通常情况下,在使用“经验”回放的算法中,通常从缓冲池中采用均匀采样(Uniformly sampling),虽然这种方法在 DQN 算法中取得了不错的效果并登顶Nature,但其缺点仍然值得探讨,本文提出了一种优先级经验回放(prioritized experience reolay)技术去解决采样问题,并将这种方法应用在 DQN 中实现了 state-of-the-art 的水平。
摘要
Experience replay lets online reinforcement learning agents remember and reuse experiences from the past. In prior work, experience transitions were uniformly sampled from a replay memory. However, this approach simply replays transitions at the same frequency that they were originally experienced, regardless of their significance. In this paper we develop a framework for prioritizing experience, so as to replay important transitions more frequently, and therefore learn more efficiently. We use prioritized experience replay in Deep Q-Networks (DQN), a reinforcement learning algorithm that achieved human-level performance across many Atari games. DQN with prioritized experience replay achieves a new state-of-the-art, outperforming DQN with uniform replay on 41 out of 49 games.
简介
更新完参数立刻丢掉输入输出的数据造成两个问题:
- 这种强相关的更新打破了很多常用的基于随机梯度下降算法的所应该保证的独立同分布特性,容易造成算法不稳定或者发散;
- 放弃了一些在未来有用的需要重放学习的一些稀有经验。
1992 年提出 experience replay,解决了这两个问题,并在 2013 年提出的 DQN(Mnih et al.)中应用。experience replay 是 DQN 的一个关键技术,它通过存取 transition 的操作打破了数据之间的相关性,使得数据满足优化方法(e.g., SGD)的假设(i.e., i.i.d.),从而提高了学习的效果。
naive 的 experience replay 在取 transition 时采用的策略是均匀采样,对所有 transition 一视同仁。但直觉上来说,各个 transition 的重要性应该是不同的,有的 transition 的“信息量”比较大,有的 transition 则没什么用。
本文,作者提出了优先方法来使经验回放更加高效。核心思想是 RL 智能体可以从某些经验中更高效地学习。具体地,作者提出了更多地采样高期望值的经验,通过 TD 误差来衡量。这样的优先法会导致多样性的损失,作者采用随机优先化的方法来减少损失;还会引入误差,作者通过重要性采样来修正。
Prioritized Replay
Motivation
我们拿一个具体的例子来说明均匀采样有什么问题,假设我们有一个如下图所示的 environment,它有 n 个状态,2 个动作,初始状态为 1,状态转移如箭头所示,当且仅当沿绿色箭头走的时候会有 1 的 reward,其余情况的 reward 均为 0。那么假如采用随机策略从初始状态开始走 n 步,我们能够获得有用的信息(reward 非 0)的可能性为 ![📝[PER_DQN]Prioritized Experience Replay - 图1](/uploads/projects/crazyalltnt@rl-paper/3594a240b8c4a89e90d5213ae23d26cc.svg) 。也就是说,假如我们把各 transition 都存了起来,然后采用均匀采样来取 transition,我们仅有
