这篇 paper 是基于上一篇 Playing Atari with Deep Reinforcement Learning 的改进,算法层面将前一篇提出的 DQN(Deep Q Netword)加入了 Target Q,并分析了通过这种网络具体学到的内容大致是什么。实验部分将之前的 7 个 Atari 游戏扩展到了 49 个Atari游戏中,实验结果比之前的 paper 效果更好,并且分析了不同游戏类型中的优势与局限性。
摘要
强化学习理论根植于心理学和神经科学,它可以很好的解释一个代理如何在一个环境中优化自己的控制。为了在真实复杂的物理世界中成功的使用强化学习算法,一个代理必须面对困难的任务:利用高维的传感器输入数据,达到很好的表达,并且泛化之前的经验到新的未见环境中。显然的,人类和其他动物通过协调的组合强化学习以及层次化的感知处理系统来很好的处理这个问题。前者已经被大量的神经数据证明了,揭示了在多巴胺能的神经元激发的相位信号和短时差分强化学习算法。现在强化学习算法已经在一些领域取得了成功,然而它之前在那些手动提取有用特征的领域、或者一些低维可以直接观察到的领域受到了应用限制。这里我们使用最近先进的手段训练深度神经网络类得到一个,名字叫深度Q值网络的算法,它可以使用端到端的强化学习算法从高维的传感器输入中成功的直接学习到成功的策略。我们在很有挑战的游戏 Atari2600 中测试了这个代理。我们证明了,使用同一种算法和网络,同一种超参数,在 49 种游戏集合中,仅仅使用像素点和游戏分数作为输入,超过以往的任何一种算法达到和专业游戏玩家的水平。这个工作在高维数据输入和动作输出之间建立了桥梁,使得人工智能代理可以有擅长一些列的挑战性的工作。
背景
本文主要解决如何在高维度输入情况下进行 Reinforcement Learning。比如打 Atari 游戏中,如何让机器学会控制目标使得游戏得分最多。
传统的办法:
- Handcrafted 特征,即人工提取特征(比如在游戏中用背景建模方式提取目标位置);
- 使用线性的价值方程或者策略来表征。由于人工提取特征的鲁棒性不够,传统方法的性能主要取决于特征提取的好坏;另外线性的价值方程不能很好得模拟现实中的非线性。
本文提出来的 Deep-Q-Network 可以很好解决以上问题,即 CNN + Q-Learning = Deep Q Network 具体是将卷积神经网络和 Q Learning 结合在一起。卷积神经网络的输入是原始图像数据(作为状态)输出则为每个动作对应的价值 Value Function 来估计未来的反馈 Reward。即使用 CNN 来拟合最优的动作估值函数(optimal action-value function)。
DeepMind 在这篇 paper 中提到了,他们希望能做出通用人工智能,这就需要实际的 AI 不能仅仅局限于单一的问题。跟前面的 paper 中一样,他们不希望采用手动提取 feature 的方式,而是直接将游戏画面作为神经网络的输入,让网络自己练习从而面对一个游戏换面能做出正确的选择。这篇 paper 仍然是选择同样的算法同样的模型和网络结构(network architecture)以及同样的超参数(hyperparameter)来解不同的游戏,并且与其他的方法比较。并且针对上一篇 paper 中 Q 值不稳定的问题分析了原因,从而引出一个改良的方式就是 Target Q。
方法
预处理
为了降低维度对 Atari 2600 原始图像帧进行处理。首先对图片编码的时候,图片像素取要被编码的图片像素和前一帧图像像素的最大值,这是为了消除闪烁现象。因为有些物体只出现再奇数帧,有些只出现再偶数帧。然后从 210160 调整到 8484,提取 Y 通道(亮度),从 128 色调到 256 阶灰度。取 k=4 帧图像作为输入,此时鲁棒性最好。
