本文主要讲一下从策略梯度到 Actor-Critic 算法的理解。
本文大部分内容总结来自作者的知识库:
强化学习👣
策略梯度(Policy Gradient)
假设现在有一个单步马尔科夫决策过程(One-step MDPs),对应的强化学习问题是个体与环境每产生一个动作交互一次即得到一个即时奖励  ,并形成一个完整的状态序列。策略目标函数为:
,并形成一个完整的状态序列。策略目标函数为:
对应的策略目标函数的梯度为:
TheoremPolicy Gradient Theorem
对于任何可微的策略函数  以及任何策略目标函数
以及任何策略目标函数  中的任意一种来说,策略目标函数的梯度(策略梯度)都可以写成用分值函数表示的形式:
中的任意一种来说,策略目标函数的梯度(策略梯度)都可以写成用分值函数表示的形式:
上式建立了策略梯度与分值函数以及动作价值函数之间的关系,分值函数的在基于策略梯度的强化学习中有着很重要的意义。策略梯度定理将似然比方法推广到多步 MDPs,将即时奖励  替换为长期值
替换为长期值  。
。
蒙特卡罗策略梯度(Monte-Carlo Policy Gradient)使用策略梯度定理和随机梯度上升更新参数,同时使用返回值  作为
作为  的无偏样本。
的无偏样本。
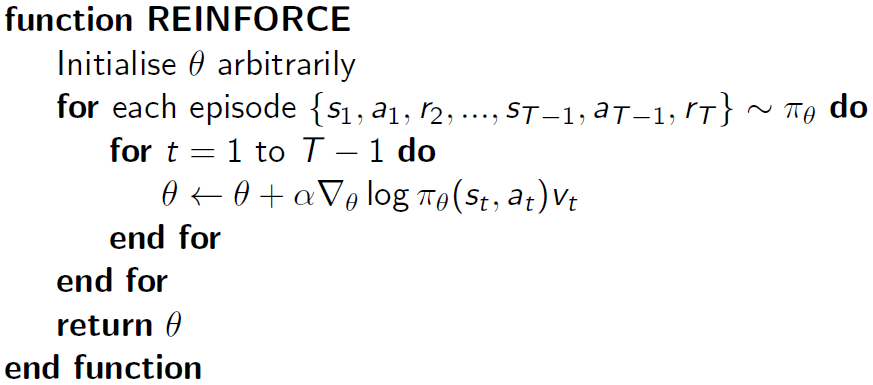
蒙特卡罗策略梯度 REINFORCE 算法

REINFORCE with Baseline
利用了等式:
也就是说可以在  后减去任意与动作
后减去任意与动作  无关的项
无关的项  ,这样可以减少算法的方差。
,这样可以减少算法的方差。
更新项就变成了:

演员-评论家(Actor-Critic,AC)
蒙特卡罗策略梯度仍然有比较高的方差,我们使用评论家(critic)来估计动作价值函数:
演员-评论家(Actor-Critic)算法维护两组参数:
- 评论家更新动作价值函数的参数

- 演员按照评论家建议的 方向更新策略参数

Actor-Critic 算法遵循近似的策略梯度:
评论家正在解决一个熟悉的问题:策略评估。对于当前参数  ,策略
,策略  有多好?这个问题在前两节课中已经讨论过了,例如:
有多好?这个问题在前两节课中已经讨论过了,例如:
- 蒙特卡罗策略评估
- 时差学习
- TD(λ)
也可以使用最小二乘法来进行策略评估
简单的 Actor-Critic 算法基于动作价值评论,使用线性值函数近似: 。其中 Critic 使用线性 TD(0) 更新
。其中 Critic 使用线性 TD(0) 更新  ,Actor 使用策略梯度更新
,Actor 使用策略梯度更新  。
。

这里说一下参数  的更新。在价值函数近似中,线性价值函数近似(Linear ValueFunction Approximation)方法如下:
的更新。在价值函数近似中,线性价值函数近似(Linear ValueFunction Approximation)方法如下:
- 通过特征的线性组合表示值函数
 ;
;
- 目标函数在参数 w 中是二次的
 ;
;
- 随机梯度下降会收敛到全局最优值(global optimum);
- 在线性值函数近似的情况下,梯度的计算变得非常简单