。也就是说,假如我们把各 transition 都存了起来,然后采用均匀采样来取 transition,我们仅有 ![📝[PER_DQN]Prioritized Experience Replay - 图2](/uploads/projects/crazyalltnt@rl-paper/d43d6d0b4f8092e95960a06fad84ee77.svg) 的概率取到有用的信息,这样的话学习效率就会很低。
的概率取到有用的信息,这样的话学习效率就会很低。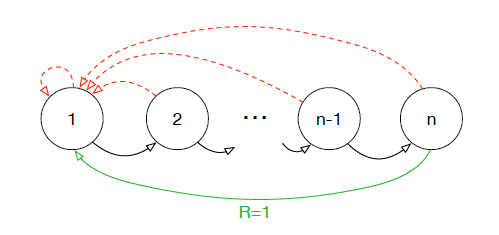
作者还做了个实验,来说明 transition 的选取顺序对学习效率有很大的影响。下图横轴代表 experience replay 的大小,纵轴表示学习所需的更新次数。黑色的线表示采用均匀采样得到的结果,绿色的线表示每次都选取“最好”的 transition 的结果。可以看到,这个效率提升是很明显的。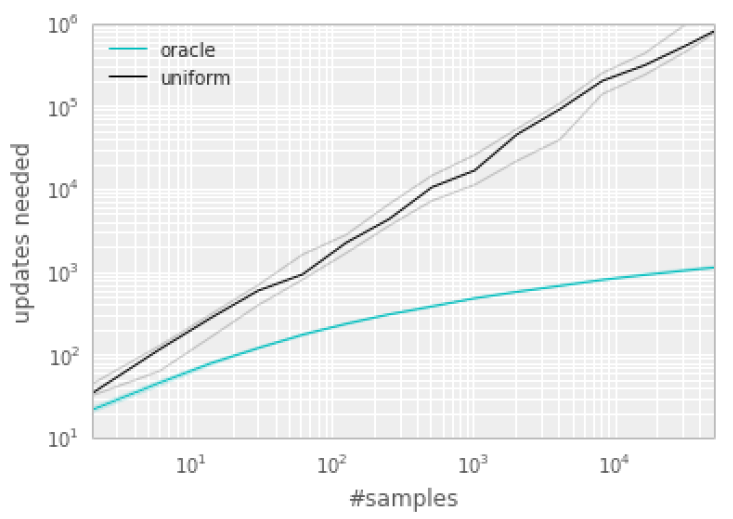
于是很自然的就会有一个想法,能不能通过优先学习那些“信息量”比较大的 transition 来提高学习效率呢?
Prioritizing with TD-error
如何衡量每个 transition 的重要程度是优先回放机制的中心,一种理想的机制是在当前状态下,按 agent 从 transitions 中学习的次数,但这实际不好获得。
更合理的是去计算每个transition的TD-error,这个值表示当前 Q 值与目标 Q 值有多大的差距。如果 TD-error 越大, 就代表我们的预测精度还有很多上升空间, 那么这个样本就越需要被学习, 也就是优先级 p 越高。
用 TD-error 来衡量更加适合增量的,在线的 RL 算法,如 Sarsa,Q-learning,因为这些在 Q 值更新上已经有计算 TD-error 的部分。作者首先给出了一个衡量指标:TD-error,随后贪心地选”信息量“最大的 transition。
为了说明 TD-error 发挥的潜在 effectiveness,我们在“Blind Cliffwalk” 环境下比较了随机抽取方式和基于greedy TD-error prioritization 算法的 oracle(先知上帝视角) 抽取方式(对于Q-learning)。
greedy TD-error prioritization 算法在经验池中存储了每个 transition 最后 encounter 的TD-error,用这种方式,将会以 TD-error 的绝对值最大的进行回放。这里如果当一个新的 transition 到来时,我们不知道它的 TD-error,那么就把这个 transition 的 TD-error 值设置为最大,这样可以保证所有的经验都会被至少回放一次。这种方法效果比随机抽取(uniform)效果好。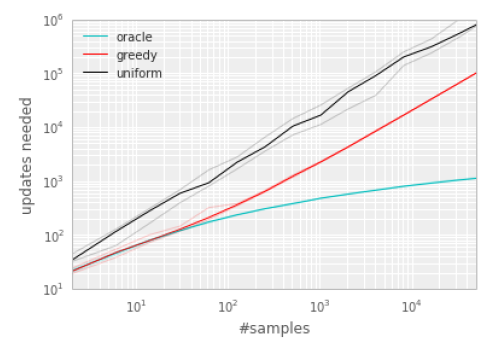
实现方法:经验池容量为 N,我们用二进制堆数据结构(binary heap data structure)来存储优先级序列。这样找到找到最高优先级的 transition 的复杂度是 O(1),更新优先级的复杂度 为 O(logN)。
Stochasitic prioritization
然而 greedy TD-error prioritization 方法存在以下缺陷:
- 由于考虑到算法效率,不会每次 critic 更新后都更新所有 transition 的 TD-error,我们只会更新当次取到的 transition 的 TD-error。因此 transition 的 TD-error 对应的 critic 是以前的 critic(更准确地说,是上次取到该 transition 时的 critic)而不是当前的 critic。也就是说某一个 transition 的 TD-error 较低,只能够说明它对之前的 critic“信息量”不大,而不能说明它对当前的 critic“信息量”不大,因此根据 TD-error 进行贪心有可能会错过对当前 critic“信息量”大的 transition。
- 容易 overfitting:基于贪心的做法还容易“旱的旱死,涝的涝死”,因为从原理上来说,被选中的 transition 的 TD-error 在 critic 更新后会下降,然后排到后面去,下一次就不会选中这些 transition),来来去去都是那几个 transition,导致 overfitting。
为了处理上述问题,作者提出 stochastic prioritization,随机化的采样过程,“信息量”越大,被抽中的概率越大,但即使是“信息量”最大的 transition,也不一定会被抽中,仅仅只是被抽中的概率较大。