模型架构
以往的求 Q 值的方法中使用了历史信息和动作作为输入,这导致了每个动作都会有一个 Q 值要计算,计算效率不高;该论文只有 state 作为输入,输出为每个动作对应的 Q 值的估计,这样在计算某个状态下的不同动作的 Q 值的时候,只需要计算一次网络的 forward 即可。模型如下: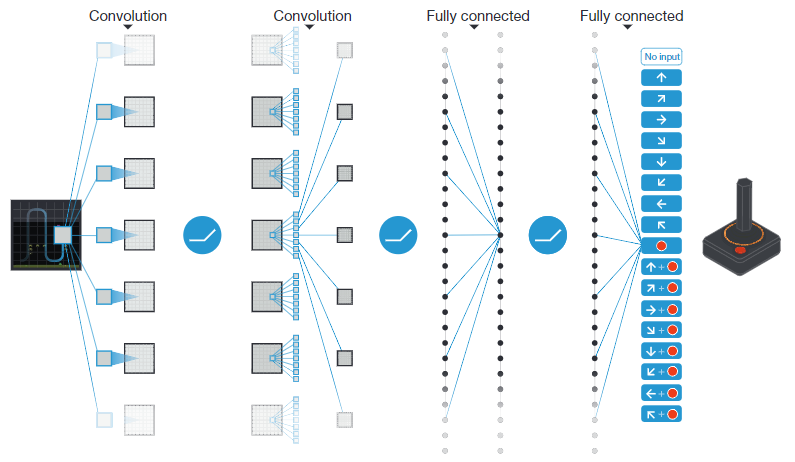
上图中展示的结构,DeepMind 使用的网络架构如下:![📝[DQN2]Human-level control through deep reinforcement learning - 图2](/uploads/projects/crazyalltnt@rl-paper/c47824e4ac1259c791475c1b51543c19.webp)
传入给神经网络的输入是预处理映射完毕后的 84844 的图像。输出层是 一个全连接,每一个有效地动作对应一个输出。作者考虑在游戏中,有效动作的数量 从 4~18 之间变换。
模型细节
以往的方法对不同的游戏使用各不同的模型,该论文只用一种模型(基于少量的先验知识,比如输入图片,游戏动作种类,游戏生命数量等)训练不同参数的网络,说明该论文模型的普适性好。
不同游戏的 reward 被归一化,正的为 1,负的为 -1,其他为 0。这样做可以限制误差的比例并且可以使用统一的训练速度来训练不同的游戏。
因为训练的数据量大,并且冗余度高或者说重复性高,因此使用 RMSProp 算法进行训练,其中的 mini-batch 大小是 32(梯度下降一看方向,二看步长,这里将梯度除以最近幅度的运行平均值)。通过引入一个衰减系数 ϵ,让 reward 每回合都衰减一定比例。ϵ-greedy 策略让 ϵ 前 1 百万次线性地从 1 下降到 0.1,然后保持在 0.1 不变。这样一开始的时候对 Q 值的更新采用随机搜索,后面慢慢使用最优的方法。这种方法很好的解决了深度学习中过早结束的问题,适合处理非平稳目标,但是引入了新的参数衰减系数ρ,依然依赖于全局学习速率。
像之前的算法一样使用了简单的 frame-skipping 技术对所有游戏跳 4 帧,理由是不大影响结果的情况下,计算效率更高。
改良算法
将打游戏视为智能体通过一系列的 action,observation,reward 和环境(这里指 Atari 模拟器)进行交互。模拟器内部的状态不被 agent 获得,agent 只能获取游戏画面以及相应的得分。显而易见的是现阶段的状态不仅仅是取决于当前游戏画面,也取决于之前的状态和动作。Agent 可以通过这些来学会如何打游戏,即如何选取当前的动作使得未来的效益得分最高。
与之前一样,游戏过程中不断把中间状态存储 memory 里面,在学习过程中随机抽取 minibatch 大小的样本进行 loss 的最小化,其中不同的地方在于更新过程中 ![📝[DQN2]Human-level control through deep reinforcement learning - 图3](/uploads/projects/crazyalltnt@rl-paper/538eea0130ce65fb4299081e47095850.svg) 的计算,之前是将
的计算,之前是将 ![📝[DQN2]Human-level control through deep reinforcement learning - 图4](/uploads/projects/crazyalltnt@rl-paper/d27ce733614a5e6e72a01c6d8de258be.svg) 喂给要计算的神经网络,让这个网络输出 Q 值作为 Target Q 进行自身的迭代。现在的做法是新建了一个一样的网络,这个网络的参数会定期更新成正在训练的那个网络的参数,其他时候参数并不参与迭代。计算