参数更新量 = 步长 × 预测误差 × 特征值
之前是假设了给定了真实的值函数  ,但是在 RL 环境中,并不知道真实的值函数,只有奖励值。直观地,我们用目标值替代
,但是在 RL 环境中,并不知道真实的值函数,只有奖励值。直观地,我们用目标值替代  :
:
- 对于 MC,目标值是回报值


- 对于 TD(0),目标值是 TD 目标值


- 对于 TD(λ),目标值是
 回报值
回报值 

优势函数演员-评论家(Advantage Actor-Critic,A2C)
Advantage Actor-Critic
这里和 REINFORCE with Baseline 一样,我们从策略梯度里抽出一个基准函数  ,要求这一函数仅与状态有关,与行为无关,因而不改变梯度本身。
,要求这一函数仅与状态有关,与行为无关,因而不改变梯度本身。 的特点是能在不改变行为价值期望的同时降低其 Variance。当
的特点是能在不改变行为价值期望的同时降低其 Variance。当  具备这一特点时,下面的推导成立:
具备这一特点时,下面的推导成立:
策略函数对数的梯度与基准函数乘积的期望可以表示为第一行等式对策略函数梯度与B(s)的乘积对所有状态及行为分布求的形式,这步推导主要是根据期望的定义,以及  是关于状态
是关于状态  的函数而进行的。由于
的函数而进行的。由于  与行为无关,可以将其从针对行为
与行为无关,可以将其从针对行为  的求和中提出来,同时我们也可以把梯度从求和符号中提出来(梯度的和等于和的梯度),从而后一项求和则变成:策略函数针对所有行为的求和,这一求和根据策略函数的定义肯定是 1,而常熟的梯度是 0。因此总的结果等于 0 。那么如何设计或者寻找这样一个
的求和中提出来,同时我们也可以把梯度从求和符号中提出来(梯度的和等于和的梯度),从而后一项求和则变成:策略函数针对所有行为的求和,这一求和根据策略函数的定义肯定是 1,而常熟的梯度是 0。因此总的结果等于 0 。那么如何设计或者寻找这样一个  呢?
呢?
原则上,和行为无关的函数都可以作为  。一个很好的
。一个很好的  就是基于当前状态的状态价值函数:
就是基于当前状态的状态价值函数:
这样我们通过使用一个优势函数(advantage function) 来重写策略目标函数梯度:
来重写策略目标函数梯度:
现在策略目标函数梯度的意义就改变成为了得到那个“好多少”,我应该怎么做(改变策略参数)?
估计优势函数(Generalized Advantage Estimator,GAE)
优势函数可以明显减少状态价值的变异性,因此算法的 Critic 部分可以去估计优势函数而不是仅仅估计行为价值函数。在这种情况下,我们需要两个近似函数也就是两套参数,一套用来近似状态价值函数,一套用来近似行为价值函数,以便计算优势函数,并且通过 TD 学习来更新这两个价值函数。数学表示如下:
不过实际操作时,并不需要这样做,因为根据定义,TD 误差  可以根据真实的状态价值函数
可以根据真实的状态价值函数  算出:
算出:
这样得到的 TD 误差是优势函数的无偏估计,这同样是根据行为价值函数的定义推导成立的,即:
如此,我们就可以使用 TD 误差来计算策略梯度:
实际运用时,我们使用一个近似的 TD 误差,即用状态函数的近似函数来代替实际的状态函数:
这样做的好处就是,我们只需要一套 Critic 参数  描述状态价值函数,而不再需要针对行为价值近似函数了。
描述状态价值函数,而不再需要针对行为价值近似函数了。

结语
- Policy Gradient 分两大类:基于Monte-Carlo的 REINFORCE(MC PG)和基于TD的 Actor Critic(TD PG)。
- REINFORCE 是Monte-Carlo式的探索更新,也就是回合制的更新,至少要等一个回合结束才能更新policy;
- Actor Critic 是基于TD的,也就是说可以按step来更新,不需要等到回合结束,是一种online learning。
- MC PG不利用马尔可夫性,TD PG利用马尔可夫性。
参考

若有收获,就点个赞吧
0 人点赞