用这种方式,我们可以保证transition被抽取的概率是按优先级单调的,同时保证对于低优先级的 transition 不会出现 0 概率抽取可能。具体的,抽取标号为 i 的 transition 的概率定义为:![📝[PER_DQN]Prioritized Experience Replay - 图6](/uploads/projects/crazyalltnt@rl-paper/da7dfc7ed90866ef4e113226ad54245e.svg)
这里 ![📝[PER_DQN]Prioritized Experience Replay - 图7](/uploads/projects/crazyalltnt@rl-paper/76425d1070f26d30fa99682cf09f2f78.svg) 是 transition i 的优先级,均大于 0,
是 transition i 的优先级,均大于 0,![📝[PER_DQN]Prioritized Experience Replay - 图8](/uploads/projects/crazyalltnt@rl-paper/fe04a565ece5c63603581773894e8ef5.svg) 是一个决定我们要使用多少 Importance Sampling weight 的影响,。如果
是一个决定我们要使用多少 Importance Sampling weight 的影响,。如果 ![📝[PER_DQN]Prioritized Experience Replay - 图9](/uploads/projects/crazyalltnt@rl-paper/c4f7915cb8a8b442aaeca6ed50bf8810.svg) ,我们就没使用到任何 Importance Sampling,就是 uniform random sampling。
,我们就没使用到任何 Importance Sampling,就是 uniform random sampling。
对于 ![📝[PER_DQN]Prioritized Experience Replay - 图10](/uploads/projects/crazyalltnt@rl-paper/0d1f80184828b8c8303cf15274b8660e.svg) 这个优先级值的定义,作者提出了两种变体,两种方案的区别在于对priority的定义不同:
这个优先级值的定义,作者提出了两种变体,两种方案的区别在于对priority的定义不同:
- 第一种变体:proportional prioritization(比例优先级)。
- 这里的
![📝[PER_DQN]Prioritized Experience Replay - 图11](/uploads/projects/crazyalltnt@rl-paper/3d6cb6d9328f122b9a61888c5f95e884.svg) ,
,![📝[PER_DQN]Prioritized Experience Replay - 图12](/uploads/projects/crazyalltnt@rl-paper/c105f0af3fbbd92053e289de9c7964c7.svg) 是一个很小的正常数为了使有一些 TD-error 为 0 的特殊边缘例子也能够被抽取。
是一个很小的正常数为了使有一些 TD-error 为 0 的特殊边缘例子也能够被抽取。 - 可能会对 outlier 更加敏感。
- 实现的时候采用sum tree的数据结构。
- 这里的
- 第二种变体:rank-based prioritization(基于排名的优先级)。
- 这里
![📝[PER_DQN]Prioritized Experience Replay - 图13](/uploads/projects/crazyalltnt@rl-paper/23e1dca51693adb931706df97eadf2b4.svg) ,这里的
,这里的 ![📝[PER_DQN]Prioritized Experience Replay - 图14](/uploads/projects/crazyalltnt@rl-paper/b07bb0db78f84ec9583fb48e344a2851.svg) 是按照
是按照 ![📝[PER_DQN]Prioritized Experience Replay - 图15](/uploads/projects/crazyalltnt@rl-paper/7f9419b78dd842c82dee65f5b63568a6.svg) 排序时 transition i 的等级。(这时 P 将成为幂律分布)。