喂给要计算的神经网络,让这个网络输出 Q 值作为 Target Q 进行自身的迭代。现在的做法是新建了一个一样的网络,这个网络的参数会定期更新成正在训练的那个网络的参数,其他时候参数并不参与迭代。计算 ![📝[DQN2]Human-level control through deep reinforcement learning - 图5](/uploads/projects/crazyalltnt@rl-paper/151bb4337567a10228c28c99fbcfe138.svg) 的时候是用新的这个网络。
的时候是用新的这个网络。
用公式表述就是:![📝[DQN2]Human-level control through deep reinforcement learning - 图6](/uploads/projects/crazyalltnt@rl-paper/f0023fb5f8d08e50eaa2f6363aafe0af.svg)
与原来的公式对比就很容易理解其中的差别了:![📝[DQN2]Human-level control through deep reinforcement learning - 图7](/uploads/projects/crazyalltnt@rl-paper/e06e79367bf566b820380a4e09a52360.svg)
改良后的公式中 ![📝[DQN2]Human-level control through deep reinforcement learning - 图8](/uploads/projects/crazyalltnt@rl-paper/5c9d8525bd7cd7bd9cfc5462b1d751df.svg) 表示用来计算第 i 次迭代中 target 的网络参数。
表示用来计算第 i 次迭代中 target 的网络参数。 ![📝[DQN2]Human-level control through deep reinforcement learning - 图9](/uploads/projects/crazyalltnt@rl-paper/8a53a6c3a7d0ffa71a6a0990e1a70696.svg) 是我们在不停迭代的网络的参数,只有在固定的步骤之后我们才将
是我们在不停迭代的网络的参数,只有在固定的步骤之后我们才将 ![📝[DQN2]Human-level control through deep reinforcement learning - 图10](/uploads/projects/crazyalltnt@rl-paper/2151bfd7628b6ab16c2a7b0fe26fc39b.svg) 替换到
替换到 ![📝[DQN2]Human-level control through deep reinforcement learning - 图11](/uploads/projects/crazyalltnt@rl-paper/c9029941a499789bd29f972d771a3810.svg) 中。
中。![📝[DQN2]Human-level control through deep reinforcement learning - 图12](/uploads/projects/crazyalltnt@rl-paper/d95a1dbdb5c82ef54afcb23516a3ae5b.svg)
