序列样本
- 为每一 minibatch 数据计算目标值
- 使用梯度下降训练网络 :::
DeepMind 还使用了更多技巧使其真正能够工作——如目标网络、错误剪裁(error clipping)、奖励剪裁(reward clipping)。
这个算法最精彩的一面在于其能学习任何事物。试想一下,因为我们的 Q 函数是随机初始化的,它的初始输出完全是垃圾。而我们使用这个垃圾(下一状态的最大 Q 值)作为网络的目标,只有偶尔处在一个很小的奖励范围内。这听起来很疯狂,它到底怎么能学习任何有意义的事物呢?但事实是它确实可以。
实验
- 测试 7 个游戏
- 统一不同游戏的 reward,正的为 1,负的为 -1,其他为 0。这样做的好处是限制误差的比例并且可以使用统一的训练速度来训练不同的游戏
- 使用 RMSPro p算法,就是 minibatch gradient descent 方法中的一种。梯度下降有很多种方法包括(SGD, Momenturn, NAG, Adagrad, Adadelta, Rmsprop)相关问题以后再分析。
- ε 前 1 百万次从 1 下降到 0.1,然后保持不变。这样一开始的时候就更多的是随机搜索,之后慢慢使用最优的方法。
- 使用 frame-skipping technique,意思就是每 k frame 才执行一次动作,而不是每帧都执行。在实际的研究中,如果每帧都输出一个动作,那么频率就太高,基本上会导致失败。在这里,中间跳过的帧使用的动作为之前最后的动作。这和人类的行为是一致的,人类的反应时间只有 0.1,也是采用同样的做法。并且这样做可以提速明显的。那么这里 Deepmind 大部分是选择 k=4,也就是每 4 帧输出一个动作。
训练
如何在训练的过程中估计训练的效果在RL上是个Challenge。毕竟不像监督学习,可以有 training 和 validation set。那么只能使用 reward,或者说平均的 reward 来判定。也就是玩的好就是训练的好。
但是存在问题就是 reward 的噪声很大,因为很小的权值改变都将导致策略输出的巨大变化,从文章的图中可以看出: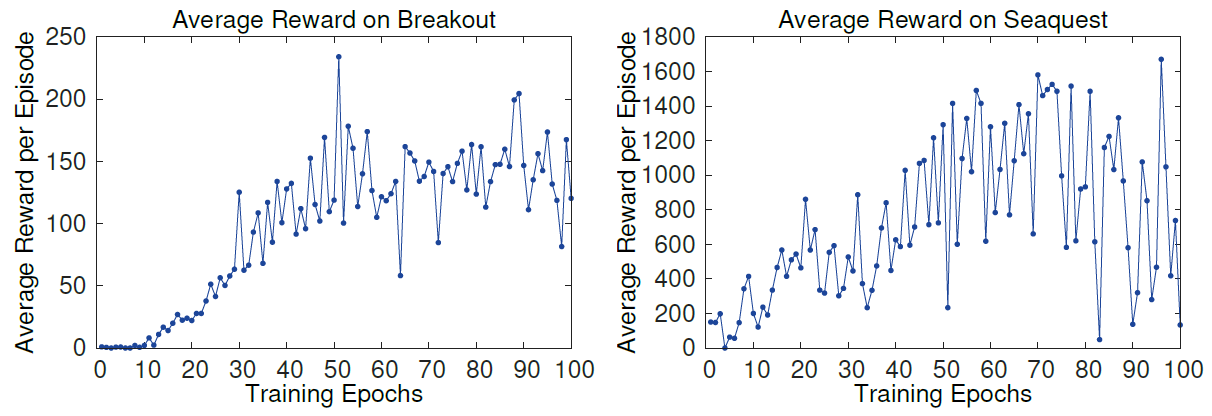
与此同时,平均 Q 值的变化却是稳定的,这是必然的,因为每次的 Target 计算都是使用 Q 的最大值。: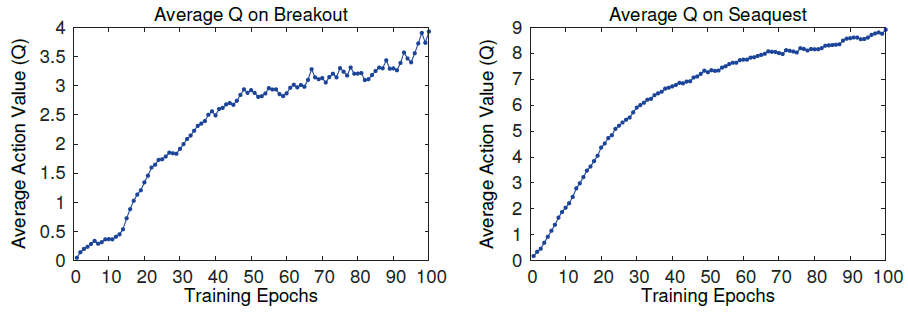
效果
看一下每一帧的 Q 值变化,在敌人出现时,Q值上升,快消灭敌人时,Q值到顶峰,敌人消失,Q值回到正常水平。这说明 Q 值确实代表了整个复杂的状态。实际上到后面发现,整个神经网络可以同时跟踪多个图上的目标:
算法评估
算法对比了:
- Sarsa 算法。使用Sarsa算法学习一个线性的policy,采用手工获取的特征。
- Contingency 算法。 采用和 Sarsa 相同的方法,但是通过学习部分屏幕的表达增强了特征。
上面的方法的特征提取都采用传统的图像处理方法比如背景减除。
总之就是特征提取方式落后。Deepmind的算法是原始输入计算机需要自己去 detect 物体。(直接解决了detection 和 tracking 的问题)
以此同时,当然是对比人类的水平了。人类的得分是人类玩两小时的结果,反正是蛮高的。但deepmind的方法有几个超过人类,总而言之就是方法好,并且在使用 ε 为 0.05 的得分还比其他方法强。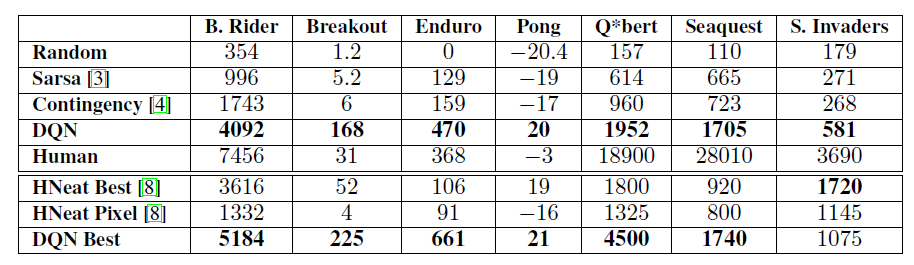
总结
这篇文章采用了一个全新的方法结合深度学习和增强学习,可以说是 deep reinforcement learning 的开山之作。采用 stochastic minibatch updates 以及 experience replay 的技巧。 效果很强,具有通用性。
自问世以来,Q 学习已经取得了很多改进——比如:双 Q 学习(Double Q-learning)、优先经验回放(Prioritized Experience Replay)、竞争网络架构(Dueling Network Architecture)和连续动作空间的扩展。
深度 Q-学习已被谷歌申请了专利。
参考
- 重磅 | 详解深度强化学习,搭建DQN详细指南(附论文)
- Paper Reading 1 - Playing Atari with Deep Reinforcement Learning
- [笔记]Playing Atari with Deep Reinforcement Learning
About

若有收获,就点个赞吧
0 人点赞