排序时 transition i 的等级。(这时 P 将成为幂律分布)。 - 只是定性地考虑 priority,没有定量地考虑 priority。
- 实现类似分层抽样,事先将排名段分为几个等概率区间,再在各个等概率区间里面均匀采样。比如说,假设 experience replay 大小为 100,batch size 为 3,那么就事先通过计算,将 100 分为 3 个等概率区间(e.g., A:1-20,B:21-50, C:51-100),之后就在 A、B 和 C 区间内分别做均匀采样,最后取得 3 个 transition。
- 这里
对于这两种变体,P 都关于 ![📝[PER_DQN]Prioritized Experience Replay - 图16](/uploads/projects/crazyalltnt@rl-paper/db4e9fad28e6618a5178d7aca3e4a5f3.svg) 是单调的,对于第二种变体由于对异常值不敏感,可能更具有鲁棒性。但是经过试验,这两种变体都可以加速算法收敛:
是单调的,对于第二种变体由于对异常值不敏感,可能更具有鲁棒性。但是经过试验,这两种变体都可以加速算法收敛: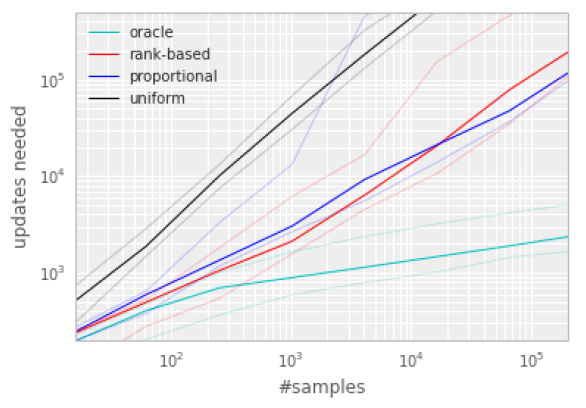
Annealing the bias(为减少 bias 提出解决方法)
随机更新对期望值的估计依赖于与预期相同的分布相对应的更新。优先重放机制引入了 bias,它以一种不受控制的方式改变了这个分布,因此改变收敛结果(即使策略和状态分布是固定的)。我们可以通过引入 importance-sample weights 来弥补:![📝[PER_DQN]Prioritized Experience Replay - 图18](/uploads/projects/crazyalltnt@rl-paper/be4b74bb149bf275b300b0fcbd751a91.svg)
这完全补偿了当 ![📝[PER_DQN]Prioritized Experience Replay - 图19](/uploads/projects/crazyalltnt@rl-paper/ac33b18121fbe0c31b34ec48291231c8.svg) 时非均匀概率
时非均匀概率 ![📝[PER_DQN]Prioritized Experience Replay - 图20](/uploads/projects/crazyalltnt@rl-paper/38cb6b913fd348c396981ff9db543b8f.svg) 。这些权重可以通过使用
。这些权重可以通过使用 ![📝[PER_DQN]Prioritized Experience Replay - 图21](/uploads/projects/crazyalltnt@rl-paper/c72e981934a6ca03ef92eb0da00485cd.svg) 而不是
而不是 ![📝[PER_DQN]Prioritized Experience Replay - 图22](/uploads/projects/crazyalltnt@rl-paper/caf729a771431658708337defb83166c.svg) 来加入到 Q-network 更新中。
来加入到 Q-network 更新中。
Importance sampling 的影响:
在典型的强化学习场景中,更新的无偏性在训练结束接近收敛时是最重要的,因为由于策略、状态分布和引导目标的改变,有 bias 会高度不稳定,与未修正的优先重放相比,Importance sampling 使学习变得不那么具有侵略性,一方面导致了较慢的初始学习,另一方面又降低了过早收敛的风险,有时甚至是更好的最终结果。与 uniform 重放相比,修正的优先级排序平均表现更好。
算法流程

总结
- 针对具体问题,某种 stochastic prioritization 方案会表现得比另外一种更好。
- 类似的 priority 思想可以用到 supervised learning 中。
- 某个 transition 被访问的次数反映了这个 transition的“重要性”,可以作为一个 feedback signal 给到exploration。
- 可以通过这种方法减小 experience replay 的大小,从而减少训练所需的内存。
参考
- 论文笔记7:Prioritized Experience Replay
- 论文笔记《Prioritized Experience Replay》
- DQN系列(3): 优先级经验回放(Prioritized Experience Replay)论文阅读、原理及实现
About

若有收获,就点个赞吧
0 人点赞