由此可以用 SGD 等梯度下降法解决。特点是 model-free,因为并没有固定明确的 ;同时也是 off-policy,ϵ-greedy 策略让ϵ前1百万次线性地从1下 降到0.1,然后保持在 0.1 不变。衰减参数为 ϵ 和选取动作参数为1-ϵ。这样一开始的时候对 Q 值的更新采用随机搜索,后面慢慢使用最优的方法。
训练 Q 网络
训练的困难在于在使用非线性函数拟合时很容易不稳定以致于发散。 原因主要是数据的相关性太强导致小的权值更新会导致 policy 策略大的变化。解决办法:
- experience replay,随机选取部分数据,目的是减少连续的帧的相关性以及使得 Q 更新更平滑,并且提高效率,还能使得训练不陷入局部最优;
- 固定 θ 目标 Q 值周期性更新(target value action),而非每帧都更新,目的是减少目标和 Q 值的相关性。
更新后的算法如下: :::info
:::info
- 初始化 replay memory D,用来存储 N 个训练的样本
- 随机初始化 action-value function 的
![📝[DQN2]Human-level control through deep reinforcement learning - 图14](/uploads/projects/crazyalltnt@rl-paper/f5d11d4d8a8ff29988e8e29e122ed1f0.svg) 神经网络参数
神经网络参数 ![📝[DQN2]Human-level control through deep reinforcement learning - 图15](/uploads/projects/crazyalltnt@rl-paper/ca565f034a9b6ac76ca6210973e1c0c1.svg)
- 初始化目标 action-value function 的神经网络
![📝[DQN2]Human-level control through deep reinforcement learning - 图16](/uploads/projects/crazyalltnt@rl-paper/005f67a40f6eb0d22c33be296f294404.svg) ,其参数
,其参数 ![📝[DQN2]Human-level control through deep reinforcement learning - 图17](/uploads/projects/crazyalltnt@rl-paper/c3f869ad71a81cd263e02692aa463c05.svg) 等于 Q 的参数
等于 Q 的参数 ![📝[DQN2]Human-level control through deep reinforcement learning - 图18](/uploads/projects/crazyalltnt@rl-paper/d543a5e0d624ca2618b9285842a94f7b.svg)
- 训练分成 M 个episode(即 M 场游戏),每个 episode 训练 T 次。
- 每一次新的 episode 都要初始化 state,并且做图像预处理,得到 4 84 84 的视频帧
- 重复 T 个状态序列:
- 以 ε 概率随机选择动作否则选择
![📝[DQN2]Human-level control through deep reinforcement learning - 图19](/uploads/projects/crazyalltnt@rl-paper/d6107a8519c3da9185f99d5a9cfbac84.svg) 值最大的动作
值最大的动作 - 执行动作
![📝[DQN2]Human-level control through deep reinforcement learning - 图20](/uploads/projects/crazyalltnt@rl-paper/ee2ed7f96e0e15d0ad3ed8e397cb14a2.svg) 并观察奖励
并观察奖励 ![📝[DQN2]Human-level control through deep reinforcement learning - 图21](/uploads/projects/crazyalltnt@rl-paper/ce01ce978e8b4a591e3746b89817d172.svg) 和图像
和图像 ![📝[DQN2]Human-level control through deep reinforcement learning - 图22](/uploads/projects/crazyalltnt@rl-paper/c5f3b077fc9262e0f820835f9fc5293b.svg)
- 更新状态和并预处理
- 存储经验序列元组 <s, a, r, s’> 到经验池 D
- 从经验池随机采样 minibatch 的序列样本
- 为每一 minibatch 数据计算目标值
- 使用梯度下降训练网络
- 每 C 步重置
![📝[DQN2]Human-level control through deep reinforcement learning - 图23](/uploads/projects/crazyalltnt@rl-paper/c35b405a103f131918a541f6bce55c1f.svg) :::
:::
- 以 ε 概率随机选择动作否则选择
结果分析
学习结果可视化
paper 中使用一种叫做 t-SNE 的降维方法将学习到的东西展示在二维平面上,并对产生的结果进行分析。Space Invaders 游戏结果如下图所示: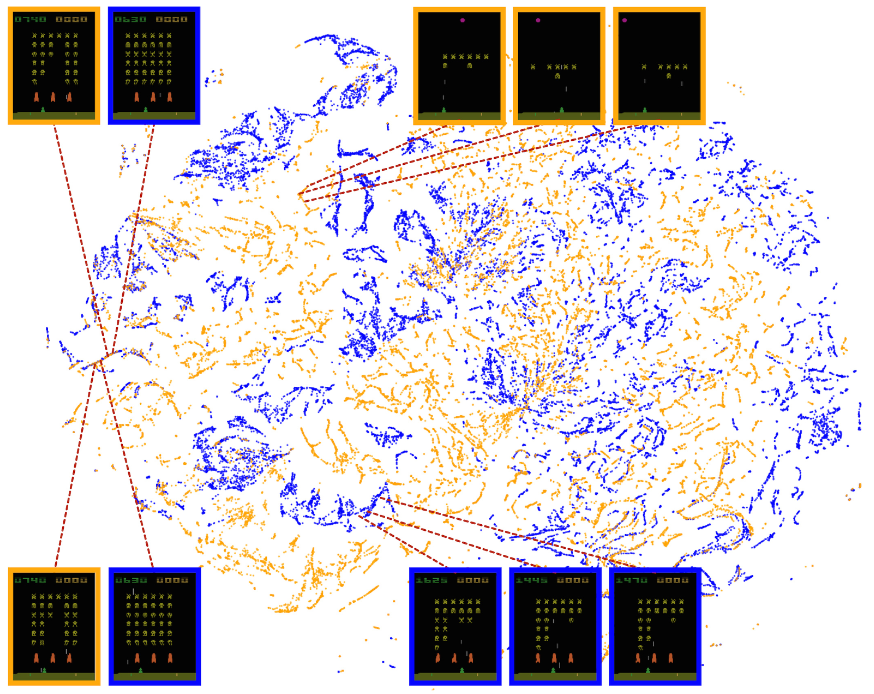
具体做法是将这个游戏两个小时的游戏画面喂给神经网络,提取最后一个隐藏层的 feature,然后使用 t-SNE 进行降维展示在平面上。图案中的颜色表示对这个状态的估值,估值由高到低是从深红色到深蓝色。从这个图形中可以看出一些信息:
- 对于状态相近的游戏画面,神经网络给的估值也相似,压缩后点的位置也很相近
- 网络还学到了不同时刻游戏中橘黄色掩体的重要性是不一样的。上图中给了三组除了有无掩体外其他状态比较相近的图,这三组图中的状态估值很接近(与其他时刻有无掩体比较),然而其实他们的状态差距有点大,这个原因就是已经到了游戏末期,掩体已经不是很重要了,有没有掩体对于状态的评估影响不大。
- 左下角(游戏即将结束)和右上角的图(游戏刚刚开始)估值接近并且都很大。是因为网络已经学到了在游戏结束后会立刻开始一个新的游戏(左下角的状态很容易切换到右上角的状态),而消除了一部分敌人的游戏画面估值不太高是因为这时候剩余的 reward 已经没有很多了。
- 在 paper 的 Extended Data 图一中,作者还比较了人类玩家不同时候的画面截图,以及 AI 自身游戏过程中的截图,用同样的方式喂给神经网络然后降维分析,发现网络没有区分人类玩家和 AI 玩家,对类似画面的估值是一样的,说明 DQN 确实是通过游戏数据生成的 Q 值,而不是自身产生的 Q 值。
对不同游戏类型的分析
对不不同类型的游戏,DQN 表现出的结果也不太一样,通过实验发现,DQN 比较擅长于需要相对长时间策略的游戏。比如打砖块(Breakout),AI 在游戏中学到了尽量在墙边打通一条通往顶部的路,这样球就会有很大的几率在上面自己碰撞消灭砖块而不需要玩家移动挡板,这个视频中展示了学到这个策略的效果。
然而对于需要一些规划的游戏(比如 Montezuma’s revenge),这种方式的实作效果不是很好,这个游戏中需要玩家先去找到钥匙然后开启大门过关,但是 AI 并没有学会这个逻辑。
Q 值的可视化以及实际意义分析
这个图中分析了Q值直观上代表的意义: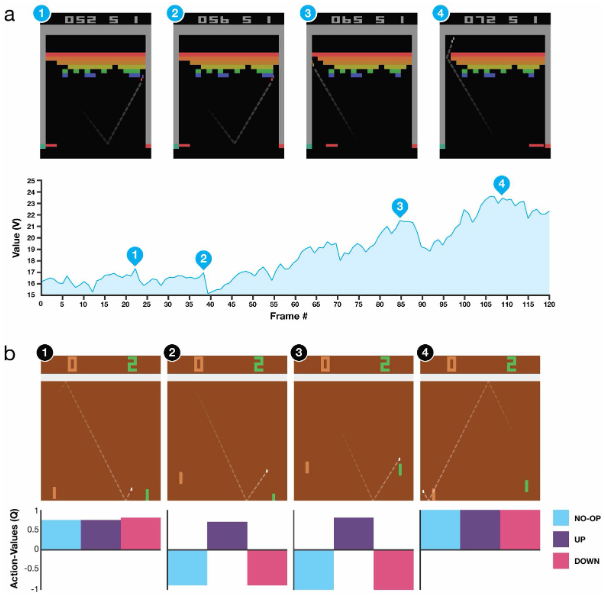
图 a 中的 1 和 2 都是快要打到砖块了,由于打到砖块会有一个 reward,这两个状态的 Q 值都会有一个小的上升,在清除砖块之后,由于 reward 已经得到,距离下一个 reward 又有段距离,所以接下来的状态 Q 值急剧下降。到图 3 的时候由于快要打通一个到顶部的通道了,所以 3 这个点的 Q 值很高。图 4 的时候已经打通了这个通道,小球可以在上面不停的消除砖块而不需要玩家操控,神经网络给 4 这个状态一个很高的估值,并且这个值能持续一段时间。
图 b 是 AI 玩 Pong 游戏的分析,一开始图 1 的时候,由于小球距离拍子还有段距离,所以是否移动都无所谓,这时候三个状态的估值近似。图 2 和图 3 的时候只有向上移动才能打到球,否则会输掉游戏导致负的 reward,所以这两个状态下,向上的这个动作估值最高,其他动作都会有负的估值。图 4 中虽然马上会得到一分,但是与玩家选择哪个动作无关,所以这时候三个动作的估值仍然很相近。
总结
本文采用 DQN 的方式来解决高维图像输入下游戏操控的问题。
DQN 的优点
- 算法普适性较强,一样的网络可以学习不同的游戏(针对于不同的 Atari 游戏)
- 采用端到端的训练方式,无需人工提取 Feature,用 CNN 代替 handcrafted 特征。采用固定长度的历史数据,比如 4 帧图像作为一个状态输入。解决深度学习输入长度必须固定的问题。
- 通过不断的测试训练,使用 reward 来构造标签,可以实时生成无尽的样本用于有监督训练(Supervised Learning)
- 通过 experience replay 的方法来解决相关性及非静态分布问题。即建立一个经验池,把每次的经验都存起来,要训练的时候就随机的拿出一个样本来训练。
- 动作的选择采用常规的 ϵ-greedy policy。 就是小概率选择随机动作,大概率选择最优动作。
DQN 的缺点
- 由于输入的状态是短时的,所以只适用于处理只需短时记忆的问题,无法处理需要长时间经验的问题。
- 使用 CNN 来训练不一定能够收敛,需要对网络的参数进行精良的设置才行。(比如我现在项目做目标检测,使用在imagenet训练过的模型作为作为前置网络初始化参数,这使得 CNN 使得收敛不是太难,而该论文是从无到有手动配置 CNN 的。另外 Loss 函数比较复杂。)
- 因为物理内存有限,只存储 N 个经验在经验池里,这个方法的局限性就是这个经验池并没有区分重要的转移transition,总是覆盖最新的 transition。
- 输入图片的像素还很低,如何扩展到以后复杂的游戏。
改进方向
1)使用 LSTM 或者 RNN 来增强网络记忆性。
2)改进 Q-Learning 的算法提高网络收敛能力。
3)使用优先的经验进行训练以改进性能。即有引导的经验池;物理上增加存储数据的容量 D。
4)寻找生物学上的启发。
5)CNN 模型结构的变化需要研究,比如研究全连接层是否可以被替换,以及一些在其它深度学习网络中训练的 trick 是否可以在这里使用。
参考
- [笔记]Human-level control through deep reinforcement learning
- 【论文理解】Human-level control through deep reinforcement learning(DQN)
- 论文笔记之:Human-level control through deep reinforcement learning
About

若有收获,就点个赞吧
0 人点赞
